|
React 使用虚拟 DOM 将计算好之后的更新发送到真实的 DOM 树上,减少了频繁操作真实 DOM 的时间消耗,但将成本转移到了 JavaScript 中,因为要计算新旧 DOM 树的差异嘛。所以这个计算差异的算法是否高效,就很关键了。React 中其计算差异的过程叫 Reconciliation,可理解成调和前后两次渲染的差异。
正式讨论前,先来看个问题。
问题
假设我们有一个展示百分比的柱状条组件,其宽度由是传入的数值决定。并且它带动画,如果传入的值变化,那么柱状条应该由 0 动画到需要展示的宽度。
即想要实现的效果如下:

预期的百分比柱状条效果
所以我们写了如下的柱状条组件:
function Bar({ score }) {
const [width, setWidth] = useState(0);
// 调试用
useEffect(() => {
console.log("组件初始化完成");
return () => {
console.log("组件即将销毁");
};
}, []);
useEffect(() => {
console.log("score 发生变化");
const timer = setTimeout(() => {
setWidth(score);
}, 0);
<span class="pl-k">return</span> () <span class="pl-k">=></span> {
<span class="pl-c1">clearTimeout</span>(timer);
};
}, [score]);
const style = {
width: </span><span class="pl-s1"><span class="pl-pse">${</span>width<span class="pl-pse">}</span></span>%<span class="pl-pds">
};
return (
<div className="bar-wrap'">
<div className="bar" style={style}>
{width}
</div>
</div>
);
}
因为要实现动画,所以一开始我们并不将组件接收到的值应用到样式上,而是先将宽度设置为 0,等组件完成初始化之后,再在 setTimeout 中将组件的宽度设置为传入的 props 上的值,这样就能看到动画了。
调用:
const data1 = [10, 20];
const data2 = [50, 20, 10];
function App() {
const [data, setData] = useState(data1);
return (
<div>
<button
onClick={() => {
setData(prev => (prev === data1 ? data2 : data1));
}}
>
switch data
</button>
{data.map((score, index) => {
return (
<div>
<Bar score={score} />
</div>
);
})}
</div>
);
}
实际得到的结果:

实际得到的结果
每次的动画不会从 0 开始,第二个元素根本就没有动画。通过查看打印到控制台的信息,可发现在数据发生变化后,<Bar> 组件是没有销毁的,说明该组件在 props 更新时进行了复用,这是观察到的一点线索。
你可能会说,这里应该在每次渲染前,也就是 setTimeout 之前,先重置一下数据将宽度设置为 0,这样便能得到想要实现的效果:每次都从 0 开始动画。同时,为了看清过程,不防将 setTimeout 的时间暂时加大。
useEffect(() => {
console.log("score 发生变化");
+ setWidth(0);
const timer = setTimeout(() => {
setWidth(score);
- }, 0);
+ }, 1000);
return () => {
clearTimeout(timer);
};
}, [score]);

每次动画前初始化
可以看到,并没有什么用。依然会有一个减小的动画。如果将 setTimeout 置回到 0,只是看不到这个缩减到 0 过程,而是缩减到目标值的这一过程。并且对于第二个元素,因为前后 props 并没有发生变化,连缩小的过程也没有。
React 的 diff 机制
对于树的差异检测,按照这个论文中描述的算法实现,其时间复杂度为 O(n3) 。而页面中 DOM 节点很容易上千,这样一次渲染需要 diff 的操作超过十亿,显然不可行。所以 React 在进行 diff 时作了两个假设前提:
- 如果父元素不同,其子节点产生不同的树。
- 开发者可通过为元素指定
key 来标识元素的唯一性,提高 React 差异检测时的效率。
基于这两点假设,在进行 diff 时可以少很多工作量,
- diff 过程中,如果发现原来某个位置的元素其类型变化了,则无需继续遍历其子元素,直接认为该元素连同所有子节点都需要被替换掉。
- diff 过程中,如果元素的
key 与上一次渲染时没发生变化,则判定为不需要重新渲染,进而也无需往下继续遍历其子元素。
这样假设之后,React 的 diff 算法做到了时间复杂度为 O(n)。
DOM 节点的 diff
区分为节点类型变化与没变化两种情况,
对于前后再次渲染中,同一位置元素类型变化的情况,如前文所述,对该元素及其子节点整个更新。比如由 <section> 变成 <div>,该位置的 <section> 及其所有子节点将整个销毁,其中的状态也丢弃掉,创建 <div> 及相应子元素替换在该位置。
对于类型没变的情况则比较元素的属性,得出差异后只更新相应属性,比如 className。样式有更新也只计算出变化的样式属性然后只更新该属性。
组件节点的 diff
对于自己写的组件,类型变化时同 DOM 节点一样,将整个组件实例销毁,其中各状态将丢失,所有子节点也都销毁,这些组件的 componentWillUnmount() 生命周期函数将被触发。然后实例化新类型的组件替换在该位置,新实例化的组件其 componentWillMount() 及 componentDidMount() 生命周期函数将顺次触发。
如果该位置组件类型没变,说明只需要根据变化的 props 更新组件即可,无需重新实例化新的组件。组件实例中的状态将在两次渲染中被保留复用,组件的 componentWillReceiveProps() 及 componentWillUpdate() 生命周期函数将触发。
子节点的遍历及 key 属性
上面描述了节点对比后的处理。对于节点内子节点,递归遍历时,应用相同的逻辑。考察下面的示例代码:
<ul>
<li>first</li>
<li>second</li>
</ul>
<ul>
<li>first</li>
<li>second</li>
+ <li>third</li>
</ul>
React 在遍历 <ul> 的子节点时,能够将前两个 <li> 元素匹配,保持不动,然后将新增的 <li>third</li> 附加在列表最后,完成更新。
如果新插入的元素不在列表最后,而是在最前面或中间,事情就开始发生变化。
<ul>
<li>Duke</li>
<li>Villanova</li>
</ul>
<ul>
+ <li>Connecticut</li>
<li>Duke</li>
<li>Villanova</li>
</ul>
这时 React 简单地按位置来对比更的模式就变得不那么智能了。由前文所述,
- 在进行第一个子元素
<li> 的对比时,发现其内容由 <li>Duke</li> 变为了 <li>Connecticut</li>,于是将该位置的元素更新。
- 继续对比,发现原来第二个位置的
<li>Villanova</li> 变为了 <li>Duke</li>,执行更新操作。
- 再继续发现需要新增
<li>Villanova</li> 元素。
这是 React 真实的流程,并不是我们一眼就能看出来的那个样子,只需要在列表开头插入那个新增的元素,将其他子元素保留即可。
所以,对于这样的列表类型,如果元素频繁变动,势必导致更新的效率会很低。问题的根本在于 React 不能识别前后两次渲染哪些元素其实是同一个,而是根据其在组件树中的位置来进行 diff 的。如果我们手动为元素指定一个唯一标识,这个标识在前后再次渲染时如果不变的话,这样就相当于告诉 React 它们是同一个元素,而不是按照其所在列表中的位置来进行 diff。
这便是元素身上的 key 属性。其值一定是能够唯一标识该元素的,这个唯一是指兄弟节点之间唯一即可,比如列表中同类型的列表元素。如果兄弟节点 key 重复,React 会有警告提醒。
再来看上面的示例,
<ul>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
<ul>
<li key="2014">Connecticut</li>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
通过读取元素身上的 key,再次比较时 React 能够智能地得出结论,本次更新只需要插入 <li key="2014">Connecticut</li>,剩余的其他子节点可直接复用。这样处理子节点的 diff 时效率就大大提升了。
所以你通过遍历方式生成一堆子节点时,React 会提示你需要为元素设置 key 属性。
Warning: Each child in a list should have a unique "key" prop.
默认情况下,如果没有显式指定 key,React 默认使用其在列表中的索引作为 key。但这个属性最好是来自需要渲染的数据条目的 id,这样能够最大程度地与数据保持一致,如果数据变化了,id 必然变化,则重新渲染。直接使用 for 循环中的 index 索引来做为 key 是不推荐的。因为索引不体现数据的变化,如果列表数据变化了,比如进行了排序,原来位置的数据可能不是原来的那条数据了,但因为索引没变,React 按照每个位置还是同一个元素的 diff 逻辑来处理,该位置的组件复用前一次渲染的状态,势必产生 bug。下面是一个简单展示这一问题的示例:
function Item({ name }) {
const [score, setScore] = useState();
return (
<div>
name:{name}
<input
type="text"
onChange={e => {
setScore(e.target.value);
}}
/>
score is: {score}
</div>
);
}
function App() {
const [persons, updatePersons] = useState(["tom", "david"]);
return (
<div>
<h3>set age for each person</h3>
{persons.map((name, index) => {
return <Item key={index} name={name} />;
})}
<div>
<button
onClick={() => {
updatePersons(prev => ["lily", ...prev]);
}}
>
add person
</button>
</div>
</div>
);
}
上面的示例遍历一个包含了姓名的数组,为每个人生成一行可输入分数的表单项。同时我们将每个生成项的 key 设置成索引 index。
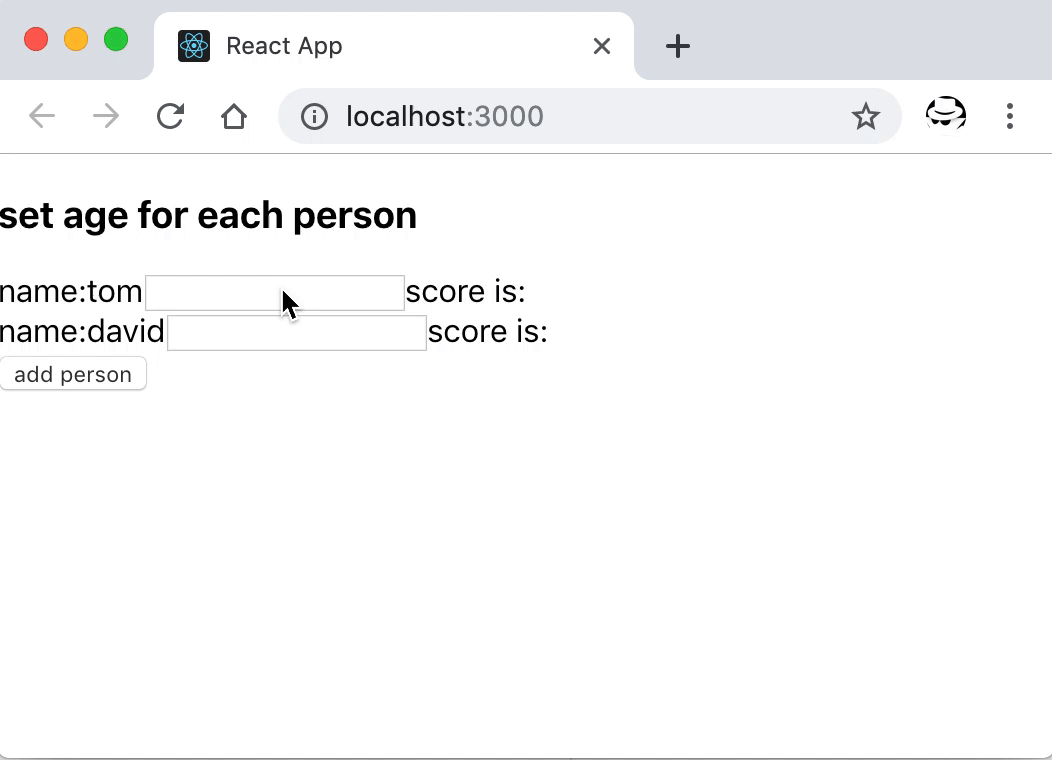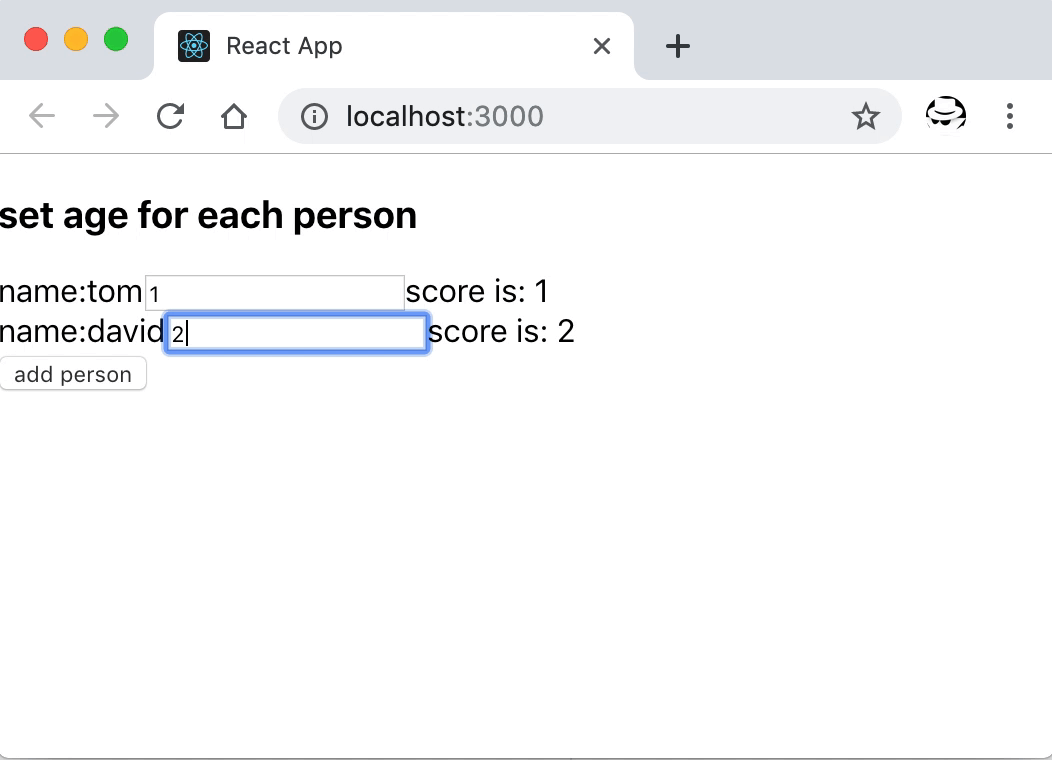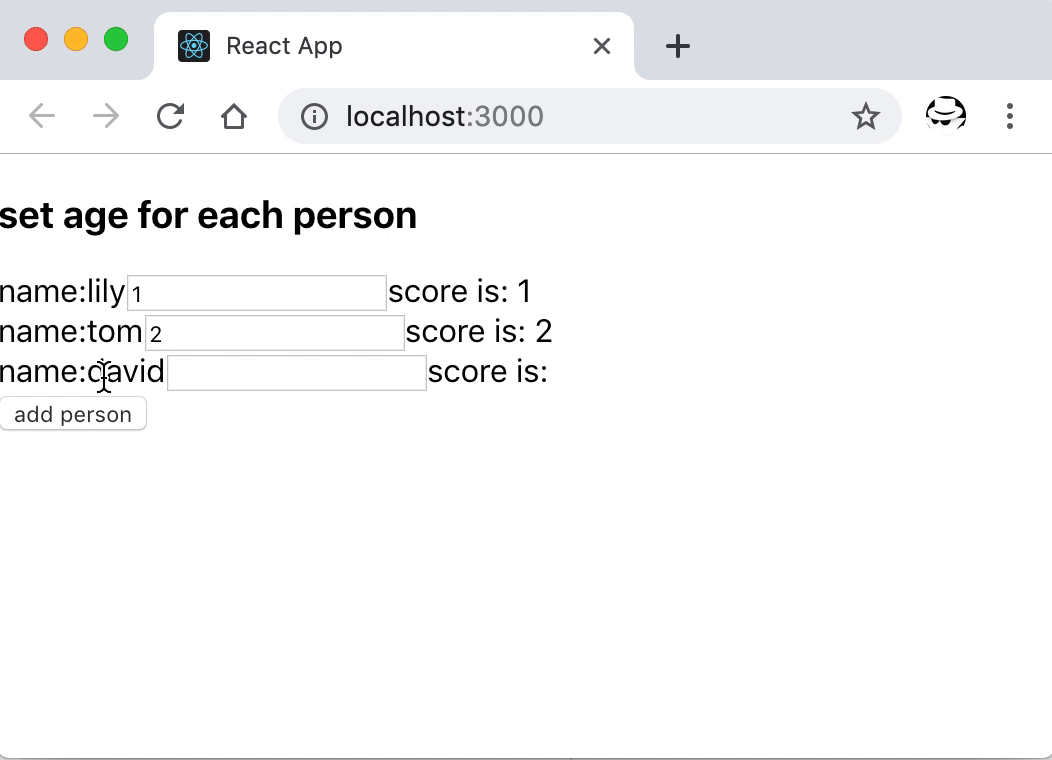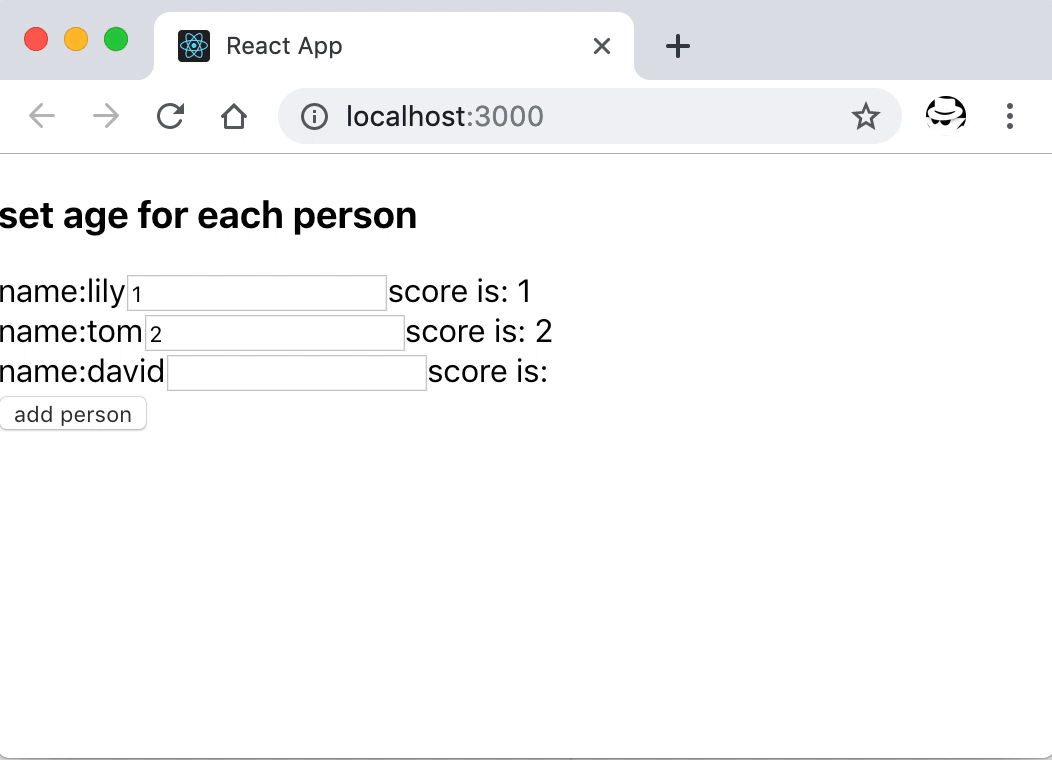
展示将 `key` 设置成索引导致组件内部状态不对的问题
可以看到,分数设置在列表中子组件中,当添加新的条目后,原来索引位置的组件复用之前的组件状态,因为该位置 key 相同,不会整个重新渲染。所以新增在第一位的 lily,本来还没有为其设置分数,但它使用了原来在那个位置的 tom 的分数,同时,其他元素因为位置变化了,他们所持有的状态都错位了。
修正 key 之后再次操作表现就正常了。
function App() {
const [persons, updatePersons] = useState(["tom", "david"]);
return (
<div>
<h3>set age for each person</h3>
{persons.map((name, index) => {
- return <Item key={index} name={name} />;
+ return <Item key={name} name={name} />;
})}
<div>
<button
onClick={() => {
updatePersons(prev => ["lily", ...prev]);
}}
>
add person
</button>
</div>
</div>
);
}
这里假设每条数据其 name 值是不一样的,所以将它作为列表元素的唯一标识。

修正 `key` 之后的正常表现
问题的解决
回到文章开头的问题,就可以理解其表现了。
const data1 = [10, 20];
const data2 = [50, 20, 10];
默认情况下,React 使用 index 作为 key。
- 对于第一条数据,其值由 10 变化到 50,动画正常,当再次设置时,其由 50 变回到 10。因为组件并没有重新初始化,所以其初始值确实是 50,所以看到了由 50 到 10 这个缩减的动画。
- 而对于第二条数据,因为前后值没变化,执行动画的
setTimeout 都不会执行。
修正的方法可以为元素指定一个随机的 key,这样每次组件都会重新渲染,不会复用之前的状态。
function App() {
const [data, setData] = useState(data1);
return (
<div>
<button
onClick={() => {
setData(prev => (prev === data1 ? data2 : data1));
}}
>
switch data
</button>
{data.map((score, index) => {
return (
- <div>
+ <div key={Math.random()}>
<Bar score={score} />
</div>
);
})}
</div>
);
}
修正后的百分比柱状条效果
将 key 设置成随机值是不推荐的做法,因为这样 React 就没法在渲染过程中对组件进行重用的优化。但像这里的特殊情况,你需要知道的是其中的原理,然后清楚自己在这样做时的影响。
总结
虚拟 DOM 将操作浏览器 DOM 的成本一部分转嫁到了 JavaScript 中,即进行差异计算的成本。提高了渲染的效率,但某些情况下也会是一个坑。
需要注意的是,React 的差异算法高效性是在两个假设前提下进行的,
- 如果父元素不同,其子节点产生不同的树。
- 开发者可通过为元素指定
key 来标识元素的唯一性,提高 React 差异检测时的效率。
相关资源
|