【TensorFlow篇】--Tensorflow框架初始,实现机器学习中多元线性回归
2024-10-19 07:37:22
一、前述
TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow为张量从流图的一端流动到另一端计算过程。TensorFlow是将复杂的数据结构传输至人工智能神经网中进行分析和处理过程的系统。
二、相关概念和安装
TensorFlow中的计算可以表示为一个有向图(DirectedGraph)
或者称计算图(ComputationGraph)
其中每一个运算操作(operation)将作为一个节点(node)
计算图描述了数据的计算流程,也负责维护和更新状态
用户通过python,C++,go,Java语言设计这个这个数据计算的有向图
计算图中每一个节点可以有任意多个输入和任意多个输出
每一个节点描述了一种运算操作,节点可以算是运算操作的实例化(instance)
计算图中的边里面流动(flow)的数据被称为张量(tensor),故得名TensorFlow
安装流程:
pip install tensorflow==1.1.0
三、代码规范
详细源码在本人github上https://github.com/LhWorld/AI_Project.git
代码一:tensorflow 基本语法
import tensorflow as tf x = tf.Variable(3, name='x') #Variable创建一个变量
y = tf.Variable(4, name='y')
f = x*x*y + y + 2 # 可以不分别对每个变量去进行初始化
# 并不立即初始化,在run运行的时候才初始化
init = tf.global_variables_initializer() with tf.Session() as sess:
init.run()
result = f.eval()
print(result)
代码二:Variable的声明周期
import tensorflow as tf # 当去计算一个节点的时候,TensorFlow自动计算它依赖的一组节点,并且首先计算依赖的节点
w = tf.constant(3)
x = w + 2
y = x + 5
z = x * 3 with tf.Session() as sess:
print(y.eval())
# 这里为了去计算z,又重新计算了x和w,除了Variable值,tf是不会缓存其他比如contant等的值的
# 一个Variable的生命周期是当它的initializer运行的时候开始,到会话session close的时候结束
print(z.eval()) # 如果我们想要有效的计算y和z,并且又不重复计算w和x两次,我们必须要求TensorFlow计算y和z在一个图里
with tf.Session() as sess:
y_val, z_val = sess.run([y, z])
print(y_val)
print(z_val)
代码三:Tensorflow手动实现多元线性回归中解析解求解过程
import tensorflow as tf
import numpy as np
from sklearn.datasets import fetch_california_housing # 立刻下载数据集
housing = fetch_california_housing()
print(housing)
# 获得X数据行数和列数
m, n = housing.data.shape
# 这里添加一个额外的bias输入特征(x0=1)到所有的训练数据上面,因为使用的numpy所有会立即执行
housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]#np.c_整合combine np.ones((m, 1)是x0=1这一列
#以上代码会立即执行 因为不是tf的函数
# 创建两个TensorFlow常量节点X和y,去持有数据和标签
X = tf.constant(housing_data_plus_bias, dtype=tf.float32, name='X')#延迟执行,只是做了一下标记
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name='y')#reshape(-1,1)把行向量转变成列向量 -1代表随便行 不限制行数 最终m行一列
#以上y是真实的数据
# 使用一些TensorFlow框架提供的矩阵操作去求theta
XT = tf.transpose(X)
# 解析解一步计算出最优解
theta = tf.matmul(tf.matmul(tf.matrix_inverse(tf.matmul(XT, X)), XT), y)#解析解公式
with tf.Session() as sess:
theta_value = theta.eval() # 与sess.run(theta)等价 theta相当于一个图通过DAG构建
print(theta_value)
代码四:Tensorflow手动实现多元线性回归中梯度下降求解过程
import tensorflow as tf
import numpy as np
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import StandardScaler #多元线性回归是一个凸函数 ,所以能找到全局最优解
#神经网络只有局部最优解
n_epochs = 1000#把样本集数据学习1000次
learning_rate = 0.01 #步长 学习率 不能太大 太大容易来回震荡 太小 耗时间,跳不出局部最优解
#可以写learn_rate动态变化,随着迭代次数越来越大 ,学习率越来越小 learning_rate/n_epoches
housing = fetch_california_housing()
m, n = housing.data.shape
housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]
# 可以使用TensorFlow或者Numpy或者sklearn的StandardScaler去进行归一化
#归一化可以最快的找到最优解
#常用的归一化方式:
# 最大最小值归一化 (x-min)/(max-min)
# 方差归一化 x/方差
# 均值归一化 x-均值 结果有正有负 可以使调整时的速度越来越快。
scaler = StandardScaler().fit(housing_data_plus_bias) #创建一个归一化对象
scaled_housing_data_plus_bias = scaler.transform(housing_data_plus_bias) #真正执行 因为来源于sklearn所以会直接执行,不会延迟。 X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name='X')
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name='y') # random_uniform函数创建图里一个节点包含随机数值,给定它的形状和取值范围,就像numpy里面rand()函数
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0), name='theta') #theta是参数 W0-Wn 一列 按照-1.0到1.0随机给
y_pred = tf.matmul(X, theta, name="predictions")#相乘 m行一列
error = y_pred - y #列向量和列向量相减 是一组数
mse = tf.reduce_mean(tf.square(error), name="mse")#误差平方加和,最小二乘 平方均值损失函数 手动实现
# 梯度的公式:(y_pred - y) * xj i代表行 j代表列
gradients = 2/m * tf.matmul(tf.transpose(X), error)#矩阵和向量相乘会得到新的向量 一组梯度
# 赋值函数对于BGD来说就是 theta_new = theta - (learning_rate * gradients)
training_op = tf.assign(theta, theta - learning_rate * gradients)#assigin赋值 算一组w
# training_op实际上就是需要迭代的公式 init = tf.global_variables_initializer() with tf.Session() as sess:
sess.run(init) #初始化 for epoch in range(n_epochs):#迭代1000次
if epoch % 100 == 0:
print("Epoch", epoch, "MSE = ", mse.eval())#每运行100次的时候输出
sess.run(training_op) best_theta = theta.eval()#最后的w参数值
print(best_theta)
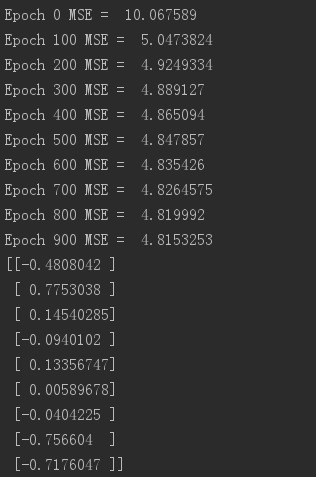
通过Tensorflow运行机器学习可以实现分布式运算,提高速度。
代码五:使用tensorflow本身API实现
import tensorflow as tf
import numpy as np
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import StandardScaler # TensorFlow为我们去计算梯度,但是同时也给了我们更方便的求解方式
# 它提供给我们与众不同的,有创意的一些优化器,包括梯度下降优化器
# 替换前面代码相应的行,并且一切工作正常 n_epochs = 1000
learning_rate = 0.01 housing = fetch_california_housing()
m, n = housing.data.shape
housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]
# 可以使用TensorFlow或者Numpy或者sklearn的StandardScaler去进行归一化
scaler = StandardScaler().fit(housing_data_plus_bias)
scaled_housing_data_plus_bias = scaler.transform(housing_data_plus_bias) X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name='X')
y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, name='y') # random_uniform函数创建图里一个节点包含随机数值,给定它的形状和取值范围,就像numpy里面rand()函数
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0), name='theta')
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
# 梯度的公式:(y_pred - y) * xj
# gradients = 2/m * tf.matmul(tf.transpose(X), error)
# gradients = tf.gradients(mse, [theta])[0]
# 赋值函数对于BGD来说就是 theta_new = theta - (learning_rate * gradients)
# training_op = tf.assign(theta, theta - learning_rate * gradients) optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
# MomentumOptimizer收敛会比梯度下降更快
# optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=0.9)
training_op = optimizer.minimize(mse)#去减小误差 init = tf.global_variables_initializer() with tf.Session() as sess:
sess.run(init) for epoch in range(n_epochs):
if epoch % 100 == 0:
print("Epoch", epoch, "MSE = ", mse.eval())
sess.run(training_op) best_theta = theta.eval()
print(best_theta)
代码六:placeholder的使用
import tensorflow as tf # 让我们修改前面的代码去实现Mini-Batch梯度下降
# 为了去实现这个,我们需要一种方式去取代X和y在每一次迭代中,使用一小批数据
# 最简单的方式去做到这个是去使用placeholder节点
# 这些节点特点是它们不真正的计算,它们只是在执行过程中你要它们输出数据的时候去输出数据
# 它们会传输训练数据给TensorFlow在训练的时候
# 如果在运行过程中你不给它们指定数据,你会得到一个异常 # 需要做的是使用placeholder()并且给输出的tensor指定数据类型,也可以选择指定形状
# 如果你指定None对于某一个维度,它的意思代表任意大小
A = tf.placeholder(tf.float32, shape=(None, 3))
B = A + 5 with tf.Session() as sess:
B_val_1 = B.eval(feed_dict={A: [[1, 2, 3]]})#等价于session.run(B)一行数据三个维度
B_val_2 = B.eval(feed_dict={A: [[4, 5, 6], [7, 8, 9]]})#两行数据,三个维度 print(B_val_1)
print(B_val_2)
最新文章
- 三种常用的MySQL建表语句(转)
- spring源码分析(一)IoC、DI
- HDU 5907 Find Q(简单字符串)
- Mac系统下使用VirtualBox虚拟机安装win7--第三步 在虚拟机上安装 Windows 7
- windows Android开发环境快速搭建和部署
- winform - BackgroundWorker
- String 两种实例化方式的区别
- windows下python安装paramiko
- 正确决解Hibernate4.*中:Connection cannot be null when 'hibernate.dialect' not set
- C# List<T>中Select List Distinct()去重复
- java流下载
- java微信公众号开发token验证失败的问题及解决办法
- [2]十道算法题【Java实现】
- Clion+Cmake+Qt5+Qwt+msys2+MinGW在Windows下的安装配置使用教程
- JS求数组差集的几种方法
- 自动化测试-4.selenium的xpath定位
- 1.Python爬虫入门一之综述
- STL::set/multiset
- 第二阶段Sprint10
- TP 模板的变量输出