redis的缓存穿透、击穿、雪崩以及实用解决方案
今天来聊聊redis的缓存穿透、击穿、雪崩以及解决方案,其中解决方案包括类似于布隆过滤器这种网上一搜一大片但是实际生产部署有一定复杂度的,也有基于spring注解通过一行代码就能解决的,其中各有优劣,咱们根据实际需要选型;
接下来会从穿透、击穿、雪崩的基本概念、各种问题对应的解决方案以及方案的具体实施来一一介绍
缓存穿透
概念
- 缓存穿透指某一特定时间批量请求打进来并访问了缓存和数据库都没有的key,此时会直接穿透缓存直达数据库,从而造成数据库瞬时压力倍增导致响应速度下降甚至崩溃的风险;
解决方案
一、通过布隆过滤器解决
原理:将所有需要缓存的key通过hash算法全部放到布隆过滤器将对应下标对应的值置成1,这样当请求进来时先去布隆过滤器里找,发现对应index的key是1则去缓存拿数据为0则直接返回,这样就避免了去数据库查询
优缺点:布隆过滤器底层通过redis的bitMap实现是基于位的操作,所以效率高;但是需要提前将key存入过滤器,这大大增加了前置成本;并且key到index的映射通过hash算法,那么必然会出现hash碰撞的问题;
二、通过key-null
- 原理:当请求进来从数据库查询回来的值为空时,将对应的null值也存入redis,这样下次请求时redis里已经有数据了就不会再怼到数据库了
- 优缺点:思路清晰,操作简单,但是极端情况下会有N多key在数据库和缓存中都没有,那这种实现就造成了redis里有过多的垃圾数据,浪费了内存空间
三、增强前置判断
- 原理:查询前在接口层做权限、逻辑校验,尽可能多的判断key的合法性
- 优缺点:使用成本低但并不足以规避掉缓存穿透的风险,所以建议只做附加的解决方案使用
缓存击穿
概念
- 缓存击穿指某一特定时间批量请求打进来对一个特定的值进行查询并访问了缓存中没有但是数据库里存在的key,此时会直接击穿缓存直达数据库,从而造成数据库瞬时压力倍增导致响应速度下降甚至崩溃的风险;需要注意的是,这里说的缓存中没有包含两层意思,一是缓存中本身没有,二十缓存中有但是过期了(少量热点key过期)
解决方案
一、设置key的过期时间随机
- 原理:在像redis批量设置key的时候尽量做到过期时间的随机性,以此避免某一时间会有批量key过期导致的缓存击穿
- 优缺点:虽然解决了缓存中同一时间批量key过期导致的击穿问题但是并不能解决缓存中压根就不存在key而造成的击穿
二、通过分布式锁解决
- 原理:在查询数据库的时候加一个分布式锁,使得某一特定时间内只有一个请求访问数据库,访问成功后将查询到的值缓存近redis,这样在下次访问时就不会造成击穿的现象了;
需要注意的是,针对非海量请求的业务这里加单机锁也问题不大,无非就是将同一时间只有一个请求到数据改成了同一时间只有集群数量的请求到数据库,问题应该也不大
- 优缺点:无论是缓存中本身就没有还是缓存中的key过期了使用加锁的方式都能解决缓存击穿的问题,但是却增加了加锁的成本
三、设置热点key永不过期
- 原理:针对热点key批量过期造成的穿透问题,将key设置成永不过期就能解决
- 优缺点:与一一样只能解决key过期造成的击穿不能解决缓存中没有key造成的击穿,并且热点key的确认也是门学问,并不总能保证设置的热点key不遗漏
四、将key部署在不同的实例
- 原理:针对集群部署的redis,将热点key分开部署也能避免过期造成的击穿问题
- 优缺点:只有集群才能使用,且也只能解决key过期造成的击穿问题,并不总能保证设置的热点key不遗漏
缓存雪崩
概念
- 与击穿相比雪崩表示过期或压根不存在的key是大量而不是一个或少量,导致大量请求落到数据库;
解决方案
一、通过设置过期时间随机来解决
- 设置key的时候加上随机过期时间,尽量减少同一时间过期key的数量;
二、设置锁
- 从缓存访问key开始就加锁,当缓存没有则去数据库查,查完塞入缓存最后释放锁;如果是单机应用则直接加虚拟机锁,集群部署的话则需使用分布式锁
小结
以上的实现方案可根据自己的业务需求灵活实现,其中个人认为布隆过滤器的落地相对复杂,成本也会更高,所以我们实际工作中并没有使用,而是用了基于spring-cache的@Cacheable注解,某种程度上可以说是一行代码解决了缓存击穿、穿透问题,下面说下@Cacheable注解
@Cacheable注解
一、介绍
- @Cacheable注解是一个spring3.1后引入的缓存技术,可通过在业务代码添加spring的缓存注解来实现缓存对象和方法的效果;而不用在业务代码里显示的进行set操作,大大方便了我们的日常开发
二、使用
- 1、在springboot的启动类添加
@EnableCaching注解开启缓存,否则下面的注解不会生效 - 2、直接上图,结合图来说明则一清二楚
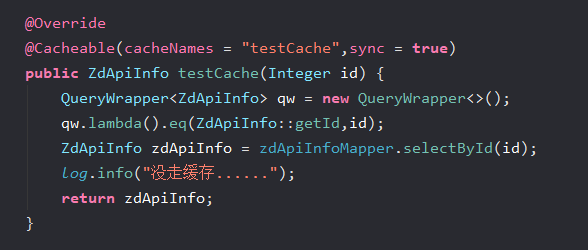
说明
1、通过在方法上添加@Cacheable注解表示此方法需要走缓存,其中cacheNames的值加上方法的入参为唯一标识作为缓存中的key,而value则为方法的返回值;需要注意的是,当方法的入参和返回值是对象时则需要实现序列化(Serializable)接口
2、sync参数默认缺省值为false,表示是否是一个线程去数据库查询;所以当值为true时表示只有一个线程会打到数据库,这就解决了缓存击穿的问题;而针对缓存穿透,之前看到资料说需要添加spring.cache.redis.cache-null-values=true的配置才可以缓存空值,但我通过测试发现不论方法返回值是对象还是普通类型空值均可被缓存,我使用的spring版本是5.3.12;所以上面的代码也顺带解决了缓存穿透的问题
3、如果项目并发量小,不需要考虑穿透、击穿这些问题,可以直接写成@Cacheable("testCache")使sync缺省即可
三、总结
- 个人认为,针对@Cacheable已经足以解决实际开发中穿透、击穿的问题了;当然,如果假设一个集群有10000个实例,使用sync理论上也会有10000个请求同时抵达数据库从而影响数据库性能甚至崩溃,但是这种情况被我们碰到的情况很少,甚至可以说接触不到;但是如果真接触到了只能通过添加分布式锁去解决了
最新文章
- redisTemplate的spring配置以及lua脚本驱动
- Oracle基础表空间建立,以及练习
- 【原/转】UITableview性能优化总结
- Servlet技术
- user is not mapped
- C#语法糖之第二篇: 参数默认值和命名参数 对象初始化器与集合初始化器
- HDOJ 2012 素数判定
- 动态树LCT小结
- 自己写的轻量级PHP框架trig与laravel5.1,yii2性能对比
- Android Studido下的应用性能优化总结--布局优化
- poptest老李谈分布式与集群
- app请求服务器数据方法1-HttpUrlConnection
- golang 轮训加密算法
- openlayer3相关扩展
- SpringBoot系列: Json的序列化和反序列化
- UVa 679 - Dropping Balls【二叉树】【思维题】
- python自动化测试入门篇-jemter连接mysql数据库
- php后台对接ios,安卓,API接口设计和实践完全攻略,涨薪必备技能
- 这几道Java集合框架面试题几乎必问
- Silverlight子窗口(ChildWindow)传递参数到父窗口演示