MySql创建高性能的索引
创建高性能的索引
1.树 减少数据的查询次数
二叉树
平衡树
b树 节点存储key和data
b+树 节点只存储key 叶子节点存储data
innodb使用b+树 当页最大16kb可以存储1000个key
myisam使用b+树 存储的是文件地址
2.索引
优点:减少表扫描 避免排序和临时表 随机io变有序io
单索引 where
复合索引 where
文本索引 match
全值匹配
复合索引优于单索引,过多索引对insert/delete需要消耗更多的资源维护索引.
最左匹配原则 复合索引
https://blog.csdn.net/w13346019869/article/details/123413536
匹配列前戳
匹配范围值
explain sql分析
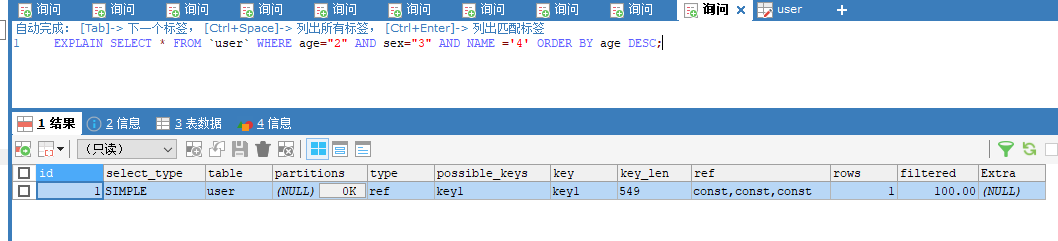
https://blog.csdn.net/asd051377305/article/details/113979657
索引合并:两个单列索引进行扫描,并将结果进行合并。这种算法有三个变种:OR条件的联合(union),AND条件的相交(intersection),组合前两种情况的联合及相交。
如果在EXPLAIN中看到有索引合并,那么就应该好好检查一下查询语句的写法和表的结构,看是不是已经是最优的。也可以通过参数optimizer_switch来关闭索引合并功能,还可以使用IGNORE INDEX语法让优化器强制忽略掉某些索引,从而避免优化器使用包含索引合并的执行计划。
索引会导致大数据量插入变慢,插入后OPTIMIZE TABLE 重建索引.
覆盖索引 b+树叶子节点存有值,不用从表内获取.
使用索引扫描来做排序:索引的顺序和ORDER BY子句的顺序完全一致,联接多张表,则只有当ORDER BY子句引用的字段全部在第一个表中时,才能使用索引做排序。
在选择索引和编写利用这些索引的查询时,有如下三个原则始终需要记住:
● 单行访问是很慢的,特别是在机械硬盘中存储(SSD的随机I/O要快很多,不过这一点仍然成立)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多的所需要的行。
● 按顺序访问范围数据是很快的,有两个原因。第一,顺序I/O不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对于机械硬盘)。第二,如果服务器能够按需顺序读取数据,那么就不再需要额外的排序操作,并且GROUP BY查询也无须再做排序和将行按组进行聚合计算了。
● 索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就不需要再回表查找行。这避免了大量的单行访问,而上面的第一点已经写明单行访问是很慢的。
最新文章
- 【月入41万】Mono For Android中使用百度地图SDK
- 初次使用并安装express
- Linux 查看磁盘空间大小
- Kali Linux 安装教程-转
- IPC——匿名管道
- st_mode 的位定义
- Chrome rem bug
- C#遍历Object各个属性含List泛型嵌套。
- Ubuntu14.04如何备份和恢复系统
- c#中 ==与equals有什么区别
- Angular 2的12个经典面试问题汇总(文末附带Angular测试)
- Linux配置LNMP环境(一)配置Nginx
- MPLS LDP随堂笔记1
- xampp使用中mysql端口被占用问题的解决方案
- C. Neko does Maths
- Flask 系列之 部署发布
- 在jsp中如何使用javax.servlet.http.HttpServlet,javax.servlet.GenericServlet, javax.servlet.Servlet
- application.properties详解 --springBoot配置文件【转载】
- vue.js学习资料
- openvpn路由配置