Python网络爬虫练习
1. 豆瓣top250电影
1.1 查看网页
目标网址:https://movie.douban.com/top250?start=0&filter=
start=后面的数字从0,25,50一直到225,共10页,每页25条信息
页面截图:
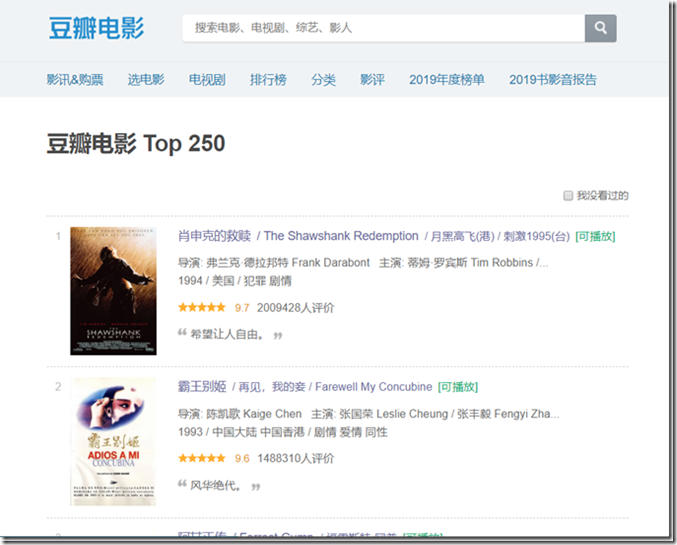
由此主页面获取各个电影的链接,然后分别跳转至对应对应的链接爬取信息。
主页面源码:
<li>
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img width="100" alt="肖申克的救赎" src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a> <span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br> / 美国 / 犯罪 剧情
</p> <div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span property="v:best" content="10.0"></span>
<span>2009428人评价</span>
</div> <p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
</li>
可以看到,链接藏在<div class="hd">中。
然后我们跳转到第一个电影(肖申克的救赎)页面,查看待爬取信息所在的位置。
1. 基本信息
片名:
<h1>
<span property="v:itemreviewed">肖申克的救赎 The Shawshank Redemption</span>
<span class="year">(1994)</span>
</h1>
其他信息:
<div id="info">
<span ><span class='pl'>导演</span>: <span class='attrs'><a href="/celebrity/1047973/" rel="v:directedBy">弗兰克·德拉邦特</a></span></span><br/>
<span ><span class='pl'>编剧</span>: <span class='attrs'><a href="/celebrity/1047973/">弗兰克·德拉邦特</a> / <a href="/celebrity/1049547/">斯蒂芬·金</a></span></span><br/>
<span class="actor"><span class='pl'>主演</span>: <span class='attrs'><a href="/celebrity/1054521/" rel="v:starring">蒂姆·罗宾斯</a> / <a href="/celebrity/1054534/" rel="v:starring">摩根·弗里曼</a> / <a href="/celebrity/1041179/" rel="v:starring">鲍勃·冈顿</a> / <a href="/celebrity/1000095/" rel="v:starring">威廉姆·赛德勒</a> / <a href="/celebrity/1013817/" rel="v:starring">克兰西·布朗</a> / <a href="/celebrity/1010612/" rel="v:starring">吉尔·贝罗斯</a> / <a href="/celebrity/1054892/" rel="v:starring">马克·罗斯顿</a> / <a href="/celebrity/1027897/" rel="v:starring">詹姆斯·惠特摩</a> / <a href="/celebrity/1087302/" rel="v:starring">杰弗里·德曼</a> / <a href="/celebrity/1074035/" rel="v:starring">拉里·布兰登伯格</a> / <a href="/celebrity/1099030/" rel="v:starring">尼尔·吉恩托利</a> / <a href="/celebrity/1343305/" rel="v:starring">布赖恩·利比</a> / <a href="/celebrity/1048222/" rel="v:starring">大卫·普罗瓦尔</a> / <a href="/celebrity/1343306/" rel="v:starring">约瑟夫·劳格诺</a> / <a href="/celebrity/1315528/" rel="v:starring">祖德·塞克利拉</a> / <a href="/celebrity/1014040/" rel="v:starring">保罗·麦克兰尼</a> / <a href="/celebrity/1390795/" rel="v:starring">芮妮·布莱恩</a> / <a href="/celebrity/1083603/" rel="v:starring">阿方索·弗里曼</a> / <a href="/celebrity/1330490/" rel="v:starring">V·J·福斯特</a> / <a href="/celebrity/1000635/" rel="v:starring">弗兰克·梅德拉诺</a> / <a href="/celebrity/1390797/" rel="v:starring">马克·迈尔斯</a> / <a href="/celebrity/1150160/" rel="v:starring">尼尔·萨默斯</a> / <a href="/celebrity/1048233/" rel="v:starring">耐德·巴拉米</a> / <a href="/celebrity/1000721/" rel="v:starring">布赖恩·戴拉特</a> / <a href="/celebrity/1333685/" rel="v:starring">唐·麦克马纳斯</a></span></span><br/>
<span class="pl">类型:</span> <span property="v:genre">剧情</span> / <span property="v:genre">犯罪</span><br/> <span class="pl">制片国家/地区:</span> 美国<br/>
<span class="pl">语言:</span> 英语<br/>
<span class="pl">上映日期:</span> <span property="v:initialReleaseDate" content="1994-09-10(多伦多电影节)">1994-09-10(多伦多电影节)</span> / <span property="v:initialReleaseDate" content="1994-10-14(美国)">1994-10-14(美国)</span><br/>
<span class="pl">片长:</span> <span property="v:runtime" content="142">142分钟</span><br/>
<span class="pl">又名:</span> 月黑高飞(港) / 刺激1995(台) / 地狱诺言 / 铁窗岁月 / 消香克的救赎<br/>
<span class="pl">IMDb链接:</span> <a href="https://www.imdb.com/title/tt0111161" target="_blank" rel="nofollow">tt0111161</a><br> </div>
可以看到,该部分内容中包含了导演、编剧、主演、类型、制片国家/地区、语言、上映日期、片长、又名这些信息,它们以分隔符<br/>进行分隔,下面我们将通过正则表达式进行提取。
2. 评分信息
<div class="ratings-on-weight">
<div class="item">
<span class="stars5 starstop" title="力荐">
5星
</span>
<div class="power" style="width:64px"></div>
<span class="rating_per">85.1%</span>
<br />
</div>
<div class="item">
<span class="stars4 starstop" title="推荐">
4星
</span>
<div class="power" style="width:10px"></div>
<span class="rating_per">13.4%</span>
<br />
</div>
<div class="item">
<span class="stars3 starstop" title="还行">
3星
</span>
<div class="power" style="width:0px"></div>
<span class="rating_per">1.3%</span>
<br />
</div>
<div class="item">
<span class="stars2 starstop" title="较差">
2星
</span>
<div class="power" style="width:0px"></div>
<span class="rating_per">0.1%</span>
<br />
</div>
<div class="item">
<span class="stars1 starstop" title="很差">
1星
</span>
<div class="power" style="width:0px"></div>
<span class="rating_per">0.1%</span>
<br />
</div>
</div>
这部分源码包含了评分5星至1星所占的百分数比例。
3. 影片简介
<div class="related-info" style="margin-bottom:-10px;">
<a name="intro"></a> <h2>
<i class="">肖申克的救赎的剧情简介</i>
· · · · · ·
</h2> <div class="indent" id="link-report"> <span class="short">
<span property="v:summary">
20世纪40年代末,小有成就的青年银行家安迪(蒂姆·罗宾斯 Tim Robbins 饰)因涉嫌杀害妻子及她的情人而锒铛入狱。在这座名为肖申克的监狱内,希望似乎虚无缥缈,终身监禁的惩罚无疑注定了安迪接下来灰暗绝望的人生。未过多久,安迪尝试接近囚犯中颇有声望的瑞德(摩根·弗里曼 Morgan Freeman 饰),请求对方帮自己搞来小锤子。以此为契机,二人逐渐熟稔,安迪也仿佛在鱼龙混杂、罪恶横生、黑白混淆的牢狱中找到属于自己的求生之道。他利用自身的专业知识,帮助监狱管理层逃税、洗黑钱,同时凭借与瑞德的交往在犯人中间也渐渐受到礼遇。表面看来,他已如瑞德那样对那堵高墙从憎恨转变为处之泰然,但是对自由的渴望仍促使他朝着心中的希望和目标前进。而关于其罪行的真相,似乎更使这一切朝前推进了一步……
<br />
本片根据著名作家斯蒂芬·金(Stephen Edwin King)的...
</span>
<a href="javascript:void(0)" class="j a_show_full">(展开全部)</a>
</span>
<span class="all hidden">
20世纪40年代末,小有成就的青年银行家安迪(蒂姆·罗宾斯 Tim Robbins 饰)因涉嫌杀害妻子及她的情人而锒铛入狱。在这座名为肖申克的监狱内,希望似乎虚无缥缈,终身监禁的惩罚无疑注定了安迪接下来灰暗绝望的人生。未过多久,安迪尝试接近囚犯中颇有声望的瑞德(摩根·弗里曼 Morgan Freeman 饰),请求对方帮自己搞来小锤子。以此为契机,二人逐渐熟稔,安迪也仿佛在鱼龙混杂、罪恶横生、黑白混淆的牢狱中找到属于自己的求生之道。他利用自身的专业知识,帮助监狱管理层逃税、洗黑钱,同时凭借与瑞德的交往在犯人中间也渐渐受到礼遇。表面看来,他已如瑞德那样对那堵高墙从憎恨转变为处之泰然,但是对自由的渴望仍促使他朝着心中的希望和目标前进。而关于其罪行的真相,似乎更使这一切朝前推进了一步……
<br />
本片根据著名作家斯蒂芬·金(Stephen Edwin King)的原著改编。
</span>
<span class="pl"><a href="https://movie.douban.com/help/movie#t0-qs">©豆瓣</a></span>
</div>
</div>
在影片简介较长时,全部信息在class属性为"all hidden"的span中,而简介较短时,不存在这一标签,property属性为"x:summary"的span中就已包含了全部文本。
1.2 爬虫代码
from urllib.request import urlopen, Request
from bs4 import BeautifulSoup
import re
import numpy as np
import pandas as pd
import time #设置请求头
headers = {'User-Agent':'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)'} def getLinks(articleUrl):
"""通过页面获取各个电影的链接"""
req = Request(url=articleUrl, headers=headers)
html = urlopen(req)
bsObj = BeautifulSoup(html)
links = bsObj.findAll("div", {"class": "hd"})
return [link.a.attrs["href"] for link in links] #目标链接
head = "https://movie.douban.com/top250?start="
pages = [head + str(num) + "&filter=" for num in np.arange(0,250,25)]
links = []
for page in pages:
#拼接所有链接,共250条
links += getLinks(page) def Merge(dict1, dict2):
"""合并字典"""
res = {**dict1, **dict2}
return res
allInfo = pd.DataFrame()
keyList1 = ['导演', '编剧', '主演', '类型', '制片国家/地区',
'语言', '上映日期', '片长', '又名']
keyList2 = ['5星', '4星', '3星', '2星', '1星']
def getInfo(articleUrl):
"""获取每部电影的详细信息"""
global allInfo
req = Request(url=articleUrl, headers=headers)
html = urlopen(req)
bsObj = BeautifulSoup(html)
#获取基础信息info1
info1 = bsObj.find("div", {"id": "info"})
info1 = info1.get_text().split('\n')[1:-2]
#通过正则表达式删选信息
#贪婪匹配+?,无匹配生成空字符串|$
pattern1 = re.compile(".+?(?=:)|$")
pattern2 = re.compile("(?<=:).+|$")
keyList_prepare = [pattern1.findall(i)[0] for i in info1]
valueList_prepare = [pattern2.findall(i)[0] for i in info1]
valueList1=[None] * len(keyList1) for key in keyList1:
if key in keyList_prepare:
valueList1[keyList1.index(key)] = valueList_prepare[keyList_prepare.index(key)]
dict1 = dict(zip(keyList1,valueList1))
#获取评分信息info2
info2 = bsObj.find("div", {"class": "ratings-on-weight"})
info2 = info2.findAll("span", {"class", "rating_per"})
valueList2 = [i.get_text() for i in info2]
dict2 = dict(zip(keyList2, valueList2))
dictAll = Merge(dict1, dict2)
#获取影片简介
try:
dictAll = Merge(dictAll, {"简介": bsObj.find("span", {"class": "all hidden"}).get_text().strip()})
except:
dictAll = Merge(dictAll, {"简介": bsObj.find("span", {"property": "v:summary"}).get_text().strip()})
allInfo = allInfo.append(dictAll,ignore_index=True)
#返回影片片名
return bsObj.h1.get_text().strip() num = 0
title = []
startTime = time.time()
for link in links:
title.append(getInfo(link))
num += 1
print("正在爬取第", num, "条信息")
endTime = time.time()
#片名作为索引
allInfo.rename(index=dict(zip(range(0,allInfo.shape[0]),title)),inplace=True)
#数据框写入CSV文件
allInfo.to_excel('MovieInfo.xlsx', encoding="utf-8")
print("共爬取", allInfo.shape[0], "条信息,用时", endTime-startTime, "秒")
1.3 部分说明
- 对于豆瓣的爬虫,需要设置请求头,否则访问行为会被拒绝,发生HTTPError;
- 共10个页面分别爬取,所以采用了字符串相加生成列表存放这10个页面的URL;
- links存放250个电影页面的URL,列表合并直接用加号就行,links += getLinks(page);
- 学习了字典合并的方法,def Merge(dict1, dict2);
- 复习了正则表达式,贪婪匹配+?,有时匹配失败会得到空列表,再引用元素[0]会报错,使用|$可在无匹配时生成空字符串,避免错误;
- 由于某些影片缺失部分信息或多出部分信息,所以需要以目标信息keyList1中元素进行筛选;
- 由列表生成字典的方法,dict(zip(list1,list1));
- 由字典向数据框添加行的方法,allInfo = allInfo.append(dictAll,ignore_index=True);
- 由于爬虫程序执行时间较长,使用了time.time()的方法进行计时;
- 最后采用.to_excel方法将数据框写入Excel文件中。
1.4 结果展示
耐心等待后……
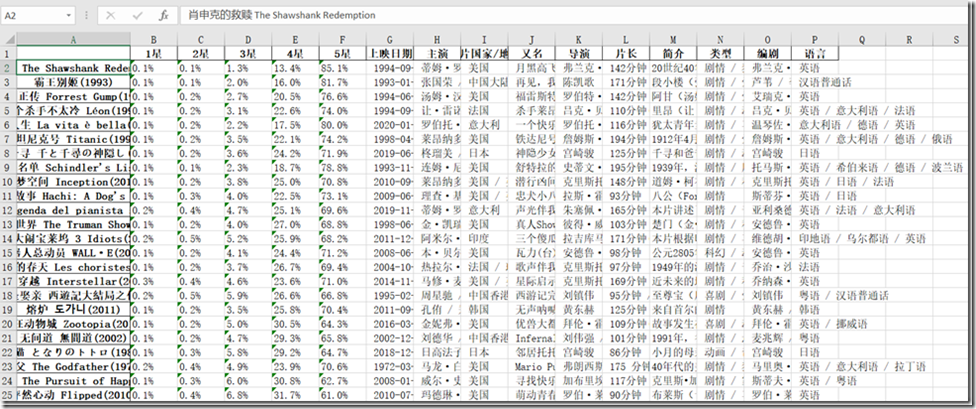
打开Excel文件查看:
2. Scrapy爬取千与千寻评论
2.1 查看网页
https://movie.douban.com/subject/1291561/comments?start=0&limit=20&sort=new_score&status=P
start=后面的数字从0开始以20为公差递增,我们爬取0,20,40直到180,即前200条评论。
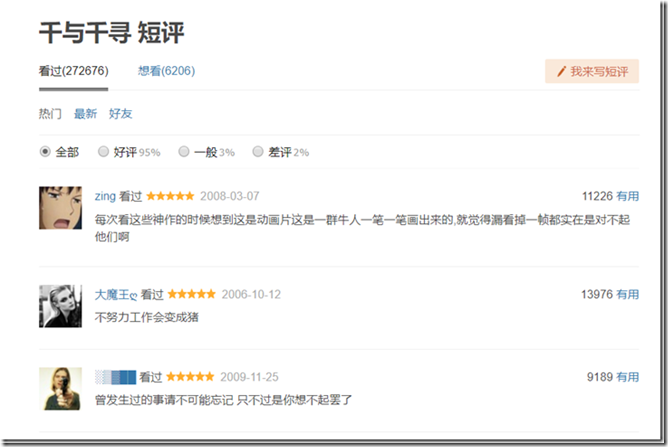
页面截图:
源码:
<div class="comment">
<h3>
<span class="comment-vote">
<span class="votes">3492</span>
<input value="82042845" type="hidden"/>
<a href="javascript:;" class="j a_show_login" onclick="">有用</a>
</span>
<span class="comment-info">
<a href="https://www.douban.com/people/oceanheart/" class="">深海的心</a>
<span>看过</span>
<span class="allstar40 rating" title="推荐"></span>
<span class="comment-time " title="2008-12-22 22:28:54">
2008-12-22
</span>
</span>
</h3>
<p class=""> <span class="short">有那么那么经典吗?还是我老了?</span>
</p>
</div>
待爬取信息:
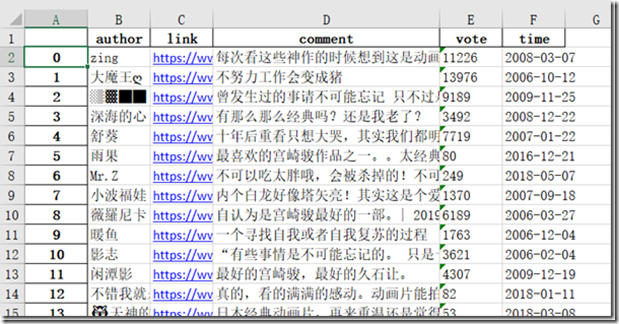
评论用户、用户链接、评论内容、评论投票数、评论时间。
2.2 items.py
import scrapy class TutorialItem(scrapy.Item):
author = scrapy.Field()#评论用户
link = scrapy.Field()#用户链接
comment = scrapy.Field()#评论内容
vote = scrapy.Field()#评论投票数
time = scrapy.Field()#评论时间
2.3 myspider.py
import scrapy
from tutorial.items import TutorialItem
import numpy as np head = "https://movie.douban.com/subject/1291561/comments?start="
class MySpider(scrapy.Spider): # 设置name
name = "douban"
# 设定域名
allowed_domains = ["movie.douban.com"]
# 填写爬取地址
start_urls = [head + str(num) + "&limit=20&sort=new_score&status=P" for num in np.arange(0,200,20)] # 编写爬取方法
def parse(self, response):
for line in response.xpath('//div[@class="comment"]'):
# 初始化item对象保存爬取的信息
item = TutorialItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
item['author'] = line.xpath('.//span[@class="comment-info"]/a/text()').extract()
item['link'] = line.xpath('.//span[@class="comment-info"]/a/@href').extract()
item['comment'] = line.xpath('.//span[@class="short"]/text()').extract()
item['vote'] = line.xpath('.//span[@class="comment-vote"]/span[@class="votes"]/text()').extract()
item['time'] = line.xpath('.//span[@class="comment-info"]/span[@class="comment-time "]/text()').extract()
yield item
仍采用列表存放URL,复习了XPath知识。
2.4 settings.py
设置编码:
FEED_EXPORT_ENCODING ='utf-8'
修改请求头:
USER_AGENT = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36"
其他设置保持默认。
2.5 数据存储
另外新建一个py脚本,放在和工程文件夹tutorial相同的目录下。
import pandas as pd
import os
import json #切换工作目录至当前脚本路径
os.chdir(os.path.split(os.path.realpath(__file__))[0]+'\\tutorial')
os.system("rm items.json")
os.system("scrapy crawl douban -o items.json") with open('items.json', 'r', encoding='utf-8') as f:
data = json.load(f)
for i in range(0,len(data)):
for k in data[i].keys():
data[i][k] = data[i][k][0].strip()
allInfo = pd.DataFrame() allInfo = allInfo.append(data,ignore_index=True) allInfo.to_excel('../commentInfo.xlsx', encoding="utf-8")
- 采用os包中的函数执行shell命令;
- 关于工作目录的切换;
- 使用-o items.json保存json文件;
- 由于json难以直接阅读,所以将其转换为数据框并以Excel格式写出。
2.6 查看数据
执行程序后,在tutorial文件夹下新增items.json文件。
在notepad++中打开查看:

在py脚本文件所在目录新增commentInfo.xlsx文件,打开查看:
3. 六度分隔爬虫游戏
六度分隔(Six Degrees of Separation)理论。简单地说:“你和任何一个陌生人之间所间隔的人不会超五个,也就是说,最多通过六个人你就能够认识任何一个陌生人。(来自百度百科)
百度百科中有很多词条,并且相互直接有链接沟通,所以我们尝试从某一词条链接出发,不断向其他词条页面跳转,看看是否能在6次之内到达目标词条。创意来自《Python网络数据采集》。
3.1 查看网页
这里以我喜欢的歌手邓丽君的词条页面为例。
部分源码:

通过观察可以发现,指向其他词条的链接都带有属性target="_blank",且链接样式为类似于/item/%E6%B5%B7%E9%9F%B5的utf-8编码。
以邓丽君页面为起始页面,以我喜欢的演员刘亦菲的词条页面为终止页面。
3.2 爬虫代码
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import random start = "邓丽君"
end = "刘亦菲" def getLinks(articleUrl):
html = urlopen("https://baike.baidu.com"+articleUrl)
bsObj = BeautifulSoup(html)
allLinks = bsObj.findAll("a", {"target": "_blank"})
links = []
for i in range(len(allLinks)):
isEntry = re.match("/item/(%[0-9A-F])+.+", allLinks[i].attrs["href"])
text = allLinks[i].get_text().strip()
repetition = allLinks[i].attrs["href"] in [link.attrs["href"] for link in links]
if isEntry!=None and text!="" and not(repetition):
links.append(allLinks[i])
return links
def getUTF8(string):
UTF8=str(string.encode('utf-8')).upper()
pattern = re.compile("(?<=').+(?=')")
return re.sub("\\\\X", "%", pattern.findall(UTF8)[0]) startLinks = getLinks("/item/"+getUTF8(start))
flag = 0
#试验100次
for i in range(0,100):
links = startLinks
if(flag == 1):
break
for j in range(0,6):
if len(links) > 0:
if end in [link.get_text().strip() for link in links]:
print("在第",i+1, "轮寻找", "第", j, "次跳转", "中找到")
flag = 1
break
ran = random.randint(0, len(links)-1)
newArticle = links[ran].attrs["href"]
print("第",i+1, "轮寻找", "第", j+1, "次跳转", links[ran].get_text().strip())
links = getLinks(newArticle)
else:
print("爬虫中断")
break
if(flag == 0):
print("100轮寻找已完成,很遗憾未能找到。请检查end变量是否是百度百科中存在的词条。")
3.3 部分说明
- 观察发现百度百科词条链接中的utf-8编码就是词条中文名的编码,所以构建了getUTF8函数;
- 在getLinks函数中,对获取到的链接进行如下检查:是否符合词条链接的格式(正则表达式),是否为空,是否重复,将符合格式、非空且不重复的链接列表返回;
- 最大跳转次数为6,默认进行100轮尝试,如果找到则停止。
3.4 结果展示


运行了两次试验一下,结果如上所示。
去浏览器看一下,确实可以根据爬虫给出的路线找到“刘亦菲”。

因为这两个明星比较有名气吧,关联到的词条比较多,所以一般总是能在100轮寻找中找到,不过这也和运气有关呢。
可以修改start和end进行其他测试,但是需要保证该词语在百度百科的词条中存在,start不存在会报错,end不存在会找不到。
最新文章
- 【热文】 为什么很多硅谷工程师偏爱 OS X,而不是 Linux 或 Windows?
- asp.net 项目Net4.0 在IE10、 IE 11 下出现 “__doPostBack”未定义 的解决办法
- sourceTree忽略文件
- sql 中set和select区别
- LA 3938 动态最大连续和 线段树
- 【poi xlsx报错】使用POI创建xlsx无法打开
- boost:program_options
- [原创]dm642_HPI调通并boot成功
- tyvj1728 普通平衡树
- linux常用命令(5)rmdir命令
- android动画基础之Animation
- iOS 类似2048、4096小游戏-OC
- 经典案例之MouseJack
- T9 HDU1298
- Integer的最大值
- 微信小程序传参数的几种方法
- cc150 --链表中倒数第k个节点
- hibernate学习之一 框架配置
- 「Django」rest_framework学习系列-序列化
- ZOJ 3261 Connections in Galaxy War (逆向+带权并查集)