RDD的缓存
2024-10-16 01:58:14
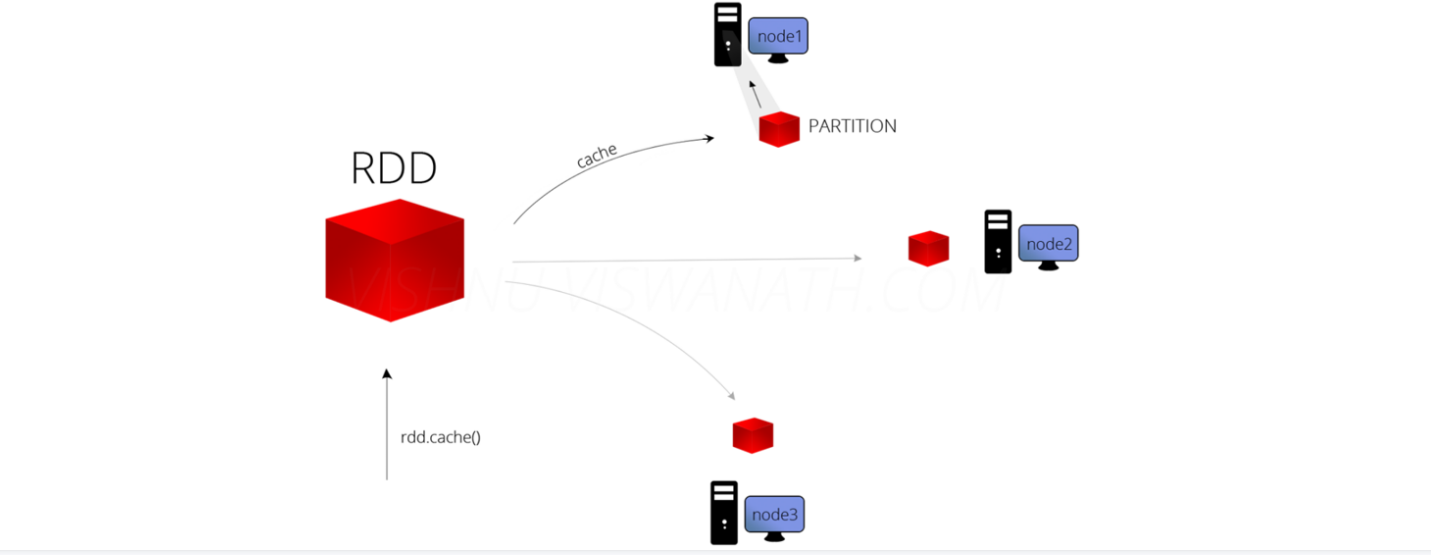
RDD的缓存/持久化
缓存解决的问题
缓存解决什么问题?-解决的是热点数据频繁访问的效率问题
在Spark开发中某些RDD的计算或转换可能会比较耗费时间,
如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,
这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object Demo16Cache {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("****").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/words.txt")
//加入缓存的三种方式
//方式一
linesRDD.cache()//将常用的RDD放入缓存中,增加效率
//StorageLevel.MEMORY_ONLY 默认只放在缓存中
//方式二
//linesRDD.persist()
//def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
//指定缓存存储方式
linesRDD.persist(StorageLevel.MEMORY_AND_DISK)
/**
* 缓存的存储方式:推荐使用MEMORY_AND_DISK
* object StorageLevel {
* val NONE = new StorageLevel(false, false, false, false)
* val DISK_ONLY = new StorageLevel(true, false, false, false)
* val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
* val MEMORY_ONLY = new StorageLevel(false, true, false, true)
* val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
* val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
* val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
* val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
* val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
* val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
* val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
* val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
*/
linesRDD.flatMap(word => word)
.groupBy(word => word)
.map(l => {
val word = l._1
val cnt = l._2.size
word + "," + cnt
}).foreach(println)
val wordRDD: Unit = linesRDD.map(word => word)
.foreach(println)
//释放缓存
linesRDD.unpersist()
}
}
RDD中的checkpoint
RDD数据可以持久化到内存中,虽然是快速的,但是不可靠
也可以把数据放在磁盘上,也并不是完全可靠的,
我们可以把缓存数据放到我的HDFS中,借助HDFS的高可靠,高可用以及高容错来保证数据安全
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
object Demo17CheckPoint {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/words.txt")
/**
* RDD数据可以持久化到内存中,虽然是快速的,但是不可靠
* 也可以把数据放在磁盘上,也并不是完全可靠的
* 我们可以把缓存数据放到我的HDFS中,借助HDFS的高可靠,高可用以及高容错来保证数据安全
*
*/
//设置HDFS的目录
sc.setCheckpointDir("spark/data/checkPoint")
//对需要缓存的RDD进行checkPoint
linesRDD.checkpoint()
linesRDD.flatMap(word => word)
.groupBy(word => word)
.map(l => {
val word = l._1
val cnt = l._2.size
word + "," + cnt
}).foreach(println)
val wordRDD: Unit = linesRDD.map(word => word)
.foreach(println)
}
}
最新文章
- pycharm连接mysql数据库
- C# 获取当前月第一天和最后一天 计算两个日期差多少天
- IOS网络第二天 - 09-多值参数
- Silverlight RadChart :创建十字定位&圈选
- [转] 如何设置Eclipse的上网代理
- shell 统计GMT0 时区的数据
- ADB server didn't ACK的解决方法
- 搞懂offsetY、offsetTop、scrollTop、offsetHeight、scrollHeight
- WdatePicker 动态变量表
- WPF 如何缓解大量控件加载缓慢的问题
- 更改firefox默认搜索引擎
- Windows10系统PHP开发环境配置
- TQ2440--nandflash(K9F2G08U0A)驱动编写
- NandFlash学习
- C#概念总结(一)
- GGTalk ——C#开源即时通讯系统
- Linux卸载搭建环境
- A1091. Acute Stroke
- HTML学习-2标记标签-1
- CopyOnWriteArraySet源码解析