Python每日一题 008
2024-10-07 16:57:08
题目
基于多线程的网络爬虫项目,爬取该站点http://www.tvtv.hk 的电视剧收视率排行榜
分析
robots.txt
User-agent: Yisouspider
Disallow: /wp-admin
User-agent: ChinasoSpider
Disallow: /
User-agent: MJ12bot
Disallow: /
User-agent: AhrefsBot
Disallow: /
User-agent: YandexBot
Disallow: /
一级URL:http://www.tvtv.hk/archives/category/dianshiju/page/1
二级URL格式:http://www.tvtv.hk/archives/8078.html
从一级URL页面中获取二级URL
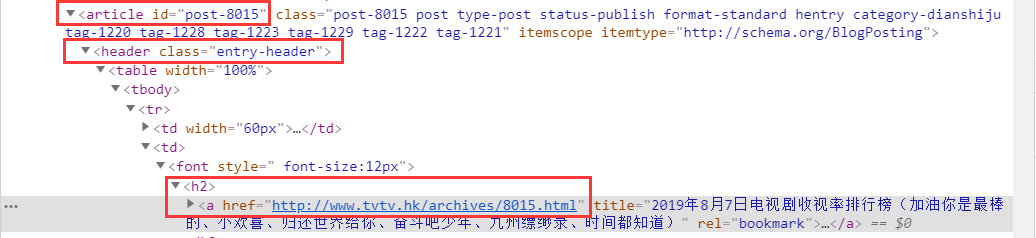
分析二级URL页面下的内容获取数据:

代码
# coding:"utf-8"
import urllib.request
from bs4 import BeautifulSoup
import re
# 爬取网页内容
def download(url):
print("正在爬取:", url)
try:
html = urllib.request.urlopen(url).read()
html = BeautifulSoup(html, 'lxml')
except urllib.request.URLError as e:
print("爬取错误:", e.reason)
html = None
return html
# 获取下一级网页中的URL
def find_url(page, tag):
page = str(page.find_all(tag))
url_list = re.findall('<a href="(.*?)" rel="bookmark"', page)
return url_list
# 爬取收视数据
def get_content(url_list):
word_data = []
for i in url_list:
html = download(i)
contents = html.find_all('p')
word_data.extend(re.findall('<p>(.*?)</p>, <p>', str(contents)))
return word_data
# 爬取图片
def img_data(url_list):
img_src = []
for j in url_list:
html = download(j)
contents = html.find_all('p')
img_src.extend(re.findall('src="(.*?)"/></p>', str(contents)))
return img_src
def write_content_tofile(filename1, filename2):
# 保存文本内容
with open(filename1, 'w+', encoding='utf-8') as f1:
data = get_content(url_list)
for i in data:
f1.write(i + "\n")
# 保存图片
img = img_data(url_list)
for j in range(len(img)):
print('正在下载第'+str(j+1)+'张图片')
path = str(j+1)
with open(filename2 + path + '.jpg', 'wb') as f2:
image_data = urllib.request.urlopen(img[j]).read()
f2.write(image_data)
if __name__ == "__main__":
url = "http://www.tvtv.hk/archives/category/dianshiju/page/1"
filename1 = "E:\\1.txt"
filename2 = "E:\\img\\"
page = download(url)
url_list = find_url(page, 'h2')
write_content_tofile(filename1, filename2)
暂时只是爬取单个页面的内容,后续更新多线程以及批量爬取!
最新文章
- [PGM] I-map和D-separation
- (转)雅虎工程师提供的css初始化示例代码
- 码农谷 求前N项之和
- itoa函数的实现(不同进制)
- CSS3最简洁的轮播图
- iOS7——图像资源Images Assets
- 如何在sublime中使用sass
- Ajax的工作原理以及优点、缺点 (汇总)
- 【TensorFlow篇】--DNN初始和应用
- 重新定义Pytorch中的TensorDataset,可实现transforms
- 居中分栏flex完美的解决方案
- (转)浅谈Hybrid技术的设计与实现
- JUnit4测试报错:class not found XXX
- 005_系统运维之SLA与SLO的关系
- C# 通过http post 请求上传图片和参数
- C++新式转型
- [CCC 2018] 平衡树
- gradle asciidoc 使用
- [ActionScript 3.0] 实现放大镜效果的简单方法
- 自己写js库,怎么支持AMD