EM相关两个算法 k-mean算法和混合高斯模型
转自http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
k-mean算法与EM
K-means也是聚类算法中最简单的一种了,但是里面包含的思想却是不一般。最早我使用并实现这个算法是在学习韩爷爷那本数据挖掘的书中,那本书比较注重应用。看了Andrew Ng的这个讲义后才有些明白K-means后面包含的EM思想。
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x,比如假设宇宙中的星星可以表示成三维空间中的点集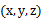 。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
在聚类问题中,给我们的训练样本是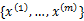 ,每个
,每个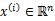 ,没有了y。
,没有了y。
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
|
1、 随机选取k个聚类质心点(cluster centroids)为 2、 重复下面过程直到收敛 { 对于每一个样例i,计算其应该属于的类
对于每一个类j,重新计算该类的质心
} |
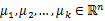 。
。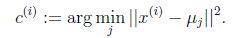
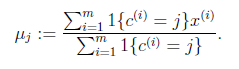
K是我们事先给定的聚类数, 代表样例i与k个类中距离最近的那个类,
代表样例i与k个类中距离最近的那个类, 的值是1到k中的一个。质心
的值是1到k中的一个。质心 代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为
代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为 ,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心
,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心 (对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
下图展示了对n个样本点进行K-means聚类的效果,这里k取2。

K-means面对的第一个问题是如何保证收敛,前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数(distortion function)如下:

J函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当前J没有达到最小值,那么首先可以固定每个类的质心 ,调整每个样例的所属的类别
,调整每个样例的所属的类别 来让J函数减少,同样,固定
来让J函数减少,同样,固定 ,调整每个类的质心
,调整每个类的质心 也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,
也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时, 和c也同时收敛。(在理论上,可以有多组不同的
和c也同时收敛。(在理论上,可以有多组不同的 和c值能够使得J取得最小值,但这种现象实际上很少见)。
和c值能够使得J取得最小值,但这种现象实际上很少见)。
由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的 和c输出。
和c输出。
下面累述一下K-means与EM的关系,首先回到初始问题,我们目的是将样本分成k个类,其实说白了就是求每个样例x的隐含类别y,然后利用隐含类别将x归类。由于我们事先不知道类别y,那么我们首先可以对每个样例假定一个y吧,但是怎么知道假定的对不对呢?怎么评价假定的好不好呢?我们使用样本的极大似然估计来度量,这里是就是x和y的联合分布P(x,y)了。如果找到的y能够使P(x,y)最大,那么我们找到的y就是样例x的最佳类别了,x顺手就聚类了。但是我们第一次指定的y不一定会让P(x,y)最大,而且P(x,y)还依赖于其他未知参数,当然在给定y的情况下,我们可以调整其他参数让P(x,y)最大。但是调整完参数后,我们发现有更好的y可以指定,那么我们重新指定y,然后再计算P(x,y)最大时的参数,反复迭代直至没有更好的y可以指定。
这个过程有几个难点,第一怎么假定y?是每个样例硬指派一个y还是不同的y有不同的概率,概率如何度量。第二如何估计P(x,y),P(x,y)还可能依赖很多其他参数,如何调整里面的参数让P(x,y)最大。这些问题在以后的篇章里回答。
这里只是指出EM的思想,E步就是估计隐含类别y的期望值,M步调整其他参数使得在给定类别y的情况下,极大似然估计P(x,y)能够达到极大值。然后在其他参数确定的情况下,重新估计y,周而复始,直至收敛。
上面的阐述有点费解,对应于K-means来说就是我们一开始不知道每个样例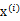 对应隐含变量也就是最佳类别
对应隐含变量也就是最佳类别 。最开始可以随便指定一个
。最开始可以随便指定一个 给它,然后为了让P(x,y)最大(这里是要让J最小),我们求出在给定c情况下,J最小时的
给它,然后为了让P(x,y)最大(这里是要让J最小),我们求出在给定c情况下,J最小时的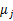 (前面提到的其他未知参数),然而此时发现,可以有更好的
(前面提到的其他未知参数),然而此时发现,可以有更好的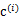 (质心与样例
(质心与样例 距离最小的类别)指定给样例
距离最小的类别)指定给样例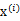 ,那么
,那么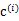 得到重新调整,上述过程就开始重复了,直到没有更好的
得到重新调整,上述过程就开始重复了,直到没有更好的 指定。这样从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量
指定。这样从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量 ,M步更新其他参数
,M步更新其他参数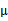 来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
混合高斯模型(Mixtures of Gaussians)和EM算法
这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation)。
与k-means一样,给定的训练样本是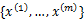 ,我们将隐含类别标签用
,我们将隐含类别标签用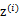 表示。与k-means的硬指定不同,我们首先认为
表示。与k-means的硬指定不同,我们首先认为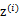 是满足一定的概率分布的,这里我们认为满足多项式分布,
是满足一定的概率分布的,这里我们认为满足多项式分布,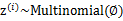 ,其中
,其中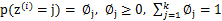 ,
,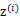 有k个值{1,…,k}可以选取。而且我们认为在给定
有k个值{1,…,k}可以选取。而且我们认为在给定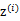 后,
后,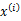 满足多值高斯分布,即
满足多值高斯分布,即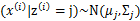 。由此可以得到联合分布
。由此可以得到联合分布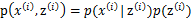 。
。

整个模型简单描述为对于每个样例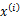 ,我们先从k个类别中按多项式分布抽取一个
,我们先从k个类别中按多项式分布抽取一个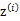 ,然后根据
,然后根据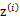 所对应的k个多值高斯分布中的一个生成样例
所对应的k个多值高斯分布中的一个生成样例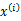 ,。整个过程称作混合高斯模型。注意的是这里的
,。整个过程称作混合高斯模型。注意的是这里的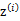 仍然是隐含随机变量。模型中还有三个变量
仍然是隐含随机变量。模型中还有三个变量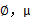 和
和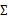 。最大似然估计为
。最大似然估计为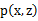 。对数化后如下:
。对数化后如下:
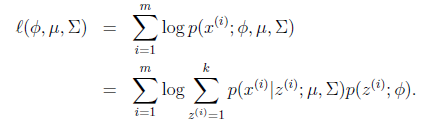
这个式子的最大值是不能通过前面使用的求导数为0的方法解决的,因为求的结果不是close form。但是假设我们知道了每个样例的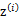 ,那么上式可以简化为:
,那么上式可以简化为:
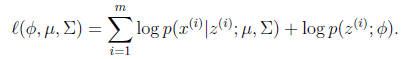
这时候我们再来对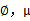 和
和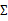 进行求导得到:
进行求导得到:
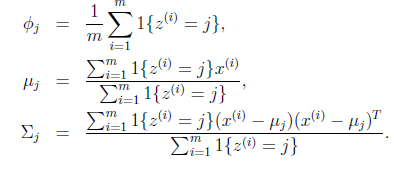
 就是样本类别中
就是样本类别中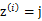 的比率。
的比率。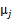 是类别为j的样本特征均值,
是类别为j的样本特征均值,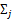 是类别为j的样例的特征的协方差矩阵。
是类别为j的样例的特征的协方差矩阵。
实际上,当知道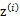 后,最大似然估计就近似于高斯判别分析模型(Gaussian discriminant analysis model)了。所不同的是GDA中类别y是伯努利分布,而这里的z是多项式分布,还有这里的每个样例都有不同的协方差矩阵,而GDA中认为只有一个。
后,最大似然估计就近似于高斯判别分析模型(Gaussian discriminant analysis model)了。所不同的是GDA中类别y是伯努利分布,而这里的z是多项式分布,还有这里的每个样例都有不同的协方差矩阵,而GDA中认为只有一个。
之前我们是假设给定了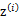 ,实际上
,实际上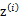 是不知道的。那么怎么办呢?考虑之前提到的EM的思想,第一步是猜测隐含类别变量z,第二步是更新其他参数,以获得最大的最大似然估计。用到这里就是:
是不知道的。那么怎么办呢?考虑之前提到的EM的思想,第一步是猜测隐含类别变量z,第二步是更新其他参数,以获得最大的最大似然估计。用到这里就是:
|
循环下面步骤,直到收敛: { (E步)对于每一个i和j,计算
(M步),更新参数:
} |
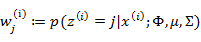
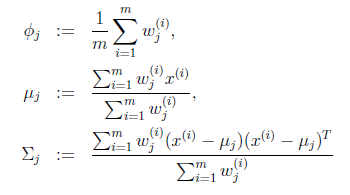
在E步中,我们将其他参数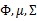 看作常量,计算
看作常量,计算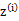 的后验概率,也就是估计隐含类别变量。估计好后,利用上面的公式重新计算其他参数,计算好后发现最大化最大似然估计时,
的后验概率,也就是估计隐含类别变量。估计好后,利用上面的公式重新计算其他参数,计算好后发现最大化最大似然估计时,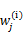 值又不对了,需要重新计算,周而复始,直至收敛。
值又不对了,需要重新计算,周而复始,直至收敛。
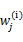 的具体计算公式如下:
的具体计算公式如下:
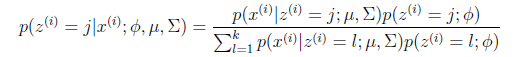
这个式子利用了贝叶斯公式。
这里我们使用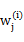 代替了前面的
代替了前面的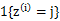 ,由简单的0/1值变成了概率值。
,由简单的0/1值变成了概率值。
对比K-means可以发现,这里使用了“软”指定,为每个样例分配的类别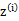 是有一定的概率的,同时计算量也变大了,每个样例i都要计算属于每一个类别j的概率。与K-means相同的是,结果仍然是局部最优解。对其他参数取不同的初始值进行多次计算不失为一种好方法。
是有一定的概率的,同时计算量也变大了,每个样例i都要计算属于每一个类别j的概率。与K-means相同的是,结果仍然是局部最优解。对其他参数取不同的初始值进行多次计算不失为一种好方法。
虽然之前再K-means中定性描述了EM的收敛性,仍然没有定量地给出,还有一般化EM的推导过程仍然没有给出。下一篇着重介绍这些内容。
最新文章
- 浏览器怎么添加 Axure扩展程序
- node(Buffer缓存区)
- WCF初探-25:WCF中使用XmlSerializer类
- JavaScript如何检查网站是可以访问
- 一天一小段js代码(no.1)
- 今天依然是 JQ点击事件之“点击淡入淡出事件”
- Semaphore tryAcquire release 正确的使用方法
- ASP.NET MVC Razor HtmlHelper扩展和自定义控件
- Windows下访问VMware中tomcat
- MySQL中函数、游标、事件、视图
- listview的简单封装
- 重新认识JavaScript里的数据类型
- 201521123022 《Java程序设计》 第一周学习总结
- django框架使用mysql步骤
- iOS 防止离屏渲染为 image 添加圆角
- 【MySQL经典案例分析】关于数据行溢出由浅至深的探讨
- python之GIL release (I/O open(file) socket time.sleep)
- playframework 一步一步来 之 日志(一)
- 转:SpringMVC之类型转换Converter(GenericConverter)
- Reg命令使用详解 批处理操作注册表必备