nodejs爬虫编码问题
2024-09-05 03:57:22
最近再做一个nodejs网站爬虫的项目,但是爬一些网站的数据出现了中文字符乱码的问题。查了一下,主要是因为不是所有的网站的编码格式都是utf-8,还有一些网站用的是gb2312或者gbk的编码格式。所以需要做一个处理来进行编码的解码。至于网站的编码怎么看,可以通过去检查中的network去看。
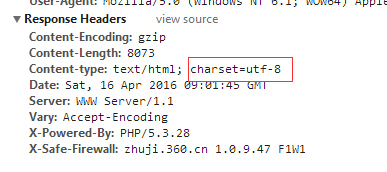
根据相应的编码格式,进行相应的设置。utf-8就不要说了,下面就以gbk为例,说一下解码的方式。
var request = require('request');
var cheerio = request('cheerio');
var iconv = require('iconv-lite');
request ({
url : 'http://www.taobao.com',
encodeing = null
},function(err,res,body){
if (err) throw err;
// decode the content of the website
body = iconv.decode(body,'gbk');
var $ = cheerio.load(body);
console.log($('head title').text());
})或者是使用一个gbk包,但我觉得还是上面的方式比较好。
最新文章
- 三、oracle数据库成功安装步骤 Oracle数据源配置
- Ajax实现原理详解
- sql 大数据库 插入超时问题解决
- Codeforces Round #133 (Div. 2)
- AngularJs记录学习02
- arp spoofing
- Socket异步通信学习二
- objective-C: nonatomic retain copy assgin 等属性详解
- BuildSigar
- 关于AngularJS学习整理---浅谈$scope(作用域) 新手必备!
- RxJava 笔记
- MyEclipse如何全局搜索
- 杨学明老师推出全新课程--《敏捷开发&IPD和敏捷开发结合的实践》
- linux 更新yum源 改成阿里云源
- Linux配置java环境变量 【随手记】
- 第二章 微服务网关基础组件 - zuul入门
- nginx expires配置
- underscore objects
- Mythological VI
- C#(静态String类)