Python爬虫:scrapy 的运行流程和各模块的作用
2024-09-06 13:25:01
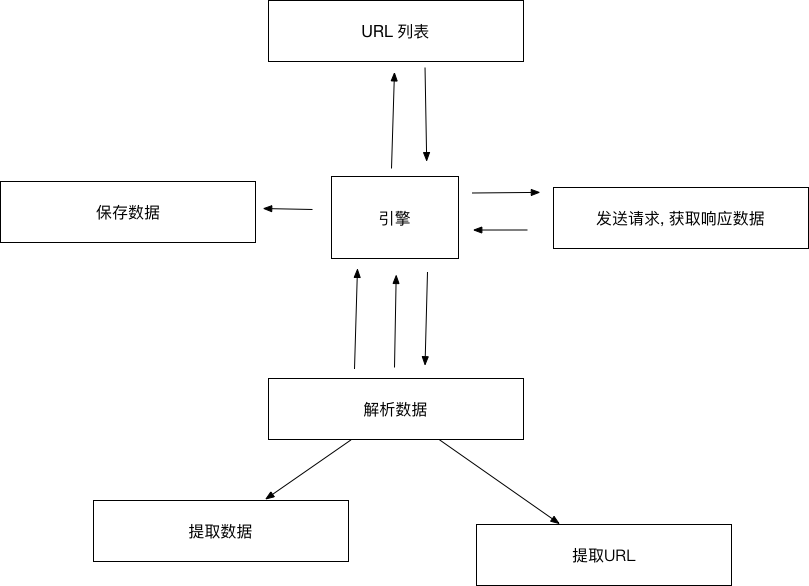
scrapy的运行流程
- 爬虫 -> 起始URL封装Request -> 爬虫中间件 -> 引擎 -> 调度器(Scheduler): 缓存请求, 请求去重
- 调度器 -> 请求 -> 引擎 -> 经过下载器中间件 -> 下载器(发送请求, 获取响应数据, 封装Response)
- 下载器 - Response(响应) -> 经过下载器中间件 -> 引擎
- 引擎 - response -> 经过爬虫中间件 -> 爬虫 (解析数据, 提取URL封装请求, 提取数据)
- 爬虫:
- 提取URL封装请求 -> 爬虫中间件 -> 引擎 -> 调度器
- 提取数据 -> 引擎 -> 管道(Pipeline: 处理数据, 比如保存)
各个模块及作用:
爬虫模块:
- 构建起始请求 2. 响应数据解析(1. 提取URL封装请求, 2. 提取数据) (需要自己写)
调度器模块:
- 缓存请求 2. 请求去重 (已经实现了)
下载器模块:
发送请求, 获取响应数据,封装为Response(已经实现了)
管道模块:
处理数据, 比如保存(需要自己写)
引擎模块:
总指挥: 负责模块之间调度, 以及数据传递(已经实现了)
下载器中间件:
在引擎和下载器之间, 可以对请求和响应数据进行处理, 比如: 实现随机代理IP, 随机User-Agent
爬虫中间件:
爬虫和引擎之间, 可以对请求和响应数据进行处理, 比如过滤. (很少)
最新文章
- python入门练习题3(函数)
- mysql查询优化器为什么可能会选择错误的执行计划
- shopnc 二次开发 每日签到积分领取
- Spring —— 三种配置数据源的方式:spring内置、c3p0、dbcp
- [转] 3个学习Socket编程的简单例子:TCP Server/Client, Select
- 嵌入式系统关机/Embeded System PowerOff HowTo?
- 在VirtualBox中安装了Ubuntu后,Ubuntu的屏幕分辨率非常小,操作非常不便。通过安装VirtualBox提供的“增强功能组件”,-摘自网络
- 【HDOJ】1385 Minimum Transport Cost
- Oracle sql语言模糊查询--like后面的通配符
- KVC中setValuesForKeysWithDictionary:
- C#秘密武器之扩展方法
- WindowsServer2012 R2 64位中文标准版(IIS8.5)下手动搭建PHP环境详细图文教程(二)安装IIS8.5
- php隔行换色输出表格
- configpraser模块
- java项目引用证书文件(微信支付的p12文件)
- synchronized与volatile的区别及各自的作用、原理(学习记录)
- WM-结汇
- DevOps自动化工具集合
- 8.2 C++标准输出流对象
- url参数的转码和解码