Django --- ORM表查询
使用数据库之前的配置工作
settings.py中的配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'day53',
'USER':'root',
'PASSWORD':'123qwe',
'HOST':'127.0.0.1',
'PORT':3306,
'CHARSET':'utf8'
}}
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
init.py中的配置
import pymysql
pymysql.install_as_MySQLdb()
test.py中配置
import os
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day53.settings")
import django
django.setup()
from app01 import models # 一定要写在下边
单表操作常用的方法
创建数据
# 1.create方法创建数据
book_obj = models.Books.objects.create(title='三国演义',price=123.23,publish_date='2019-11-11')
# 2.利用对象的绑定方法
book_obj = models.Books(title='西游记',price=666.66,publish_date='2000-1-21')
book_obj.save()
修改数据
# 方式1 利用queryset方法
models.Books.objects.filter(pk=1).update(price=444.66)
# 方式2 利用对象
book_obj = models.Books.objects.get(pk=1)
book_obj.price = 222.66
book_obj.save()
# pk会自动帮你找到当前的主键字段,所以会经常使用pk来指代主键字段;
filter查询
filter查询出来的结果是一个Queryset对象
1.只要是queryset对象就可以无限制的调用queryset的方法
2.只要是queryset对象就可以点query查看当前结果内部对应的sql语句
get和filter的区别
1.filter获取到的是一个queryset对象,类似于一个列表
2.get获取到的直接就是数据对象本身
3.当条件不存在的时候,filter直接返回一个空,而get会直接报错,所以推荐使用filter
删除数据
# 1.利用queryset方法 delete()
models.Books.objects.filter(pk=3).delete()
# 2,对象方法
book_obj = models.Books.objects.get(pk=3)
book_obj.delete()
查数据13条
1.查所有 all()
res = models.Books.objects.all() # 返回结果Queryset对象,是列表套对象的行式
2.筛选 filter()
res = models.Books.objects.filter(pk=1,title='三') # 支持多个参数,并且是and关系,不能模糊刷选
3.筛选 get()
res = models.Books.objects.get(title='西游记') # 获取的是数据对象本身,条件不存在的时候会直接报错,并且查询条件必须是唯一
4.取queryset中第一个数据对象 first()
res = models.Books.objects.filter(title='西游记').first()
5.取queryset中最后一个对象 last()
res = models.Books.objects.filter(title='西游记').last()
6.统计数据的个数 count()
num = models.Books.objects.count() # 不需要传入参数
7.获取数据对象中指定的字段的值 values()
res = models.Books.objects.values('title','price')
# 可以有多个,格式是列表套字典
8.获取数据对象中指定的字段的值 values_list()
res = models.Books.objects.values_list('title','price')
# 可以有多个,格式是列表套元组 <QuerySet [('西游记',), ('水浒传',), ('红楼梦',)]>
9.按照指定的字段排序 order_by()
res = models.Books.objects.order_by('price')
res1 = models.Books.objects.all().order_by('price')
# 默认是升序,两者等价,下边的语义更明确
#倒序
res1 = models.Books.objects.all().order_by('-price')
10.颠倒顺序 reverse()
res3 = models.Books.objects.all().order_by('price').reverse()
# 前提是颠倒的对象必须有顺序,(提前排序之后才能颠倒)
11.排除对象 exclude()
res = models.Books.objects.all().exclude(title='三国演义')
# <QuerySet [<Books: 红楼梦>, <Books: 西游记1>, <Books: 西游记2>]>
12.判断查询结果是否有值 exists()
res = models.Books.objects.filter(pk=1).exists()
# 返回时布尔值,但是数据本身就带有布尔值,所以一般不需要使用
13.对查询结果进行去重操作 distinct()
res = models.Books.objects.values('title','price').distinct()
# 去重的前提时数据必须时完全一样的情况下才能够去重,容易忽略的时主键
神奇的下划线方法
查询价格大于X的值
res = models.Books.objects.filter(price__gt=500)
查询价格小于X的值
res = models.Books.objects.filter(price__lt=400)
查询价格大于等于X的值
res = models.Books.objects.filter(price__gte=500)
# 使用数字是小数的时候会查询不到等于的情况
查询小于等于X的值
res = models.Books.objects.filter(price__lte=500)
查询自定义区间内的值
res = models.Books.objects.filter(price__in=[222,444,500])
查询在某区间内的值
res = models.Books.objects.filter(price__range=(200,800)) # 顾头顾尾
查询出版日期是某年的值
res = models.Books.objects.filter(publish_date__year='2019')
查询出版日期是1月份的值
res = models.Books.objects.filter(publish_date__month='1')
# 只按照月份筛选,对年份没有要求
查询是以什么开头的值
res = models.Books.objects.filter(title__startswith='三')
查询是以什么结尾的值
res = models.Books.objects.filter(title__endswith='1')
查询值包含某个字段的值
res = models.Books.objects.filter(title__contains='p') # 默认区分大小写
res = models.Books.objects.filter(title__icontains='p') # 忽略大小写 加i
一对多字段的增删改查
增
# 第一种
models.Book.objects.create(title='三国演义',price=222.33,publish_id=1)
# 第二种
publish_obj = models.Publish.objects.filter(pk=2).first()
models.Book.objects.create(title='红楼梦',price=444.33,publish=publish_obj)
改
# 第一种
models.Book.objects.filter(pk=1).update(publish_id=2)
# 第二种
publish_obj = models.Publish.objects.filter(pk=1).first()
models.Book.objects.filter(pk=1).update(publish=publish_obj)
删
models.Publish.objects.filter(pk=1).delete() # 默认就是级联删除 级联更新
多对多字段数据的增删改查
增
# 给一本书添加作者
# 第一种
book_obj = models.Book.objects.filter(pk=2).first()
book_obj.author.add(5) # 添加一个
book_obj.author.add(3,5) # 添加多个
# 第二种
author_obj = models.Author.objects.filter(pk=1).first()
book_obj.author.add(author_obj)
#总结
add方法:能够朝第三张表中添加数据,支持添加数据也支持添加对象,
改
# 更改一本书的作者
# 第一种
book_obj = models.Book.objects.filter(pk=2).first()
book_obj.author.set((1,3)) # 必须是可迭代对象
# 第二种
book_obj = models.Book.objects.filter(pk=2).first()
author_obj = models.Author.objects.filter(pk=1).first()
book_obj.author.set((author_obj,)) # 不许是可迭代对象
#总结
set方法:set方法既可以按照数字进行设置,也可以按照对象进行设置,可以传入多个值,但是传入的参数必须是可迭代对象。
删
# 删除书的作者
# 第一种方法
book_obj = models.Book.objects.filter(pk=2).first()
book_obj.authors.remove(1,2)
# 第二种方法
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=2).first()
book_obj.authors.remove(author_obj,author_obj1)
#总结
remove方法:可以删除一个,也可以删除多个,并且不需要迭代,
清空
删除某个数据在第三张表中的所有数据
book_obj = models.Book.objects.filter(pk=2).first()
book_obj.author.clear()
# clear清空所有的相关记录,括号内不需要传递参数
跨表查询
注意:关系字段在谁那里,由谁查谁就是正向,如果没有关系字段,就是反向查询
基于对象跨表查询——正向查询
正向查询按字段,反向查询按表名小写+_set
# 查询书id为2的书的出版社名
# 第一种 --- 正向查询
book_obj = models.Book.objects.filter(pk=2).first()
print(book_obj.publish)
# 第二种 --- 上下划线查询
publish_obj = models.Publish.objects.filter(book__pk=2).first()
print(publish_obj.publish_name)
基于双下划线跨表查询
正向查询按字段,反向查询按表名小写+_set
# 查询作者'wang'写了哪些书
author_obj = models.Author.objects.filter(username='wang').first()
print(author_obj.book_set.all())
正向查询的时候,根据已有的主键,通过对象.主键的方式可以进入外键所在的表中,此时形成的是外键所在表的对象,根据对象.属性来进行查询需要的内容
authorbook
'__':__使用的时候是基于外键所在的表为查询对象,查询条件为 "表名小写__pk=2" 数字为需要查询的内容的id号,可以通过 " __ " 来使用外键所在的id,使用"__" 的前提是两张表之间使用外键进行关联过。不能没有外键关联使用这种方法
" 表名小写_set ":用book与author的表为例,author与book两张表的键在book中,所以查数对应的作者很简单,但是查作者对应的数就没有办法通过键来进行查询,此时使用 "book_set" 就相当于在author中使用了连接键。
一对一反向查询的时候直接对象.有外键的表名小写,可以进行查询,不需要使用_set方法
什么时候添加.all()
当查询出来的结果为多个的时候使用 .all() 来进行接收,会有提示的报错 app01.Author.None
聚合函数
什么是聚合查询
使用聚合函数进行查询,常用的聚合函数有:Max,Min,Sum,Count,Avg
聚合函数的使用
from django.db.models import Max,Min,Sum,Count,Avg
# 使用的时候是通过 aggregate()
# 使用方法一:直接在同一张表种使用聚合函数
res = models.Book.objects.aggregate(mr = Max('price'))
print(res) # {'mr': Decimal('400.00')}
# 使用方法二:在多表中使用聚合函数
res = models.Publish.objects.filter(pk=1).first().book_set.all().aggregate(ma = Max('price'))
print(res) # {'ma': Decimal('300.00')}
# 使用方法三:直接使用聚合函数
res = models.Book.objects.aggregate(Avg('price'))
print(res) # {'price__avg': 275.0}
# 注意点:
# 1.在同一张表中进行查询的时候,直接使用对象.aggregate的方法来使用,取出来的值是一个对象
# 2.当需要在多表中进行查询的时候,需要先找到对应表的对象,然后通过对象.aggregate的方式来使用
# 3.使用aggregate的时候,括号内只写聚合函数也可以
分组查询
分组查询就是先将需要查询的条件进行分类,然后再会分组后的数据进行条件查询,annotate中表示已经对需要分组的数据分组完成了,并且返回了一张总表,values中是需要对这张表进行查询到的数据,如果,该查询字段没有再分组的表中,会报错。
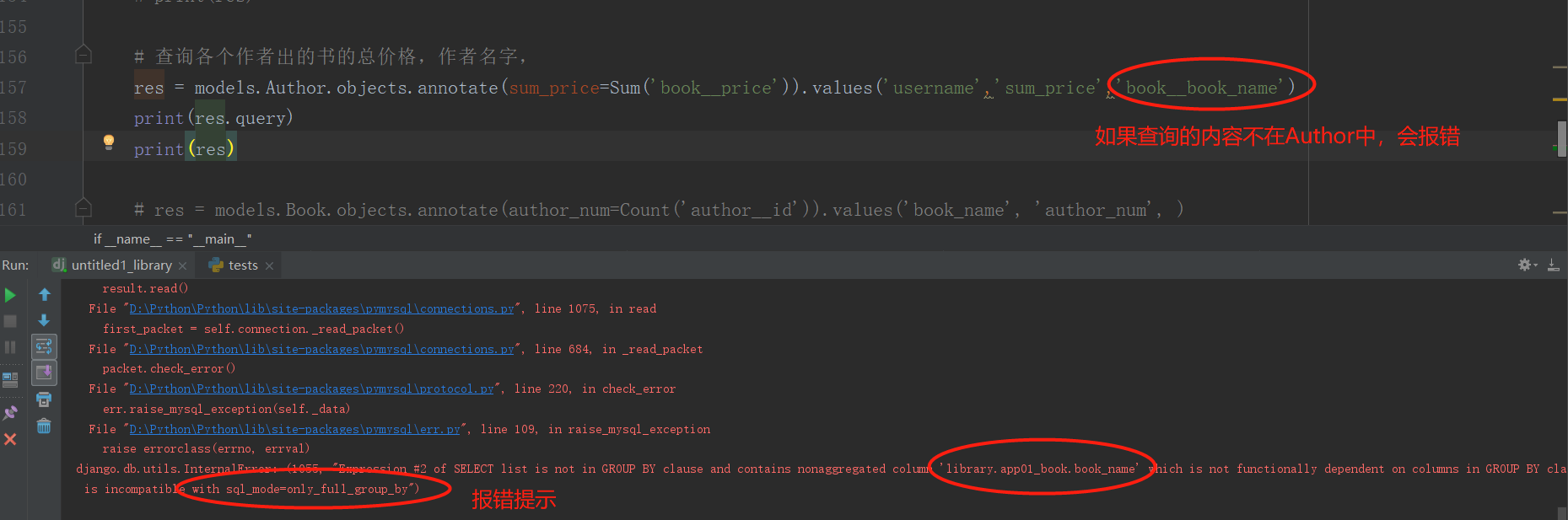
# 查询各个作者出的书的总价格,作者名字,
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('username','sum_price')
# 原生SQL语句
SELECT `app01_author`.`username`, SUM(`app01_book`.`price`) AS `sum_price` FROM `app01_author` LEFT OUTER JOIN `app01_book_author` ON (`app01_author`.`id` = `app01_book_author`.`author_id`) LEFT OUTER JOIN `app01_book` ON (`app01_book_author`.`book_id` = `app01_book`.`id`) GROUP BY `app01_author`.`id` ORDER BY NULL
# 打印结果
print(res)
<QuerySet [{'username': 'wang', 'sum_price': Decimal('400.00')}, {'username': 'zhang', 'sum_price': Decimal('500.00')}, {'username': 'qqq', 'sum_price': None}]>
总结:
1.需要查谁就对谁进行分组,“对每一个###”查询,就使用 “ ###” 进行分组,然后再将需要查询的值进行返回,values中的值必须是两张表中有的才能查询出来,没有的会报错。
2.按照先找到对应的表,然后进行分组,再将需要的数据进行查询。
3.分组之后只能拿分组的依据,如果想拿其他的值,只能通过聚合函数来操作,因为数据库中会有严格模式,不让进行查询。
F与Q查询
F查询
F可以通过拿到某个字段中的对应的值来当作筛选条件,
作用场景:在同一行操作总需要根据一个数据对另一个数据进行操作,例如:全体添加字段,查询卖出数大于库存数的商品
例1

**例2 ** 可以对查询出来的值进行加减乘乘除
from django.db.models import F
# 将所有书的价格上涨100块
models.Book.objects.all().update(price=F('price') + 100)
例3 对书名添加内容,需要借助Concat和Value模块
from django.db.models.functions import Concat
from django.db.models import Value
from django.db.models import F
res = models.Book.objects.update(book_name=Concat(F('book_name'),Value('促销')))
总结:F查询可以直接通过 F() 的方式将需要的值取出,而不需要使用对象 . filter() 的方式将值取出,这样的好处是可以对同一行中的数据进行比较处理。
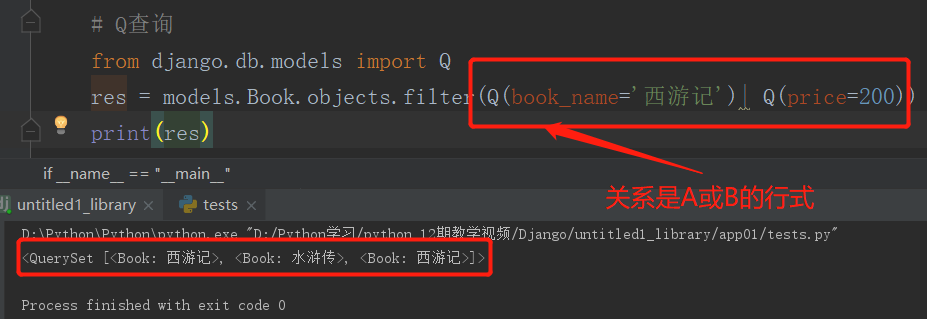
Q查询
使用filter查询的时候提供的是一种 A 和 B 的查询方式,而 Q 是提供一种 A 或 B 的查询方式,既可以包括A,也可以包括B,
Q的高级用法
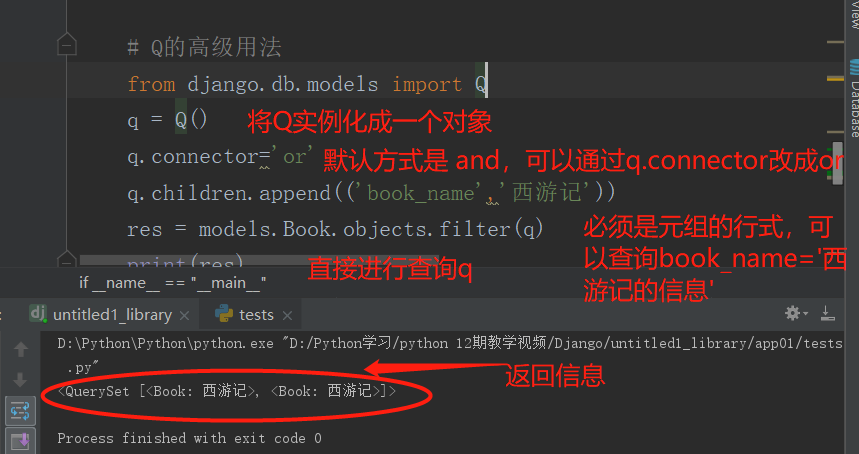
总结:Q查询查询的是或的关系,可以在多个包含的情况下使用,比filter的使用范围广一些。而对于Q的高级用法,可以将输入的字符串进行查找,不用再使用变量进行查找,可以在用户输入查询的时候使用。
最新文章
- awk神器
- 如何快速正确的安装 Ruby, Rails 运行环境---------------转载
- psp记录个人项目花费时间
- REORG TABLE命令优化数据库性能
- 【BZOJ-3437】小P的牧场 DP + 斜率优化
- Scala学习笔记(七):Application特质
- ThreadPoolExecutor 分析
- WPF:获取控件内的子项
- java从入门到卖肠粉系列
- phpstorm激活码生成器地址
- hdu 4777 树状数组+合数分解
- 辨析字节序(Endianness)
- 10个常见的JavaScript BUG
- Django+Uwsgi+Nginx
- Tomcat基本
- 如何比sketch和axure更方便地给原型做交互?
- 12月8日 周五 image_tag.
- 20155218 2016-2017-2 《Java程序设计》第10周学习总结
- November 29th 2016 Week 49th Tuesday
- MySQL DB 主从复制之SSL