JDK8源码解析 -- HashMap(一)
最近一直在忙于项目开发的事情,没有时间去学习一些新知识,但用忙里偷闲的时间把jdk8的hashMap源码看完了,也做了详细的笔记,我会把一些重要知识点分享给大家。大家都知道,HashMap类型也是面试题百分之九十的概率会考到的一种类。如果有人想要看我在源码中的详情笔记的话,可以去我的gitHub上面去下载看(https://github.com/javJoker/jdk8/blob/master/src/main/java/java/util/HashMap.java)。知识在于分享,进步在于学习和讨论,各取所长,这样我们才能更加高效率的学习,这样我们才能走的更远。如果有什么写的不对的地方,也希望大家指出来。在看源码中我也遇到了一些不懂的地方,如果有人知道的话也希望解扰我的困惑。
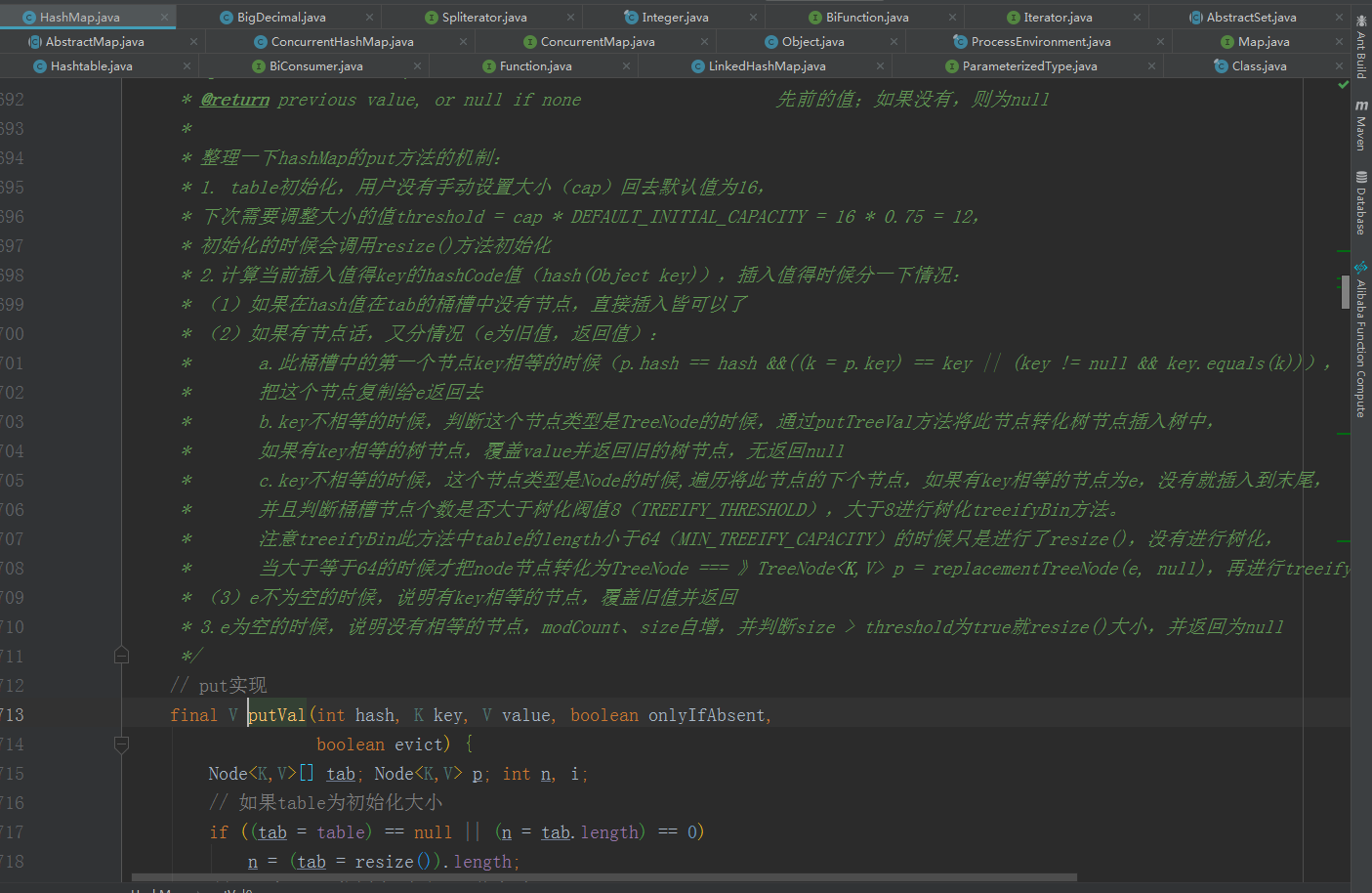
1.HashMap的key、value可以null,并且它也不是线程安全的,它也是无序的,这些要点在hashMap源码的类头上注释部分都可以知道的。那为什么HashMap的key、value可以为null存储到HashMap中去呢?因为在hashMap的put方法没有对这两个进行null值得校验。下面图一为hashMap的putVal方法,其实我们使用的put方法底层调用的就是putVal方法,图二是ConCurrentHashMap的putVal,它会先进行null的校验,key和value为空的时候会跑出异常NullPointerException。图一为:HashMap的putVal方法,图二为:ConcurrentHashMap的putVal方法。

图一
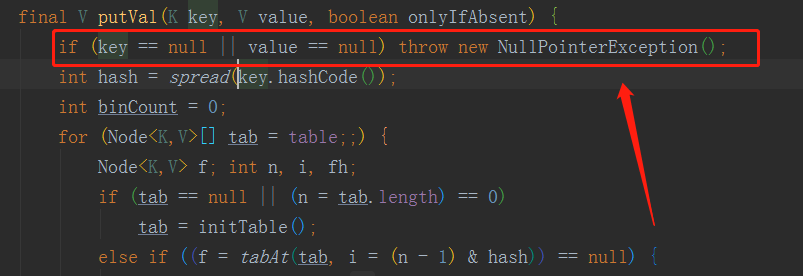
图二
我也整理Map几种子类型中哪些类的key、value可以为null,哪些不可以为null。如下:

2.通过key值获取HashMap中的value的值,hashMap的key和穿过来的参数是通过hashCode值和equals方法比较的,如果你需要声明一个你自己的对象作为hashMap的key的话,需要重写作为key对象的生成hashCode值和equals的方法,这样我们才能通过get方法获取你想要的value的值。说到这里HashMap生成HashCode的方法太机智了,使用2的幂次掩码仅在当前掩码上方的位中变化的哈希集将始终发生冲突,它将哈希的较高位(XOR)扩展为较低,向下传播较高位的影响。这样减少哈希值的碰撞次数,均匀分布在桶里面。

3.我们着重讲hashMap的putVal方法,HashMap的put方法底层调用的是putVal方法,因为许多知识都会在这个方法中展现出来,如hashMap什么时候扩容?什么时候树化(HashMap其实就是Node的节点数组和链表或者红黑树的形式构成的,Node数组我们成为桶,数组中每个节点称为桶槽。树化这个词可以理解为将链表转化为树,链化可以认为是树转化为链表的形式)?注意JDK8之后put的新值是在链表尾部进行插入的,JDK7是在头部进行插入,在此点上面两者不同,至于为什么吗?曾看到过一篇文章说尾部插入可以防止引用链式循环,我也没有明白个所以然来,如果有谁知道的可以留言给我。下面这个图在网上找的,方便大家理解HashMap的结构是怎样的的。
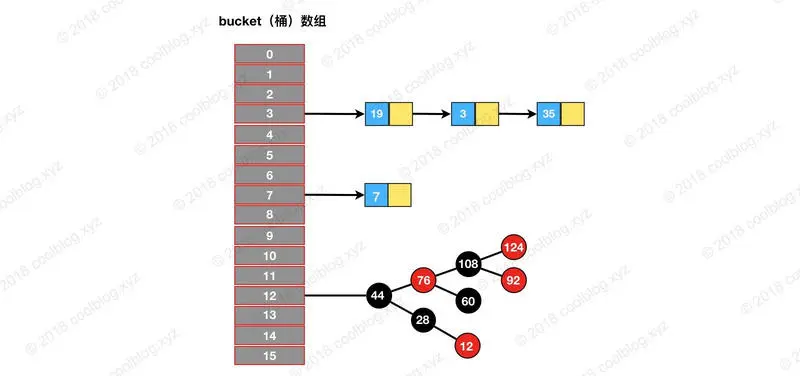
(1)我整理一下hashMap的put方法的机制
a.判断table是否初始化了并且length是否为零,如果未进行初始化,会去调用resize()方法进行初始化大小,用户没有手动设置容器大小(cap)会去使用默认值为16,threshold(是下次需要调整大小的值)为 cap * DEFAULT_INITIAL_CAPACITY = 16 * 0.75 = 12,threshold是和hashMap的size进行比较大小,如果size大于threshold的值就会调用resize()方法进行扩容。resize()之后map的容量大小是原来的2倍(除了初始化的时候),原来的node节点位置可能发生变化,这里需要重新计算index的下标。我们都知道每个node的index值是根据hashCode与容量大小进行取模得到的,这里实在佩服那些大佬想出来的方法,扩容之后不需要重新计算hash值,而是只需要当前节点的hash值与扩容前的容量大小的二进制进行与运算就可以了,因为扩容的容量是原来的2倍,也就是左移一位增加一位数(二进制的时候),扩容之后就是在原来的基础上多一位数,新添加的这位数判断是0还是1就可以决定在新数组上面的位置了,0表示原位置,1表示在原来的位置上加上一个原来数组的长度(原索引+oldCap)。发生HashMap扩容后,遍历hashmap每个桶里的链表,每个链表可能会被拆分成两个链表,不需要移动的元素置入loHead为首的链表,需要移动的元素置入hiHead为首的链表,loHead在新table的原来的index桶槽里面,hiHead则放在新tab的(原索引+oldCap)的桶槽中。如下图:
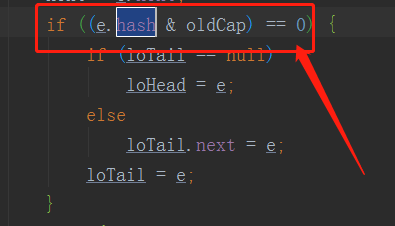
注意如果节点类型Node和TreeNode两者的计算方式有些不同,如果是Node类型的话,说明为链表形式,但是如果TreeNode类型化是树形的,那么就会调用((TreeNode<K,V>)e).split(this, newTab, j, oldCap);这个方法,也是当前桶槽下面遍历所有的树形节点,不需要移动的元素置入loHead
为首的链表,需要移动的元素置入hiHead为首的链表,计算两个链表的node大小,如果小于等于UNTREEIFY_THRESHOLD(值为6)就将树转化为链表,且类型从TreeNode转化为Node类型,如果大于阀值的话需要进行树化。

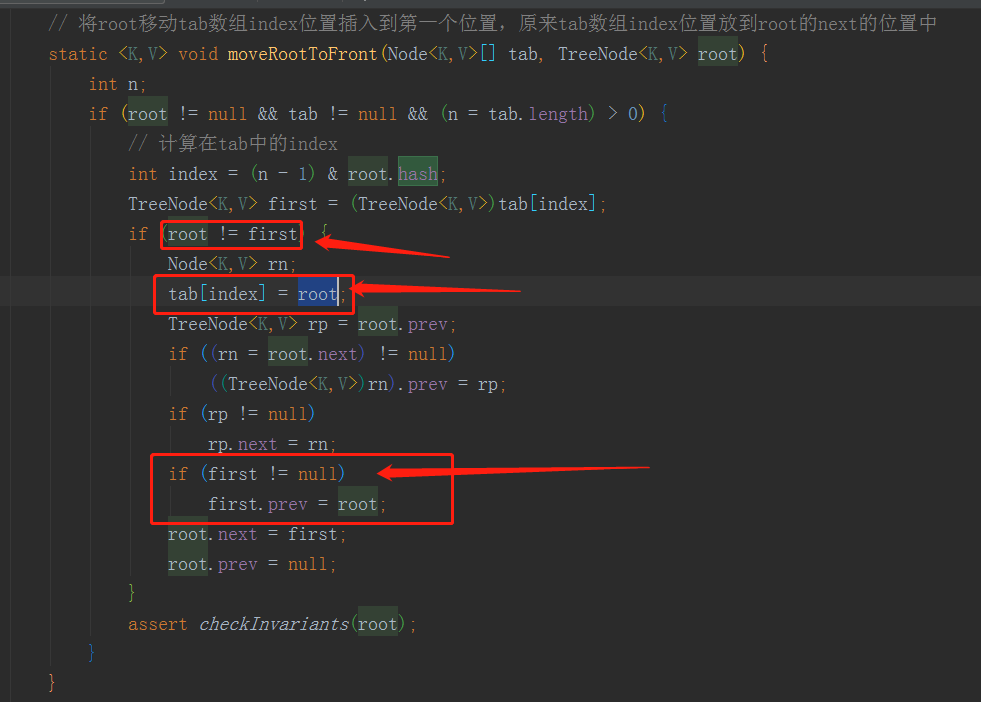
这个treeify()方法中有一个知识点需要说明一下,treeify()方法中调用了moveRootToFront(tab, root)里面是将root移动tab数组index位置插入到第一个位置,原来tab数组index位置放到root的next的位置中,而不是把需要插入index的root和tab中index位置的原来的数据一起进行
树化重排序之后插入到index的位置上面。
b.计算当前插入值得key的hashCode值(hash(Object key)),插入值得时候分一下情况:
1)如果在hash值在tab的桶槽中没有节点,直接插入就可以了
2)如果有节点话,又分情况,返回值为key对应的旧值(e为旧值):
aa.此桶槽中的第一个节点key相等的时候,判断条件p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k)),这里先比较比较hash值是否相等,再进行比较key((k = p.key) == key判断key是不是指向同一块内存, (key != null && key.equals(k)是key不指向同一块内存key不为空的时候判断值是不是相等),为True的时候把这个节点复制给e返回去
ab.第一个节点的key不相等的时候,判断这个节点类型是TreeNode的时候,通过putTreeVal方法将此节点转化树节点插入树中, 如果有key相等的树节点,覆盖value并返回旧的树节点,否则返回null,putTreeVal()方法有一个细节,key不仅通过了
((pk = p.key) == k || (k != null && k.equals(pk)))判断是否相等,还判断key是否实现了Comparable比较方法,实现了还用这个方法判断key的大小。

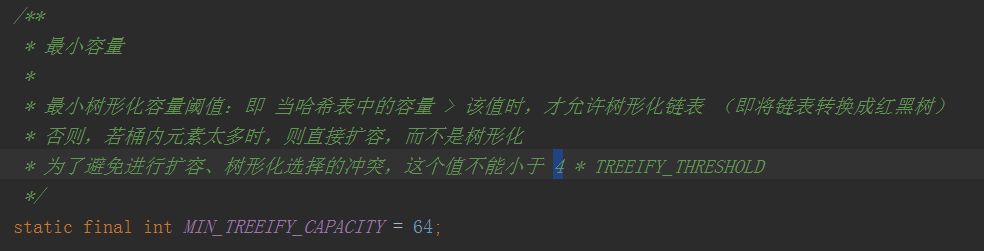
ac.第一个节点的key不相等的时候,这个节点类型是Node的时候,遍历此节点的下个节点,如果有key相等的节点则赋值给e,没有的话就插入到末尾,并且判断桶槽节点个数是否大于树化阀值8(TREEIFY_THRESHOLD),大于8(其实是第九个节点进行树化,下标从0开始,新添加的节点后此次循环中计算器未加一)进行树化treeifyBin方法,下图一。注意treeifyBin此方法中table的length小于64(MIN_TREEIFY_CAPACITY,下图二)的时候只是进行了resize(),没有进行树化,当大于等于64的时候才把node节点转化为TreeNode === 》TreeNode<K,V> p = replacementTreeNode(e, null),再进行treeify树化。

图一
图二
3)e不为空的时候,说明有key相等的节点,覆盖旧值并返回
c.执行下面的步骤说明e为空的时候,没有相等的节点,就是把这个key、value当做新增到map中去,modCount、size自增,并判断size > threshold为true就resize()大小,并返回为null
HashMap先讲到这里,还有一些内容没有介绍,我会出第二篇关于HashMap。我怕写的内容太多了,大家不容易消化掉。大家先把上面的知识点消化消化吧,我认为上面写的每一个都是知识点。如果你去面试的话,上面每个点都可能作为考点被问到,即使没有被问到,你也可以在面试到hashMap的时候,自己进行扩展,可能面试官自己都不知道,比如说大部分的人都知道转化为链表和转化为树的阀值为6和8,但是有谁知道64这个数字呢,hashMap的size不大于等于64,桶槽下面的链表不会进行树化,只是进行扩容而已,链表转化为树的阀值是8,其实是节点为第9个的时候才会调用树化的方法。
最新文章
- 好用的开源爬虫 jsoup
- Tomcat:云环境下的Tomcat设计思路——Tomcat的多实例安装
- C# 用正则表达式替换字符串中所有特殊字符
- android 在标题栏加上按钮
- 携手 Google 和 Docker 为 Microsoft Azure 带来全新的开源容器技术
- [Jobdu] 题目1517:链表中倒数第k个结点
- linux find命令强大之处
- Nginx日志配置及日志切割
- 《JavaScript DOM 编程艺术》
- ehcache-----在spring和hibernate下管理ehcache和query cache
- Why you should QC your reads AND your assembly?
- 再说Postgres中的高速缓存(cache)
- Fiddler 接口测试(Composer)的使用方法及并发测试
- js 去掉数组对象中的重复对象
- struts2的java.lang.NoSuchMethodException错误
- cookie与sessionStorage机制
- CentOS7.4下部署hadoop3.1.1
- 【Python】动手分析天猫内衣售卖数据,得到你想知道的信息
- 平衡树及笛卡尔树讲解(旋转treap,非旋转treap,splay,替罪羊树及可持久化)
- 玩魔兽争霸无故退出 提示框显示"0x21101663"指令引用的"0x02704acc"内存该存不能为"read" 确定就会终止程序