【Dubbo】带着问题看源码:什么是SPI机制?Dubbo是如何实现的?
什么是SPI?
在Java中,SPI全称为 Service Provider Interface,是一种典型的面向接口编程机制。定义通用接口,然后具体实现可以动态替换,和 IoC 有异曲同工之妙。
Java SPI 实现DEMO
定义一个接口
public interface Human {
String sayHello();
}
定义两个实现类
public class American implements Human {
@Override
public String sayHello() {
return "Hello,I'm American";
}
} public class Chinese implements Human {
@Override
public String sayHello() {
return "你好,我是中国人";
}
}
新建 接口全名文件,例如本例: com.xx.spi.Human,放到META-INF/services路径下,文件内容为实现类的全名,不同实现类之前换行。
com.xx.spi.American
com.xx.spi.Chinese
编码测试
public class SpiApplication { public static void main(String[] args) { ServiceLoader<Human> humans = ServiceLoader.load(Human.class); for (Human human : humans) {
System.out.println(human.sayHello());
}
}
}
Java SPI 源码解析
ServiceLoader 提供了静态方法 load(Class<S> service),本质上还是要new一个新的实例,调用私有构造方法 ServiceLoader(Class<S> svc, ClassLoader cl).
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
// 此时的 cl 为 Thread.currentThread().getContextClassLoader();
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
初始化 内部 LazyIterator
public void reload() {
// Cached providers, in instantiation order
//private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
//先清空缓存
providers.clear();
//重新初始化 lazyIterator ,此时对象还没有被创建
lookupIterator = new LazyIterator(service, loader);
}
ServiceLoader 本身实现了 Iterable 接口。遍历时会获取 iterator.
public Iterator<S> iterator() {
return new Iterator<S>() {
//已经缓存的列表
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
//先从缓存中找
if (knownProviders.hasNext())
return true;
//缓存 MISS ,调用内部 LazyIterator.hasNext()
return lookupIterator.hasNext();
}
public S next() {
//缓存中存在,直接返回
if (knownProviders.hasNext())
return knownProviders.next().getValue();
//缓存 MISS,调用内部 LazyIterator.next()
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
LazyIterator#next()
public S next() {
if (acc == null) {
//查找下一个 Service
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
LazyIterator#hasNextService()
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
//查找文件 META-INF/services/com.xx.spi.Human
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
//没有更多元素,遍历结束
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
//给下一个名称赋值
nextName = pending.next();
return true;
}
LazyIterator#nextService()
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
//调用完 hasNextService 方法之后,nextName 更新
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
//获取 Class
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
//判断类是否继承指定接口
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
//反射创建对象
S p = service.cast(c.newInstance());
//加入缓存,下次访问直接访问缓存
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
小结
可以看出在Java SPI的实现中,核心代码就是反射创建对象实例。经典的实际应用中可以参考 JDBC的Driver实现。这里不在赘述。
在 Dubbo相关官方博客 介绍了它的缺点:
- 需要遍历所有的实现,并实例化,然后我们在循环中才能找到我们需要的实现。
- 配置文件中只是简单的列出了所有的扩展实现,而没有给他们命名。导致在程序中很难去准确的引用它们。
- 扩展如果依赖其他的扩展,做不到自动注入和装配
- 不提供类似于Spring的IOC和AOP功能
- 扩展很难和其他的框架集成,比如扩展里面依赖了一个Spring bean,原生的Java SPI不支持
Dubbo SPI 实现DEMO
定义一个接口,添加
@SPI注解@SPI("human")
public interface Human {
@Adaptive
String sayHello(URL url);
}
定义两个实现类
public class American implements Human {
@Override
public String sayHello(URL url) {
return "Hello,I'm American";
}
} public class Chinese implements Human {
@Override
public String sayHello(URL url) {
return "你好,我是中国人";
}
}
新建 接口全名文件,例如本例: com.xx.spi.Human,放到META-INF/dubbo/internal路径下,文件内容为key=value 形式。
//默认实现
human=com.xx.spi.Chinese
//中国
cn=com.xx.spi.Chinese
//美国
en=com.xx.spi.American
编码测试
public class DubboSpiApplication { public static void main(String[] args) {
//根据 human 参数动态获取实现类
URL url = URL.valueOf("test://localhost/test?human=en");
Human humanDefault = ExtensionLoader.getExtensionLoader(Human.class).getDefaultExtension();
Human humanAdaptive = ExtensionLoader.getExtensionLoader(Human.class).getAdaptiveExtension(); //default
System.out.println(humanDefault.sayHello(url));
//adaptive
System.out.println(humanAdaptive.sayHello(url));
}
}
Dubbo SPI 源码解析
ExtensionLoader
ExtensionLoader内置了各种不同的缓存,以提高性能,所以在后续的代码中会将缓存判断的地方去掉,只保留核心代码
//缓存 ExtensionLoader 实例,每个 Class<?> 对应一个,静态方法 getExtensionLoader 即从该缓存中获取
private static final ConcurrentMap<Class<?>, ExtensionLoader<?>> EXTENSION_LOADERS = new ConcurrentHashMap<>();
private final ConcurrentMap<Class<?>, String> cachedNames = new ConcurrentHashMap<>();
//缓存 配置文件中的 key value 对象.
private final Holder<Map<String, Class<?>>> cachedClasses = new Holder<>();
private final Map<String, Object> cachedActivates = new ConcurrentHashMap<>();
private final ConcurrentMap<String, Holder<Object>> cachedInstances = new ConcurrentHashMap<>();
private final Holder<Object> cachedAdaptiveInstance = new Holder<>();
private volatile Class<?> cachedAdaptiveClass = null;
ExtensionLoader# getDefaultExtension()
public T getDefaultExtension() {
//做准备工作,扫描配置文件,提取类信息等
getExtensionClasses();
//获取类实例
return getExtension(cachedDefaultName);
}
ExtensionLoader# getExtensionClasses()
private Map<String, Class<?>> getExtensionClasses() {
//省略其他缓存判断和加锁代码,其实就是调用此方法,然后放入 cachedClasses 中
return loadExtensionClasses();
}
ExtensionLoader#loadExtensionClasses()
private Map<String, Class<?>> loadExtensionClasses() {
//解析默认名称 例如 @SPI("human") 中的human
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
//从 META-INF/dubbo/internal/ 目录下加载
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY, type.getName());
//从 META-INF/dubbo/internal/ 目录下加载 内置的类,例如ExtensionFactory
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY, type.getName().replace("org.apache", "com.alibaba"));
//从 META-INF/dubbo/ 目录下加载
loadDirectory(extensionClasses, DUBBO_DIRECTORY, type.getName());
loadDirectory(extensionClasses, DUBBO_DIRECTORY, type.getName().replace("org.apache", "com.alibaba"));
//从 META-INF/services/ 目录下加载,兼容Java SPI 方式
loadDirectory(extensionClasses, SERVICES_DIRECTORY, type.getName());
loadDirectory(extensionClasses, SERVICES_DIRECTORY, type.getName().replace("org.apache", "com.alibaba"));
return extensionClasses;
}
ExtensionLoader#loadResource()
private void loadResource(Map<String, Class<?>> extensionClasses, ClassLoader classLoader, java.net.URL resourceURL) {
try {
//读取文件
try (BufferedReader reader = new BufferedReader(new InputStreamReader(resourceURL.openStream(), StandardCharsets.UTF_8))) {
String line;
while ((line = reader.readLine()) != null) {
final int ci = line.indexOf('#');
if (ci >= 0) {
line = line.substring(0, ci);
}
line = line.trim();
if (line.length() > 0) {
try {
String name = null;
int i = line.indexOf('=');
if (i > 0) {
//解析出 key value ,key为别名 value 为类的全名
name = line.substring(0, i).trim();
line = line.substring(i + 1).trim();
}
if (line.length() > 0) {
loadClass(extensionClasses, resourceURL, Class.forName(line, true, classLoader), name);
}
}
//...其他代码
}
此时,cachedClasses 已经存放若干类信息。
ExtensionLoader#getExtension()
public T getExtension(String name) {
//忽略缓存部分代码,核心就是调用此方法进行类的实例化
return (T)createExtension(name);
}
ExtensionLoader#createExtension()
private T createExtension(String name) {
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
//从缓存获取实例对象
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
//缓存MISS,调用 newInstance() 方法实例化,存入缓存
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
//做后续的注入工作(下文解析)
injectExtension(instance);
//包装类构造函数注入(下文解析)
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (CollectionUtils.isNotEmpty(wrapperClasses)) {
for (Class<?> wrapperClass : wrapperClasses) {
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
return instance;
} catch (Throwable t) {
}
}
所以到了这一步,就很明了了,其实核心代码还是通过反射的方式newInstance创建对象实例,然后存入缓存。但是后续又做了一些注入工作。功能性要比 JAVA SPI丰富一些。
ExtensionLoader#injectExtension()
private T injectExtension(T instance) {
try {
if (objectFactory != null) {
//遍历所有的方法
for (Method method : instance.getClass().getMethods()) {
//如果是set方法
if (isSetter(method)) {
//方法存在 DisableInject 注解,不注入
if (method.getAnnotation(DisableInject.class) != null) {
continue;
}
//获取参数类型
Class<?> pt = method.getParameterTypes()[0];
//如果是基本类型的参数,跳过
if (ReflectUtils.isPrimitives(pt)) {
continue;
}
try {
//获取属性名称
String property = getSetterProperty(method);
//通过 Factory 获取 扩展实例。
Object object = objectFactory.getExtension(pt, property);
//获取到了就执行 set 方法
if (object != null) {
method.invoke(instance, object);
}
} catch (Exception e) {
logger.error("Failed to inject via method " + method.getName()
+ " of interface " + type.getName() + ": " + e.getMessage(), e);
}
}
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
return instance;
}
ExtensionLoader#getAdaptiveExtension()
public T getAdaptiveExtension() {
//除去其他判断代码,核心方法
return (T)createAdaptiveExtension();
}
ExtensionLoader#createAdaptiveExtension()
private T createAdaptiveExtension() {
//忽略 injectExtension方法,主要是看AdaptiveExtensionClass如何获取
return injectExtension((T) getAdaptiveExtensionClass().newInstance());
}
ExtensionLoader#getAdaptiveExtensionClass()
private Class<?> getAdaptiveExtensionClass() {
//同样,先加载类信息
getExtensionClasses();
//读取缓存
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}
// 创建
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}
ExtensionLoader#createAdaptiveExtensionClass()
这个方法比较有意思,会动态创建一个新的类,类名 Class$Adaptive.
private Class<?> createAdaptiveExtensionClass() {
//生成类的字符串代码
String code = new AdaptiveClassCodeGenerator(type, cachedDefaultName).generate();
ClassLoader classLoader = findClassLoader();
//获取内置的 Compiler,它也是通过 ExtensionLoader 生成的实例,可以通过修改配置 <dubbo:application compiler="jdk"/> 选择使用哪一种。Dubbo支持 JDK,Javassist,AdaptiveCompiler
org.apache.dubbo.common.compiler.Compiler compiler = ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();
//编译生成类
return compiler.compile(code, classLoader);
}
默认使用 javassist
@SPI("javassist")
public interface Compiler {
/**
* Compile java source code.
*
* @param code Java source code
* @param classLoader classloader
* @return Compiled class
*/
Class<?> compile(String code, ClassLoader classLoader);
}
类结构图如下:
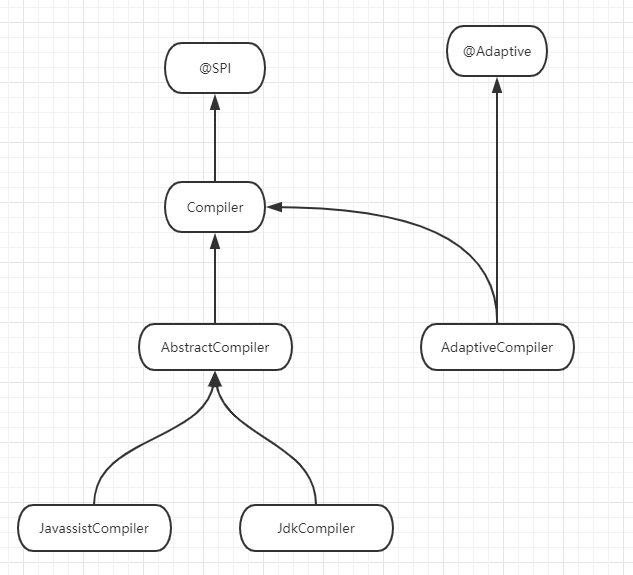
JavassistCompiler 和 JdkCompiler 是真正做事的,而AdaptiveCompiler则是为了实现动态选择编译器而生的。
@Override
public Class<?> compile(String code, ClassLoader classLoader) {
Compiler compiler;
ExtensionLoader<Compiler> loader = ExtensionLoader.getExtensionLoader(Compiler.class);
String name = DEFAULT_COMPILER; // copy reference
if (name != null && name.length() > 0) {
//根据 name 获取编译器
compiler = loader.getExtension(name);
} else {
//获取默认编译器,即 @SPI 注解标明的编译器,默认是 javassist
compiler = loader.getDefaultExtension();
}
return compiler.compile(code, classLoader);
}
那么,编译器编译的代码是什么呢?我将代码格式稍微整理了一下
//包名
package com.xx.spi;
//导入
import org.apache.dubbo.common.extension.ExtensionLoader;
//生成的类名 ClassName+ $ + Adaptive
public class Human$Adaptive implements com.fanpan26.jls.spi.Human {
public java.lang.String sayHello(org.apache.dubbo.common.URL arg0) {
//参数校验
if (arg0 == null) throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg0;
//获取参数
String extName = url.getParameter("human", "human");
//如果没有获取到,说明配置文件里没有,抛出异常
if (extName == null) {
throw new IllegalStateException("Failed to get extension (com.fanpan26.jls.spi.Human) name from url (" + url.toString() + ") use keys([human])");
}
//最终还是调用了 getExtension(String name); 方法获取实例
com.fanpan26.jls.spi.Human extension = ExtensionLoader.getExtensionLoader(com.fanpan26.jls.spi.Human.class).getExtension(extName);
//最后调用该实例的方法
return extension.sayHello(arg0);
}
}
所以,到此为止, getExtension(String name) 是个核心方法,很多地方都会用到他。即便是 Adaptive类,最终生成的类方法中也是调用了该方法。
ExtensionLoader#getActivateExtension()
此方法也是大同小异,不在赘述。
总结
简单的做了一下 JAVA SPI 和Dubbo SPI 的代码解析,也有很多细节没有分析。相比于JAVA SPI,Dubbo SPI提供了更加丰富的功能和更高的灵活性。Dubbo SPI 在Dubbo框架中的应用到处可见,所以它的重要性不言而喻。通过代码的编写与调试,让我收获良多。分析不正确的地方还请多多谅解和批评指正。
最新文章
- 解决PKIX(PKIX path building failed) 问题 unable to find valid certification path to requested target
- java 24 - 11 GUI之制作登陆注册页面
- 今天来做一个PHP电影小爬虫。
- PHP 错误处理机制
- IPv6 tutorial – Part 8: Special addresses
- 单篇文章JS模拟分页
- alter database open resetlogs
- NSIS:卸载加密码示例
- iOS View 模糊效果(毛玻璃)
- 如何访问 Service?- 每天5分钟玩转 Docker 容器技术(99)
- iis正确安装了,但是还是无法访问,这是iis和.net安装顺序问题,记录一下
- redis常见错误处理
- ASP.NET MVC和Web API中的Angular2 - 第1部分
- 基于UML的毕业选题系统建模研究
- 利用KMP算法解决串的模式匹配问题(c++) -- 数据结构
- NodeJS错误-throw er; // Unhandled 'error' event
- Python——UnicodeWarning: Unicode equal comparison failed to convert both arguments to Unicode - interpreting them as being unequal
- mybatis调用自定义函数
- mysql系列学习
- ReentrantLock 学习