Cloudera Certified Associate Administrator案例之Test篇
Cloudera Certified Associate Administrator案例之Test篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.准备工作(将CM升级到"60天使用的企业版")
1>.在CM界面中点击"试用Cloudera Enterprise 60天"
2>.进入许可证界面可以看到当前使用的是"Cloudera Express",点击"试用Cloudera Enterprise 60天""
3>.点击确认
4>.进入升级向导,点击"继续"

5>.升级完成
6>.查看CM主界面
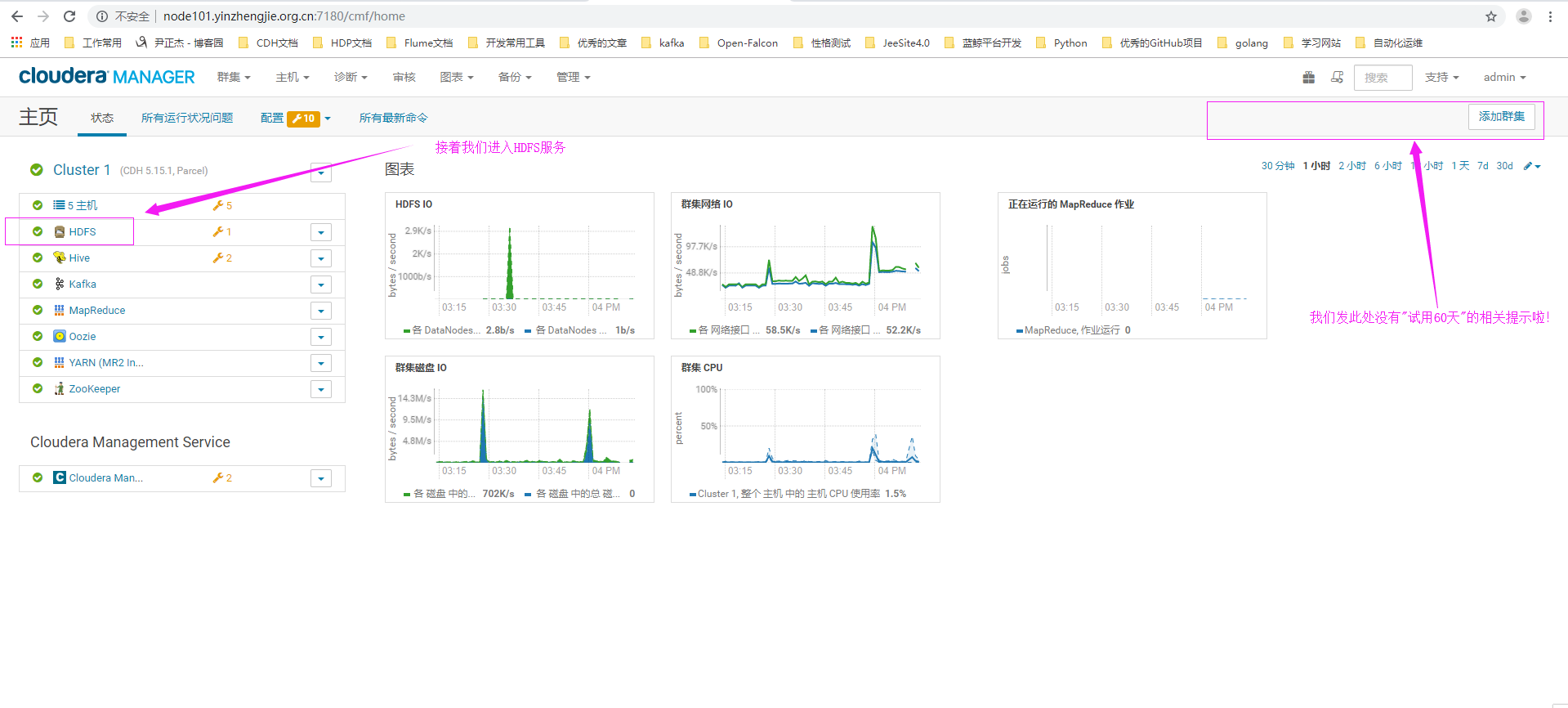
二.使用企业级的CM的快照功能
1>.点击HDFS中的"文件浏览器"
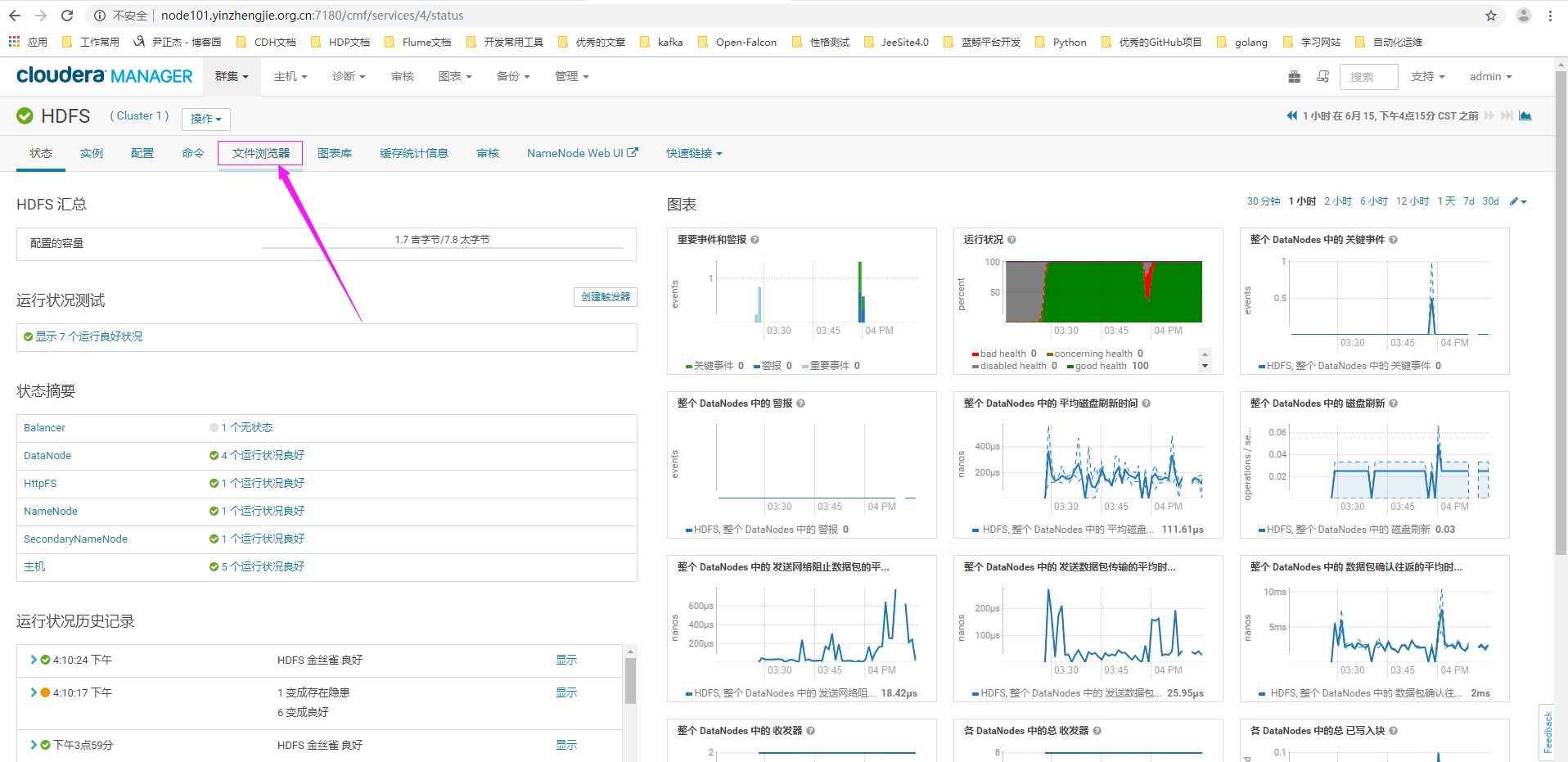
2>.进入我们的测试目录
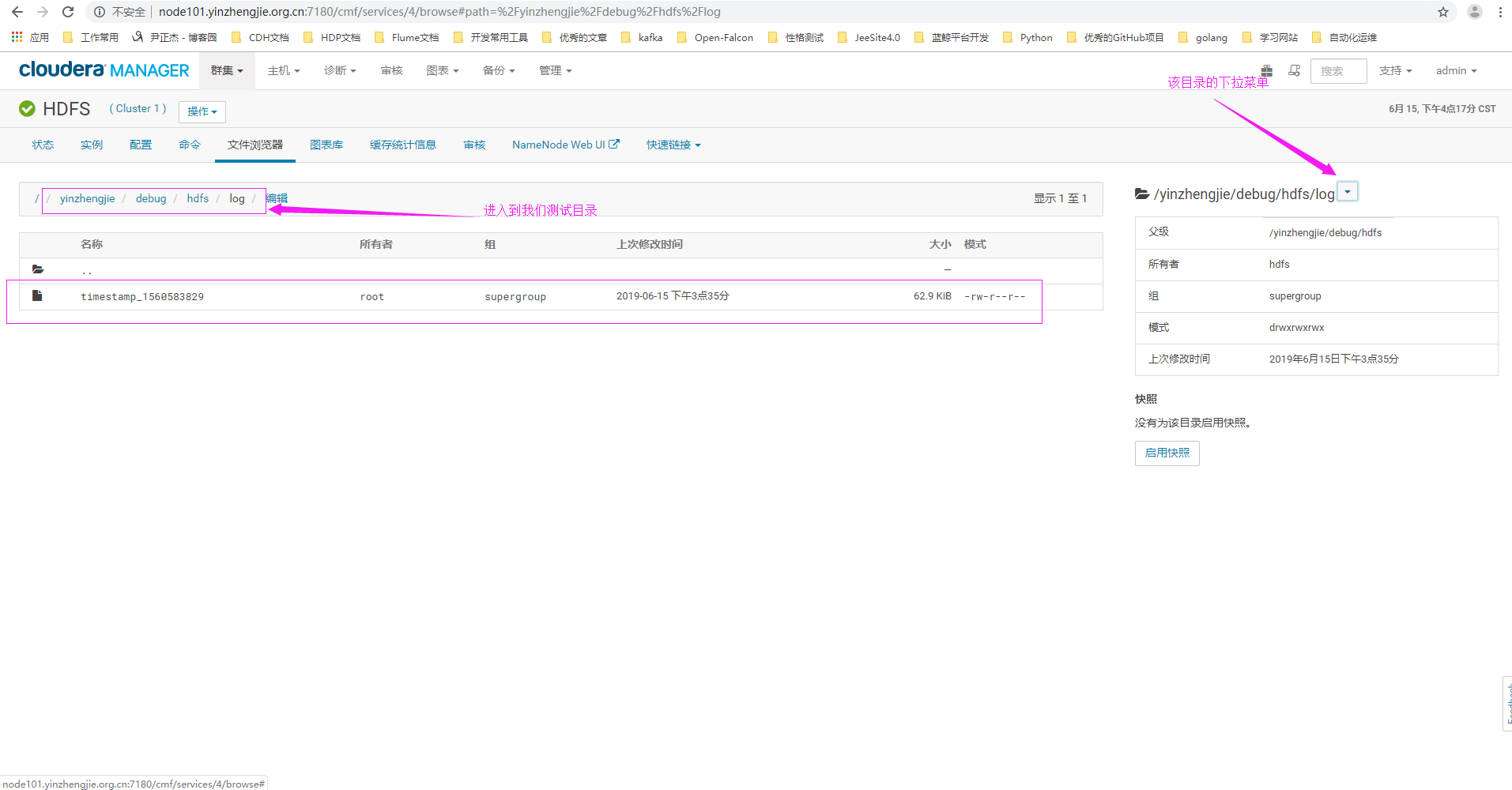
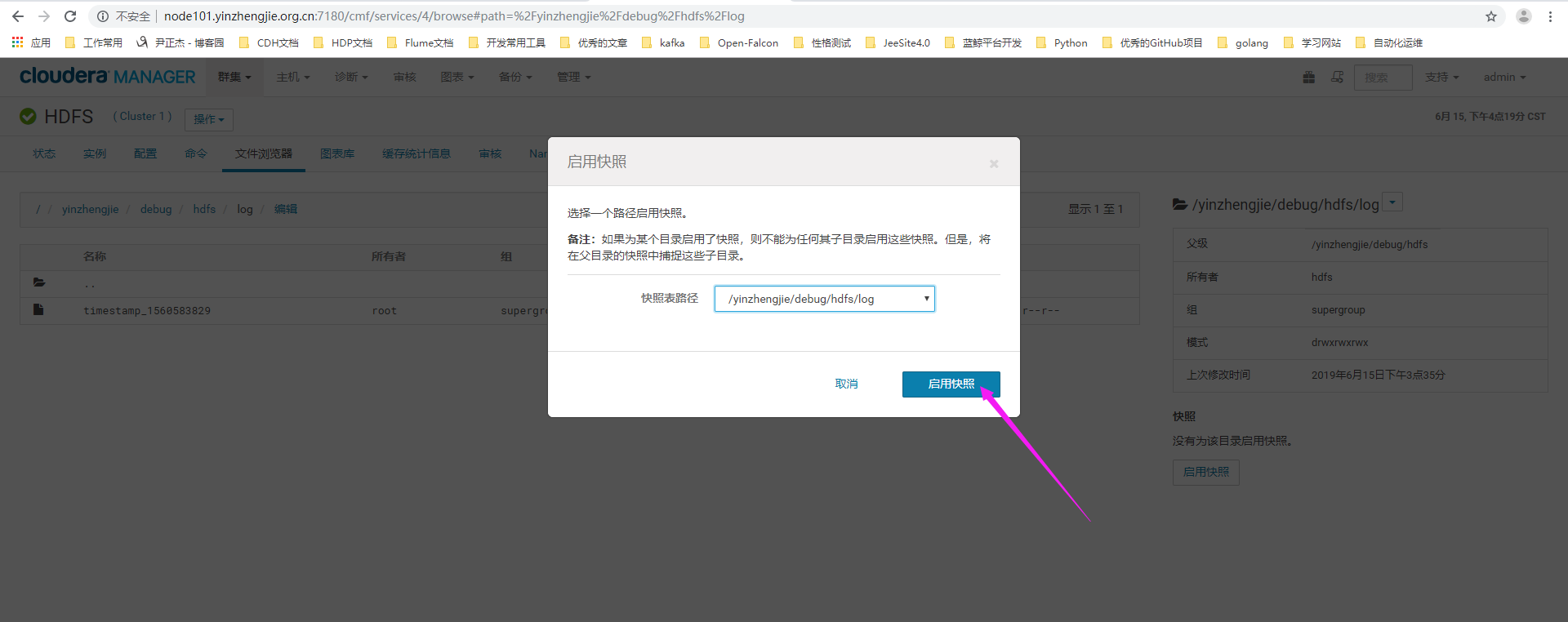
3>.点击启用快照

4>.弹出一个确认对话框,点击"启用快照"
5>.快照启用成功
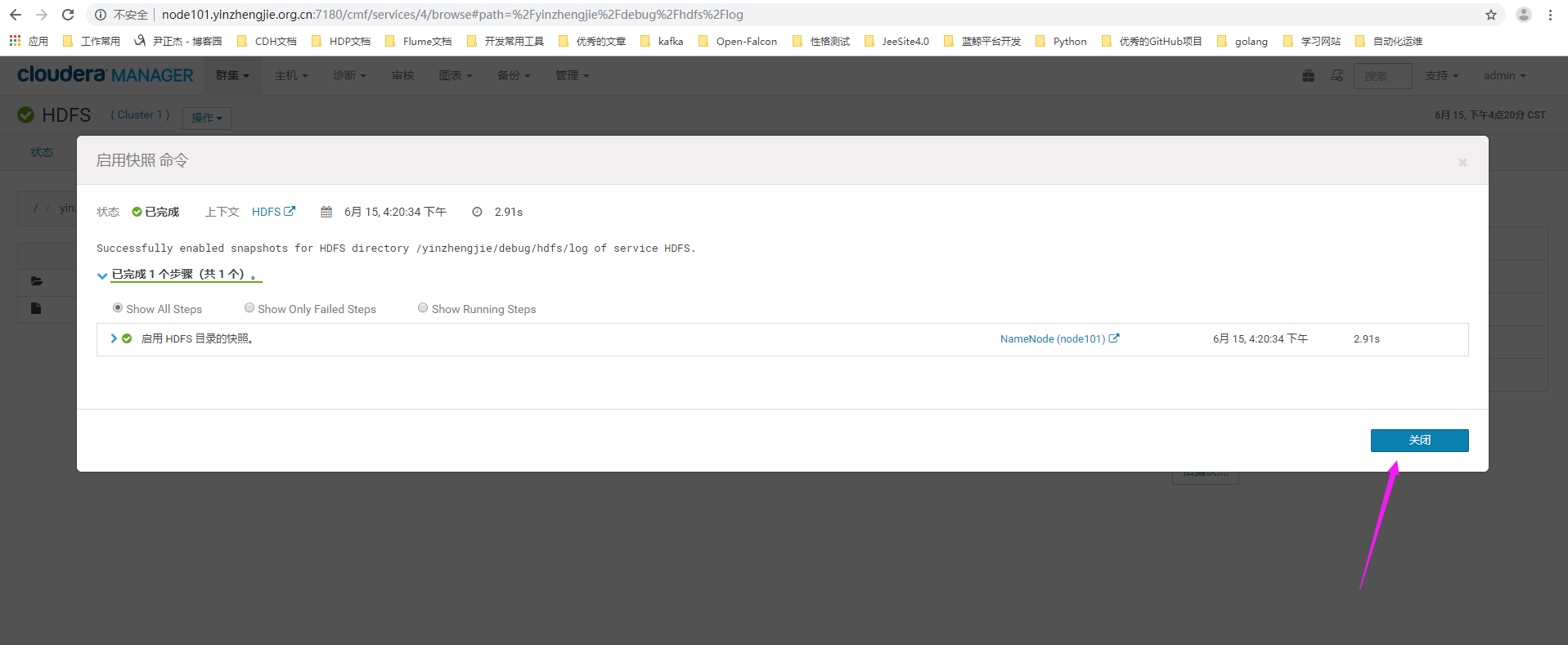
6>.点击拍摄快照

7>.给快照起一个名字
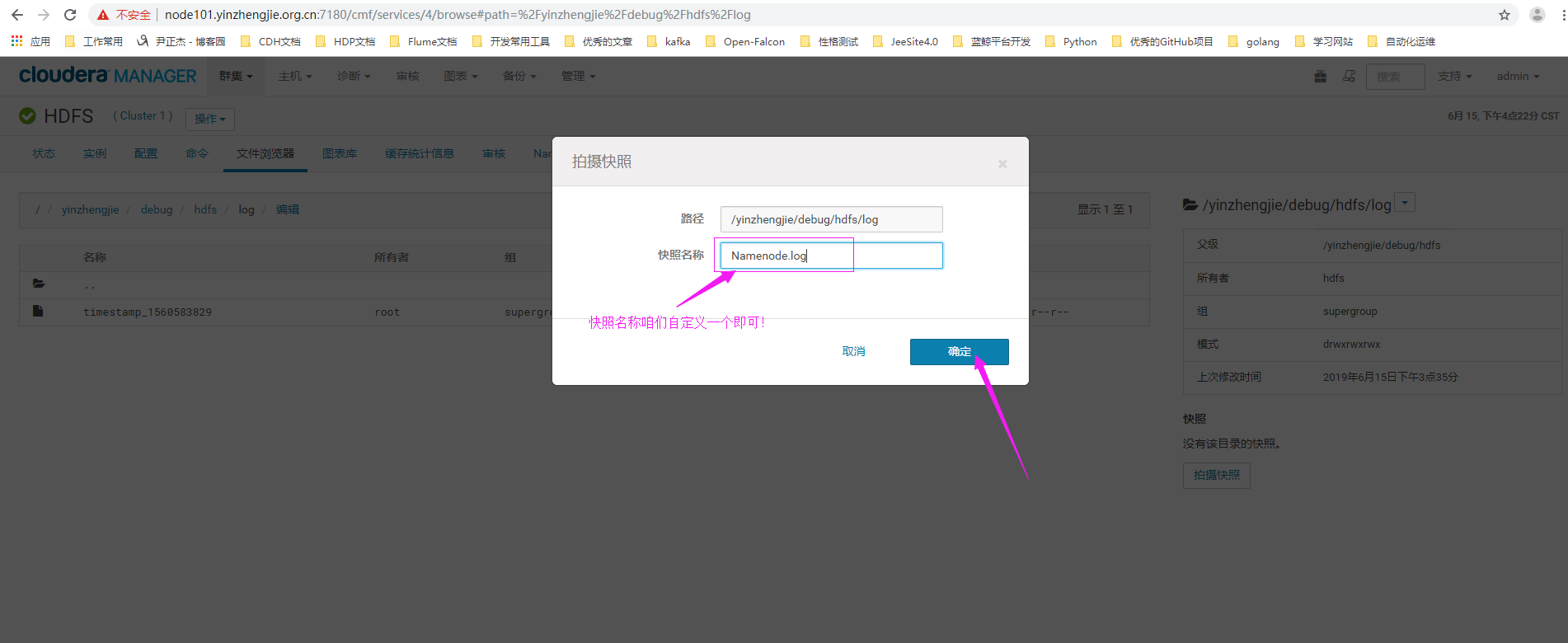
8>.等待快照创建完毕
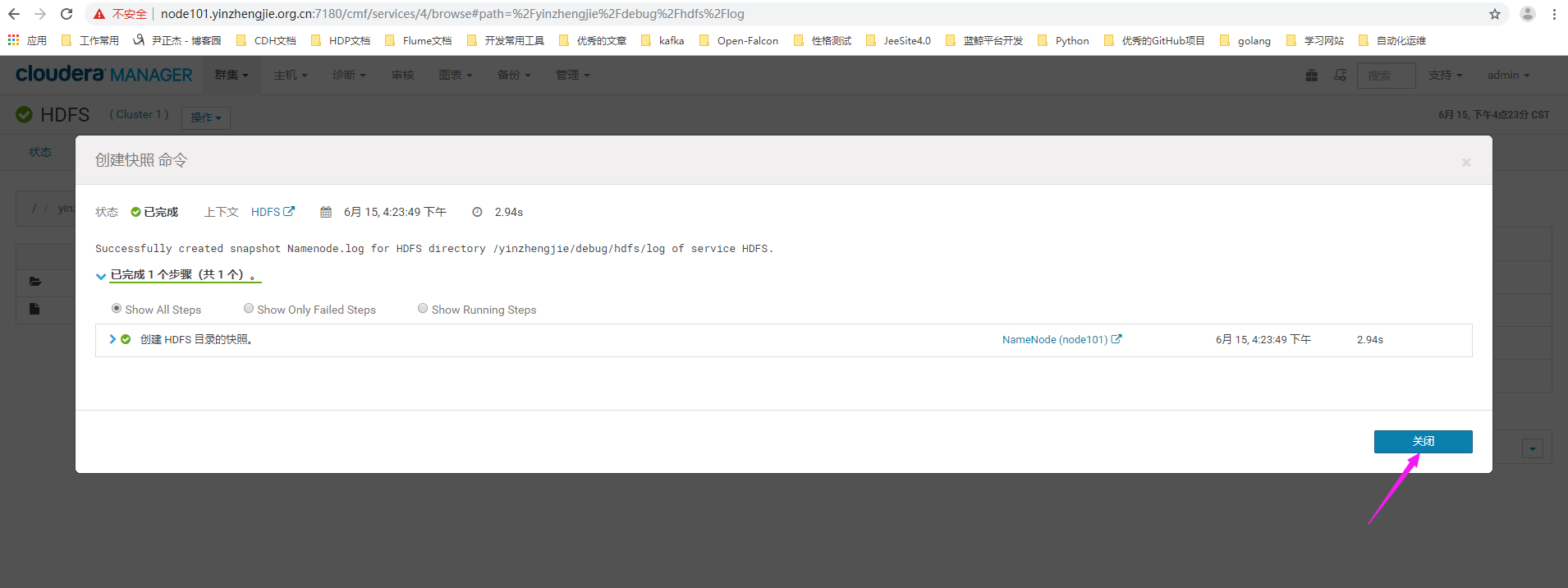
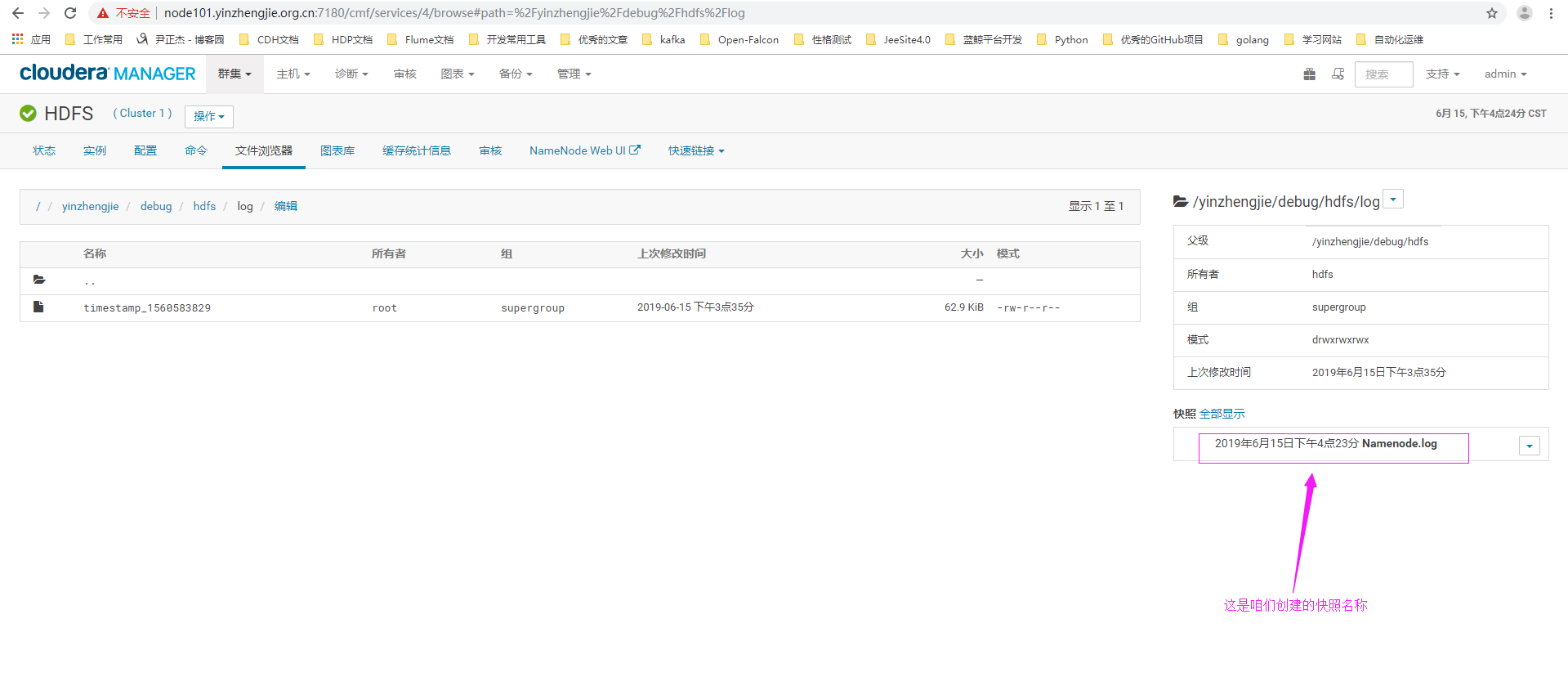
9>.快照创建成功
19>.彻底删除做了快照的文件
[root@node101.yinzhengjie.org.cn ~]# hdfs dfs -ls /yinzhengjie/debug/hdfs/log
Found items
-rw-r--r-- root supergroup -- : /yinzhengjie/debug/hdfs/log/timestamp_1560583829
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# hdfs dfs -rm -skipTrash /yinzhengjie/debug/hdfs/log/timestamp_1560583829
Deleted /yinzhengjie/debug/hdfs/log/timestamp_1560583829
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# hdfs dfs -ls /yinzhengjie/debug/hdfs/log
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# hdfs dfs -rm -skipTrash /yinzhengjie/debug/hdfs/log/timestamp_1560583829 #会跳过回收站

三.使用最近一个快照恢复数据
问题描述:
公司某用户在HDFS上存放了重要的文件,但是不小心将其删除了。幸运的是,该目录被设置为可快照的,并曾经创建过一次快照。请使用最近的一个快照回复数据。
要求恢复"/yinzhengjie/debug/hdfs/log"目录下的所有文件,并恢复文件原有的权限,所有者,ACL等。 解决方案:
快照在操作中日常运维中也是很有用的,不单是用于测试。我之前在博客中有介绍过Hadoop2.9.2版本是如何使用命令行的管理快照的方法,本次我们使用CM来操作。
1>.点击HDFS服务
2>.点击文件浏览器
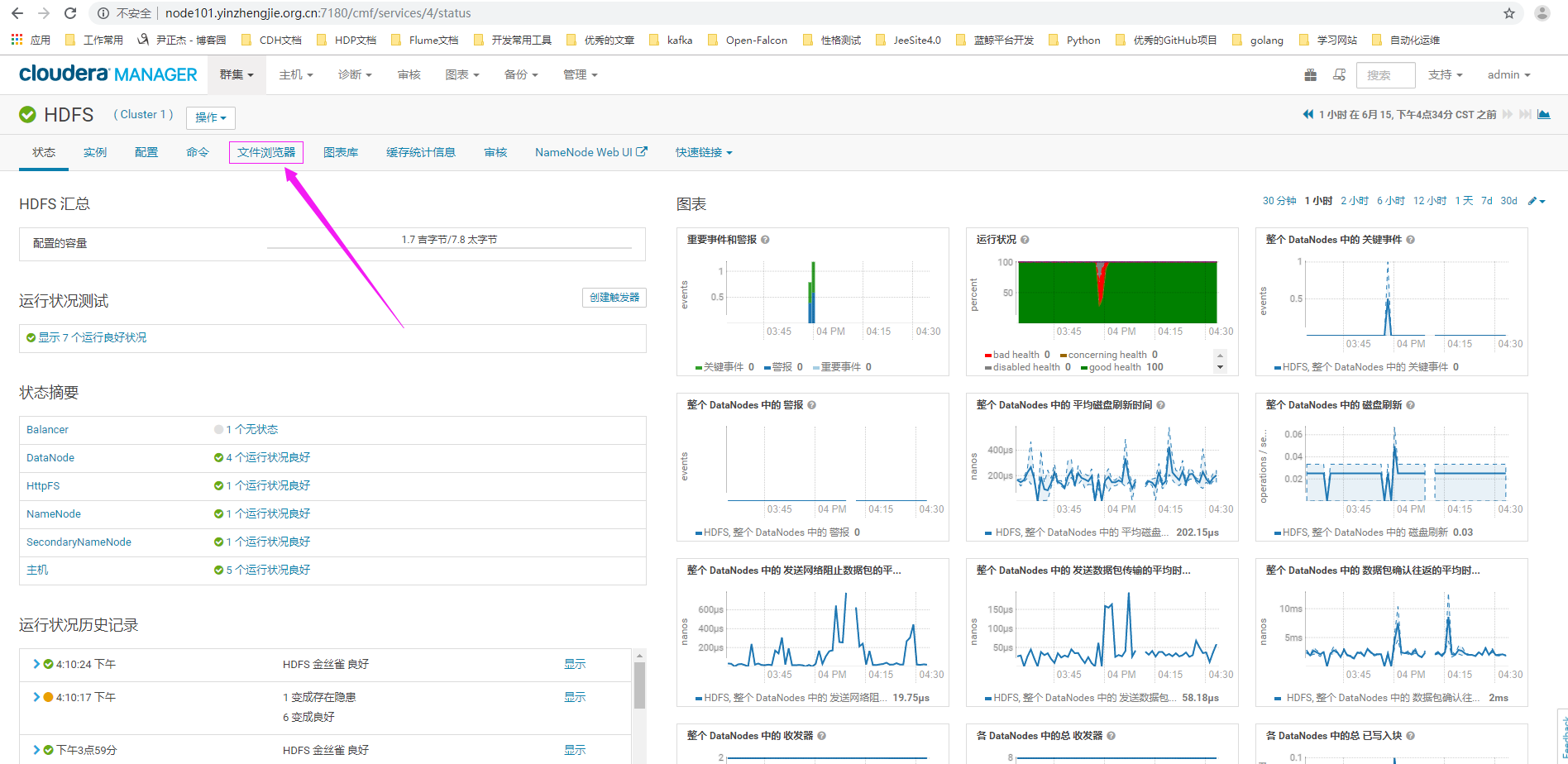
3>.进入我们要还原数据的目录,并点击"从快照还原目录"
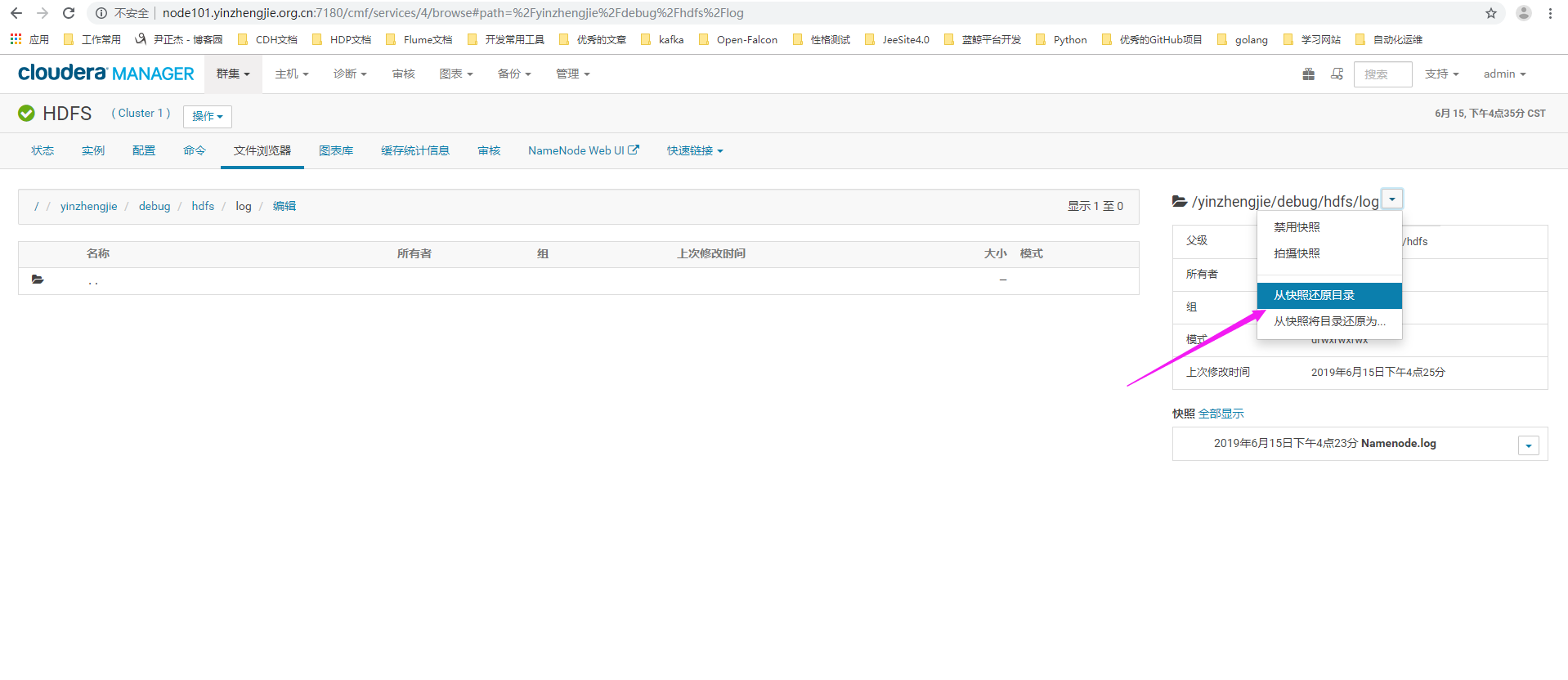
4>.选择快照及恢复的方法
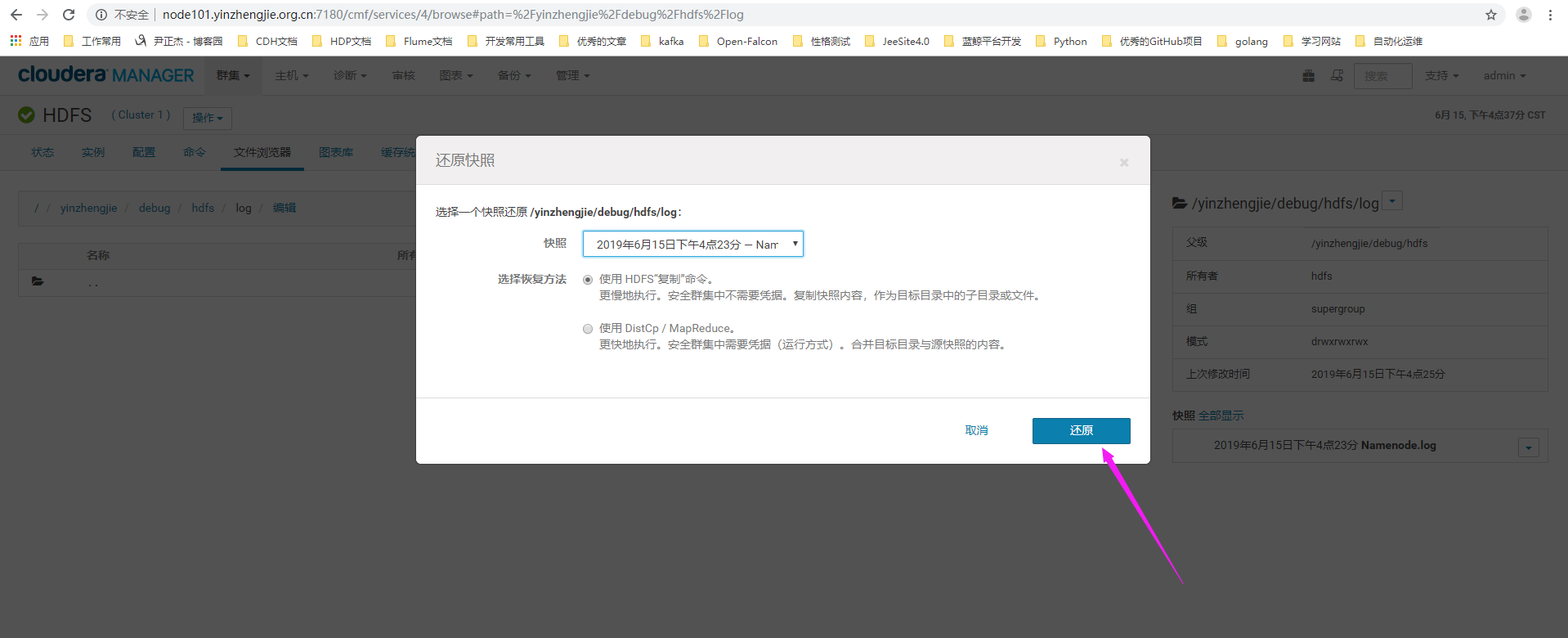
5>.恢复完成,点击"关闭"

6>.刷新当前页面,发现数据恢复成功啦
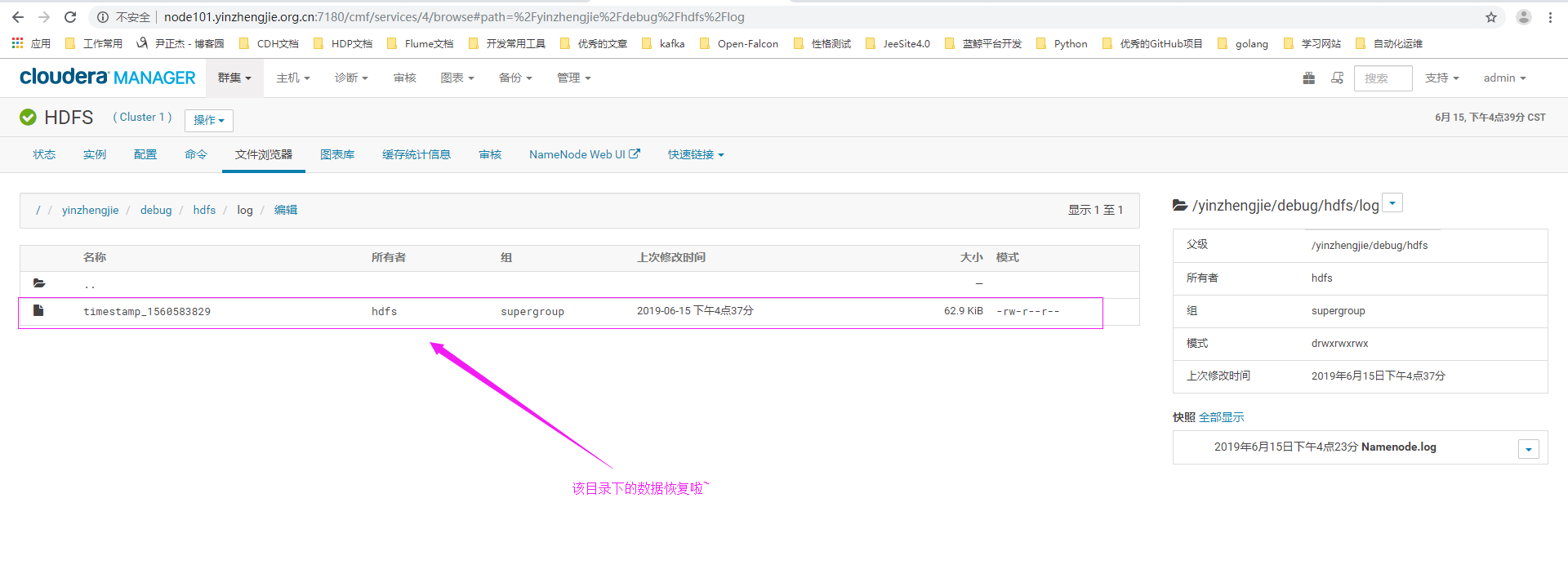
7>.恢复文件权限
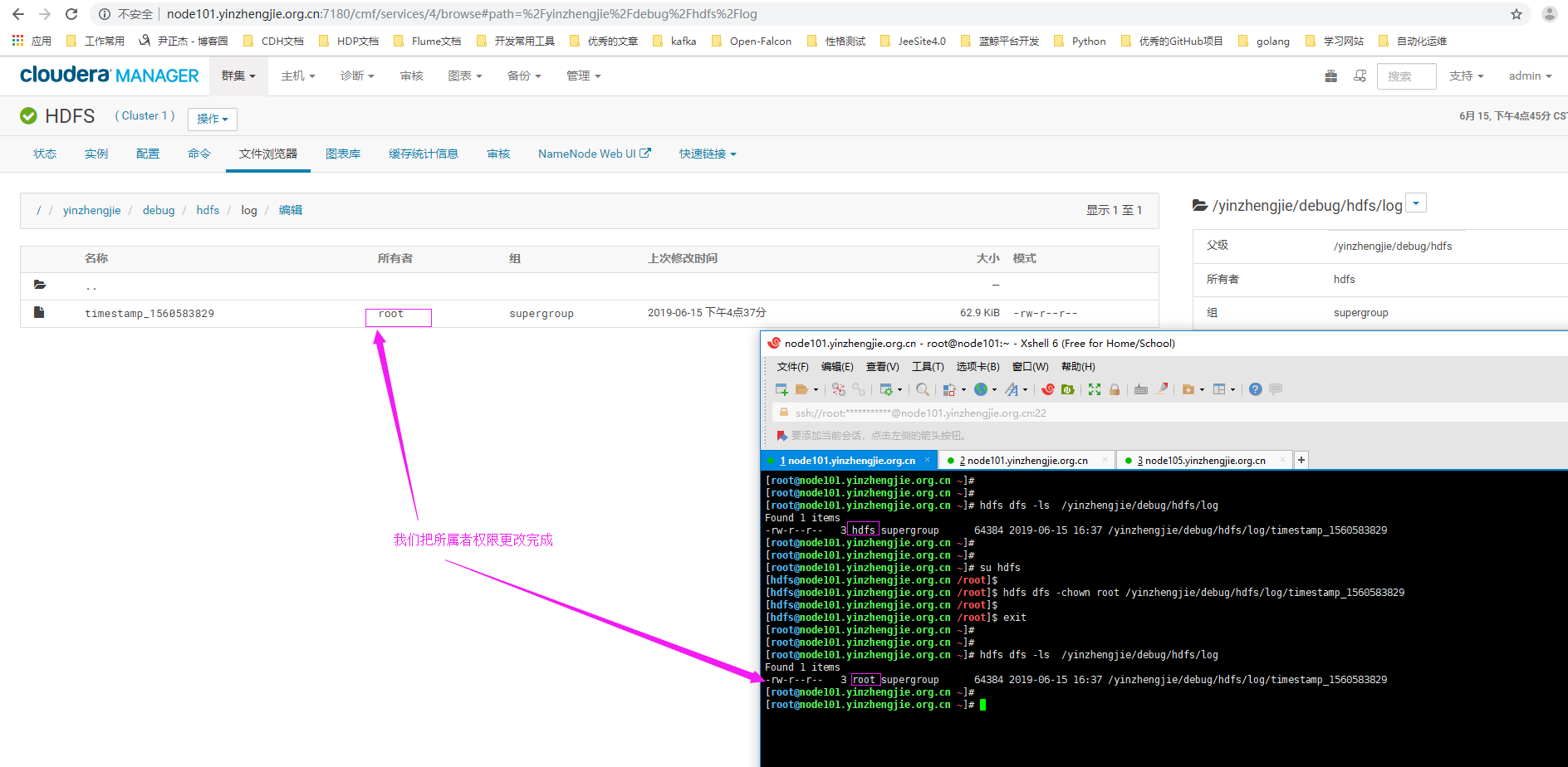
四.运行一个mapreduce进程
问题描述:
公司一个运维人员尝试优化集群,但反而使得一些以前可以运行的MapReduce作业不能运行了。请你识别问题并予以纠正,并成功运行性能测试,要求为在Linux文件系统上找到hadoop-mapreduce-examples.jar包,并使用它完成三步测试:
>.使用teragen /user/yinzhengjie/data/day001/test_input 生成10000000行测试记录并输出到指定目录
>.使用terasort /user/yinzhengjie/data/day001/test_input /user/yinzhengjie/data/day001/test_output 进行排序并输出到指定目录
>.使用teravalidate /user/yinzhengjie/data/day001/test_output /user/yinzhengjie/data/day001/ts_validate检查输出结果 解决方案:
需要对MapReduce作业的常见错误会排查。按照上述操作执行即可,遇到问题自行处理。
1>.生成输入数据
[root@node101.yinzhengjie.org.cn ~]# find / -name hadoop-mapreduce-examples.jar
/opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# cd /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teragen /user/yinzhengjie/data/day001/test_input
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teragen /user/yinzhengjie/data/day001/test_input
// :: INFO terasort.TeraGen: Generating using
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1558520562958_0001
// :: INFO impl.YarnClientImpl: Submitted application application_1558520562958_0001
// :: INFO mapreduce.Job: The url to track the job: http://node101.yinzhengjie.org.cn:8088/proxy/application_1558520562958_0001/
// :: INFO mapreduce.Job: Running job: job_1558520562958_0001
// :: INFO mapreduce.Job: Job job_1558520562958_0001 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1558520562958_0001 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Other local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total vcore-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all map tasks=
Map-Reduce Framework
Map input records=
Map output records=
Input split bytes=
Spilled Records=
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
org.apache.hadoop.examples.terasort.TeraGen$Counters
CHECKSUM=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teragen 10000000 /user/yinzhengjie/data/day001/test_input
2>.排序和输出
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# pwd
/opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar terasort /user/yinzhengjie/data/day001/test_input /user/yinzhengjie/data/day001/test_output
// :: INFO terasort.TeraSort: starting
// :: INFO input.FileInputFormat: Total input paths to process :
Spent 151ms computing base-splits.
Spent 3ms computing TeraScheduler splits.
Computing input splits took 155ms
Sampling splits of
Making from sampled records
Computing parititions took 1019ms
Spent 1178ms computing partitions.
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1558520562958_0002
// :: INFO impl.YarnClientImpl: Submitted application application_1558520562958_0002
// :: INFO mapreduce.Job: The url to track the job: http://node101.yinzhengjie.org.cn:8088/proxy/application_1558520562958_0002/
// :: INFO mapreduce.Job: Running job: job_1558520562958_0002
// :: INFO mapreduce.Job: Job job_1558520562958_0002 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1558520562958_0002 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Rack-local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total time spent by all reduce tasks (ms)=
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO terasort.TeraSort: done
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar terasort /user/yinzhengjie/data/day001/test_input /user/yinzhengjie/data/day001/test_output
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001
Found items
drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/test_input
drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/test_output
[root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001/test_input
Found items
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_input/_SUCCESS
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_input/part-m-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_input/part-m-
[root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001/test_output
Found items
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/_SUCCESS
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/_partition.lst
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/test_output/part-r-
[root@node102.yinzhengjie.org.cn ~]#
3>.验证输出
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# pwd
/opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teravalidate /user/yinzhengjie/data/day001/test_output /user/yinzhengjie/data/day001/ts_validate
// :: INFO input.FileInputFormat: Total input paths to process :
Spent 29ms computing base-splits.
Spent 3ms computing TeraScheduler splits.
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1558520562958_0003
// :: INFO impl.YarnClientImpl: Submitted application application_1558520562958_0003
// :: INFO mapreduce.Job: The url to track the job: http://node101.yinzhengjie.org.cn:8088/proxy/application_1558520562958_0003/
// :: INFO mapreduce.Job: Running job: job_1558520562958_0003
// :: INFO mapreduce.Job: Job job_1558520562958_0003 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1558520562958_0003 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Rack-local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total time spent by all reduce tasks (ms)=
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./lib/hadoop-mapreduce]#
[root@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop-mapreduce]# hadoop jar hadoop-mapreduce-examples.jar teravalidate /user/yinzhengjie/data/day001/test_output /user/yinzhengjie/data/day001/ts_validate
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001
Found items
drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/test_input
drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/test_output
drwxr-xr-x - root supergroup -- : /user/yinzhengjie/data/day001/ts_validate
[root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -ls /user/yinzhengjie/data/day001/ts_validate
Found items
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/ts_validate/_SUCCESS
-rw-r--r-- root supergroup -- : /user/yinzhengjie/data/day001/ts_validate/part-r-
[root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]# hdfs dfs -cat /user/yinzhengjie/data/day001/ts_validate/part-r-00000 #我们可以看到checksum是有内容,说明验证的数据是有序的。
checksum 4c49607ac53602
[root@node102.yinzhengjie.org.cn ~]#
[root@node102.yinzhengjie.org.cn ~]#
最新文章
- eclipse pydev 跳转
- js 字符串拼接
- CSS3-Media Query 基础
- 最近火到不行的微信小程序的常识
- 创建Maven工程
- myeclipse 8.5 常用快捷键【转】
- Cheatsheet: 2014 12.01 ~ 12.31
- Linux下各硬件装置的文件名
- 0到N数其中三个数的全排列
- android 源码编译中的错误 解决
- SNMP监控一些常用OID的总结
- hdu 3389 Game 博弈论
- Sublime Text 2 注册码
- js仿百度文库文档上传页面的分类选择器_第二版
- UVALive 5102 Fermat Point in Quadrangle 极角排序+找距离二维坐标4个点近期的点
- listview下拉刷新上拉加载扩展(一)
- Unity日常记录-本地保存未来时间实现倒计时
- GraphQL搭配MongoDB入门项目实战
- Python编程练习:使用 turtle 库完成正方形的绘制
- java实现pdf按页切分成图片