Hadoop_03_Hadoop分布式集群搭建
一:Hadoop集群简介:
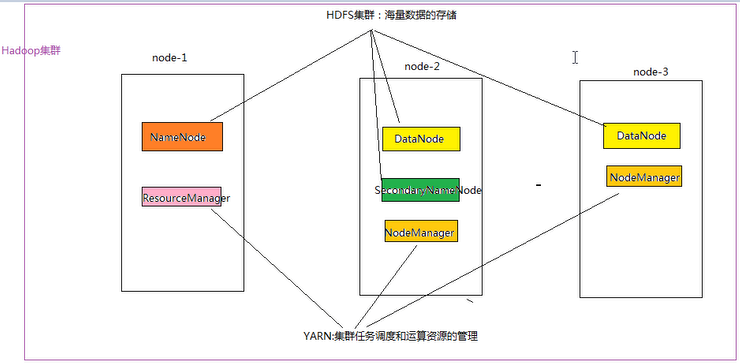
Hadoop 集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起;
HDFS集群:负责海量数据的存储,集群中的角色主要有: NameNode、DataNode、SecondaryNameNode;
YARN集群:负责海量数据运算时的资源调度,集群中的角色主要有: ResourceManager、NodeManager;
那么 Mapreduce 是什么呢:它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,
然后打包运行在 HDFS 集群上,并受到 YARN 集群的资源调度管理,由 YARN 为Mapreduce 程序分配运算硬件资源;
二:Hadoop集群部署:
Hadoop包含HDFS集群和YARN集群。部署Hadoop就是部署HDFS和YARN集群
Hadoop部署方式分为三种,Standalone mode(独立模式)、Pseudo-Distributed mode(伪分布式模式)、Cluster rmode
(群集模式),其中前两种都是在单机部署
1. 独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试
2. 伪分布模式也是在1个机器上运行 HDFS 的NameNode和DataNode、YARN的ResourceManger和NodeManager,但分别启
动单独的java进程,主要用于调试
3. 集群模式主要用于生产坏境部署,会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在
不同的机器上
4. 本集群搭建案例,以4节点为例进行搭建,角色分配如下:
| 主机名 | IP | 角色 |
|---|---|---|
| shizhan2 | 192.168.232.201 | Name Node:9000 Resource Manager |
| shizhan3 | 192.168.232.205 | Data Node Node Manager |
| shizhan5 | 192.168.232.207 | Data Node Node Manager |
| shizhan6 | 192.168.232.208 | Data Node Node Manager |
示例图:
三:Hadoop集群安装:
1.上传安装文件到虚拟机:我使用FTP传输
2.解压文件到指定目录: tar -zxvf cenos-6.5-hadoop-2.6.4.tar.gz -C /usr/local/src/
3.修改配置文件:
3.1.hadoop-env.sh:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/hadoop-env.sh
然后配置JAVA_HOME,可以先用echo $JAVA_HOME命令取得JAVA_HOME的位置:/usr/java/jdk1.7.0_45
export JAVA_HOME=/usr/java/jdk1.7.0_45
3.2.core-site.xml:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/core-site.xml
<configuration>
<!-- 指定 Hadoop 所使用的文件系统schema(URI),HDFS的老大(NameNode:为客户提供服务,首先被访问)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://shizhan2:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.6.4/hdpdata</value>
</property>
</configuration>
3.3.hdfs-site.xml:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3.4.mapred-site.xml:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/mapred-site.xml.template
mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 指定mapreduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> //不填写默认local
</property>
</configuration>
3.5.yarn-site.xml:
vi /usr/local/src/hadoop-2.6.4/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>shizhan2</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.将Hadoop拷贝到其他虚拟机:
scp -r /usr/local/src/hadoop-2.6.4 shizhan3:/usr/local/src/
scp -r /usr/local/src/hadoop-2.6.4 shizhan5:/usr/local/src/
scp -r /usr/local/src/hadoop-2.6.4 shizhan6:/usr/local/src/
5.将hadoop添加到环境变量:
vim /etc/proflie
export JAVA_HOME=/usr/java/jdk1.7.0_65
export HADOOP_HOME=/usr/local/src/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
6.格式化 HDFS文件系统:(对namenode进行初始化,生成相应目录)
首先把Hadoop配置到环境变量里面去,然后执行命令:hdfs namenode -format (hadoop namenode -format)
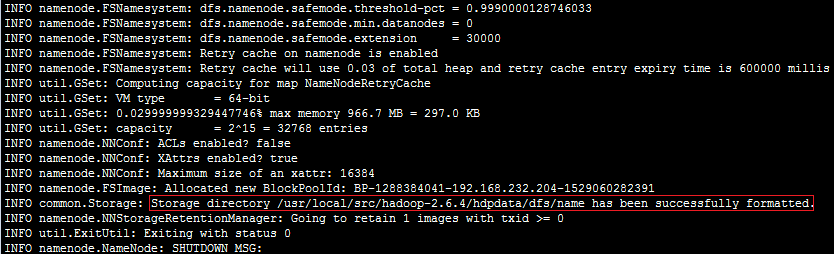
创建了NameNode的工作目录
7.修改NameNode中的slaves配置(供自动化启动脚本使用):vi /usr/local/src/hadoop-2.6.4/etc/hadoop/slaves
shizhan3
shizhan5
shizhan6
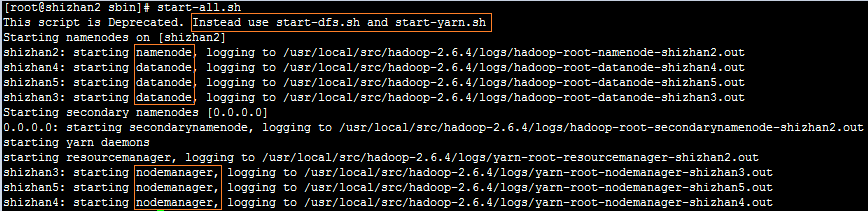
8.在NameNode节点上启动Hadoop:Hadoop/sbin/start-all.sh(先启动HDFS再启动YARN)
分开进行启动:先启动HDFS:sbin/start-dfs.sh ,再启动YARN:sbin/start-yarn.sh
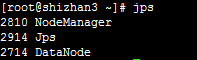
然后在NameNode上运行jps命令,应该包含下面的结果:
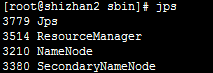
在其他节点上运行jps命令,应该包含下面的结果:
四:配置ssh免登陆:
1.ssh-keygen -t rsa(四个回车),执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
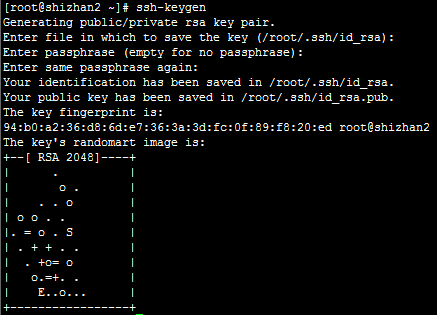
2.将公钥拷贝到要免密登陆的目标机器上:ssh-copy-id shizhan2/shizhan3/shizhan5/shizhan6
五:验证是否启动成功:
HDFS管理界面:访问http://shizhan2:50070,可以看到如下图所示的结果:

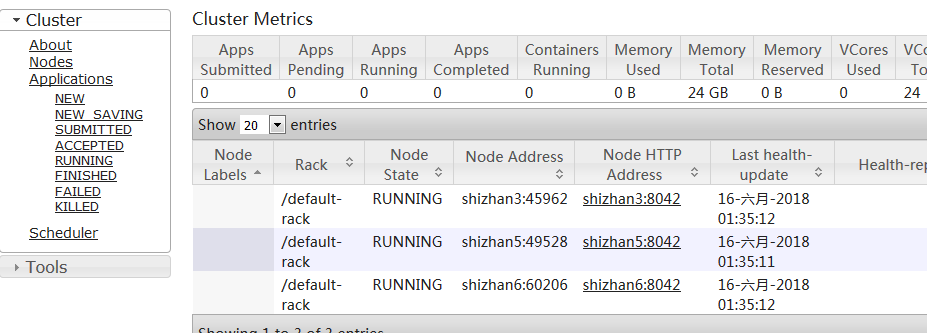
YARN管理界面,访问http://shizhan2:8088,可以看到如下图所示的结果:
五:出现的问题:
Hadoop dataNode正常启动,但是live Nodes中确缺少节点:
解决方案:修改vi /usr/local/src/hadoop-2.6.4/etc/hadoop/core-site.xml配置文件
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.6.4/hdpdata</value>
</property>
之前因为配置的数据存放路径相同,所以报告中认为只有一个DataNode,所以在Web控制台dataNodes数目显示不全;
最新文章
- MySQL基础(三)
- 修改MySQL用户的密码
- HDU 3535 【背包】
- (转)最近研究xcodebuild批量打包的一些心得
- windows下使用批处理调用exe和服务
- react.js 从零开始(三)JSX 语法及特点介绍
- MAC OS 快捷键一览
- UML学习笔记之类之间的关系
- 【锋利的jQuery】表单验证插件踩坑
- jenkins+github持续集成中的坑
- 音频处理库—librosa的安装与使用
- LOJ6070 基因 分块+回文自动机
- 【数组】Sort Colors
- 常用工具说明--jsdoc 前端文档输出工具
- Extjs window组件 拖动统制
- 多个else if语句
- Tesseract-OCR 自动生成识别库的批处理
- font-sqirrel
- STL源码解析之vector自实现
- EventTrigger