solr介绍
2024-09-05 10:38:33
solr架构图:
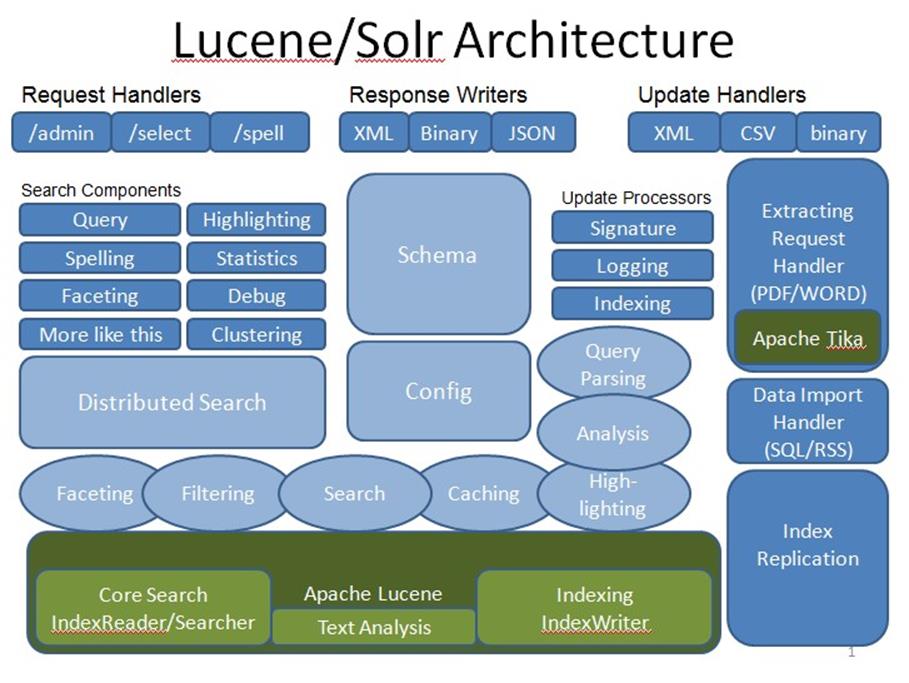
以下是Apache Solr的主要构建块(组件)
- 请求处理程序 - 发送到Apache Solr的请求由这些请求处理程序处理。请求可以是查询请求或索引更新请求。根据这些请示的要求来选择请求处理程序。为了将请求传递给Solr,通常将处理器映射到某个URI端点,并且它将为指定的请求提供服务。
- 搜索组件 - 搜索组件是Apache Solr中提供的搜索类型(功能)。它可能是拼写检查,查询,构面,命中突出显示等。这些搜索组件被注册为搜索处理程序。多个组件可以注册到搜索处理程序。
- 查询解析器 − Apache Solr查询解析器解析传递给Solr的查询,并验证查询的语法是否有错误。解析查询后,将它们转换为
Lucene理解的格式。 - 响应写入器 - Apache Solr中的响应写入器是为用户查询生成格式化输出的组件。 Solr支持XML,JSON,CSV等响应格式。对每种类型的响应都有不同的响应写入。
- 分析器/分词器 - Lucene以令牌的形式识别数据。 Apache Solr分析内容,将其分成令牌,并将这些令牌传递给Lucene。 Apache Solr中的分析器检查字段的文本并生成令牌流。分词器将分析器准备的令牌流分解成令牌。
- 更新请求处理器 - 每当向Apache Solr发送更新请求时,请求都通过一组称为更新请求处理器的插件(签名,日志记录,索引)运行。这个处理器负责修改,例如删除字段,添加字段等。
solr的特性:
solr是读主导的:并非说solr是不支持批量写入的,只是对于solr来说,一般的使用场景是,读操作要远远多于写操作的场景。
不要将solr用于:
- 不适合一次性返回大量数据。
- 不适合执行深度分析任务。
- 不支持复杂关系关联查询。
solr局限:
无法执行join操作。
数据是冗余的。可能产生大量修改的情况。
可以方便的对文档进行增删改,但是不能对字段轻易的做这种处理。
solrcloud不支持自动重新分片内容和增加索引副本的数量,从而动态的处理内容增长和查询负载。
最新文章
- 中文分词工具探析(一):ICTCLAS (NLPIR)
- Java多线程5:synchronized锁方法块
- [Tex学习笔记]积分平均
- Selenium2+python自动化12-操作元素(键盘和鼠标事件)
- matlab R2016b 设置界面为英文
- RTLviewer与TechnologyMapViewer的区别?
- 插件化—配置xml的辅助测试
- mysql的注释
- 所谓编码--泛谈ASCII、Unicode、UTF8、UTF16、UCS-2等编码格式
- windows下 cmd 界面的替代者 cmder 推荐!
- css之positon与z-index
- java 调用c# web api 代码
- 20170506计划-----(基于python查询oracle语句)
- AX_Query
- jquery 3.4.0
- MySQL出现Access denied for user ‘root’@’localhost’ (using password:YES)
- Java入门系列(九)Java API
- 织梦导航条dropdown.js的改进(2013-7-10)
- USB gadget 驱动 printer.c 分析
- 给ubuntu系统的root设置密码: