Flume-Exec Source 监控单个本地文件
2024-09-02 17:54:01
实时监控,并上传到 HDFS 中。
一、Flume 要想将数据输出到 HDFS,须持有 Hadoop 相关 jar 包
若 Hadoop 环境和 Flume 在同一节点,那么只要配置 Hadoop 环境变量即可,不需要复制相关 jar 包。
# 将相关包拷贝到 flume 的 lib 目录下
# commons-configuration-x.x.jar
# hadoop-auth-x.x.x.jar、
# hadoop-common-x.x.x.jar、
# hadoop-hdfs-x.x.x.jar、
# commons-io-x.x.jar、
# htrace-core-x.x.x-incubating.jar cp /opt/hadoop-2.9./share/hadoop/hdfs/hadoop-hdfs-2.9..jar /opt/apache-flume-1.9.-bin/lib/
cp /opt/hadoop-2.9./share/hadoop/common/hadoop-common-2.9..jar /opt/apache-flume-1.9.-bin/lib/
cp /opt/hadoop-2.9./share/hadoop/common/lib/commons-io-2.4.jar /opt/apache-flume-1.9.-bin/lib/
cp /opt/hadoop-2.9./share/hadoop/common/lib/hadoop-auth-2.9..jar /opt/apache-flume-1.9.-bin/lib/
cp /opt/hadoop-2.9./share/hadoop/common/lib/commons-configuration-1.6.jar /opt/apache-flume-1.9.-bin/lib/
cp /opt/hadoop-2.9./share/hadoop/common/lib/htrace-core4-4.1.-incubating.jar /opt/apache-flume-1.9.-bin/lib/
二、创建 flume-file-hdfs.conf 文件
https://flume.apache.org/FlumeUserGuide.html#exec-source
https://flume.apache.org/FlumeUserGuide.html#flume-sinks
要想读取 Linux 系统中的文件,就得按照 Linux 命令的规则执行命令。由于 Hive 日志在 Linux 系统中所以读取文件的类型选择:exec 即 execute 执行的意思。表示执行 Linux 命令来读取文件。
# Name the components on this agent
# 定义 source
a2.sources = r2
# 定义 sink
a2.sinks = k2
# 定义 channel
a2.channels = c2 # Describe/configure the source
# 定义 source 类型为 exec 可执行命令
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /tmp/tomcat.log
# 执行 shell 脚本的绝对路径
a2.sources.r2.shell = /bin/bash -c # Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://h136:9000/flume/%Y%m%d/%H
# 上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
# 是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
# 多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
# 重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
# 是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
# 积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k2.hdfs.batchSize = 100
# 设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
# 多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 30
# 设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
# 文件的滚动与 Event 数量无关
a2.sinks.k2.hdfs.rollCount = 0 # Use a channel which buffers events in memory
# 表示 a2 的 channel 类型是 memory 内存型
a2.channels.c2.type = memory
# 表示 a2 的 channel 总容量 1000 个 event
a2.channels.c2.capacity = 1000
# 表示 a2 的 channel 传输时收集到了 100 条 event 以后再去提交事务
a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel
# 表示将 r2 和 c2 连接起来
a2.sources.r2.channels = c2
# 表示将 k2 和 c2 连接起来
a2.sinks.k2.channel = c2
注意:a2.sinks.k2.hdfs.useLocalTimeStamp = true,对于所有与时间相关的转义序列,Event Header 中必须存在以 “timestamp” 的 key(除非 hdfs.useLocalTimeStamp 设置为 true,此方法会使用 TimestampInterceptor 自动添加 timestamp)。
三、启动
在启动之前需要先启动 Hadoop 环境。
cd /opt/apache-flume-1.9.-bin/
bin/flume-ng agent --conf conf/ --name a2 --conf-file /tmp/flume-job/flume-file-hdfs.conf -Dflume.root.logger=INFO,console # 追加日志内容
echo 'add xxxxx' >> /tmp/tomcat.log
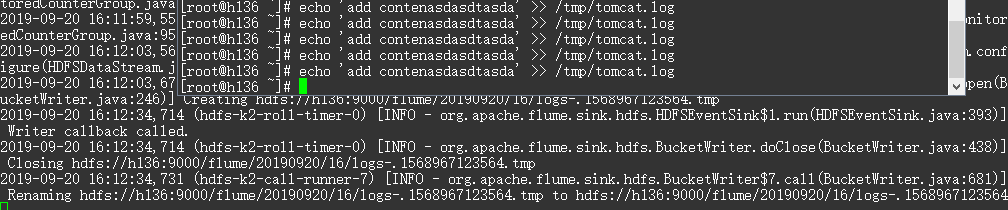
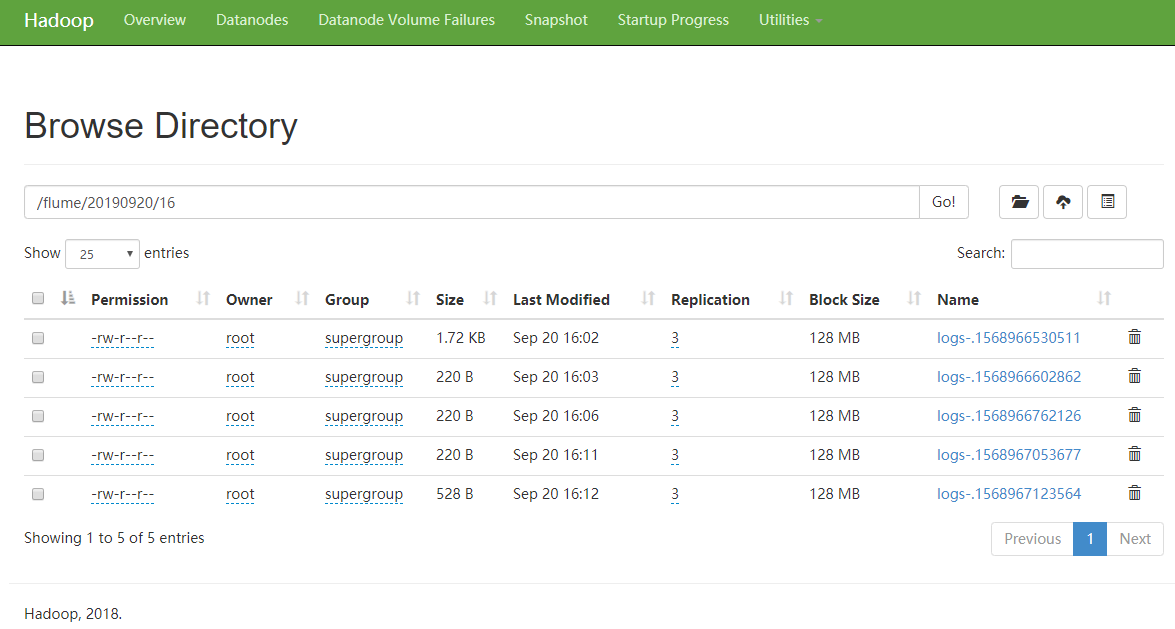
HDFS 上的文件
最新文章
- 用java开发微信公众号:测试公众号与本地测试环境搭建(一)
- Makefile中头文件在依赖关系中作用
- vuex2.0.0爬坑记录 -- mutations的第一个参数state不能解构
- Maven Repository
- LongListSelector with bindable SelectedItem
- C++调用动态库中的虚基类成员函数时总是进错函数
- Java中接口式的匿名内部类的构造方法
- listView异步处理图片下载缓存
- 如何将BarTender内容锁定不让改动
- .net文件下载方法汇总
- spark提交任务的流程
- 《Linux设备驱动开发具体解释(第3版)》进展同步更新
- 第七章——DMVs和DMFs(4)——用DMV和DMF监控磁盘IO
- 自定义控件之--继承控件(圆形TextView)
- R语言爬虫 rvest包 html_text()-html_nodes() 原理说明
- 【懒人有道】在asp.net core中实现程序集注入
- Java多线程处理List数据
- Vue 的生命周期图
- snmp自定义OID与文件下载----服务器端配置
- mybatis介绍——(一)