Scrapy学习(二)
2024-10-07 04:25:33
1.在合适的位置创建一个文件夹,创建python虚拟环境:
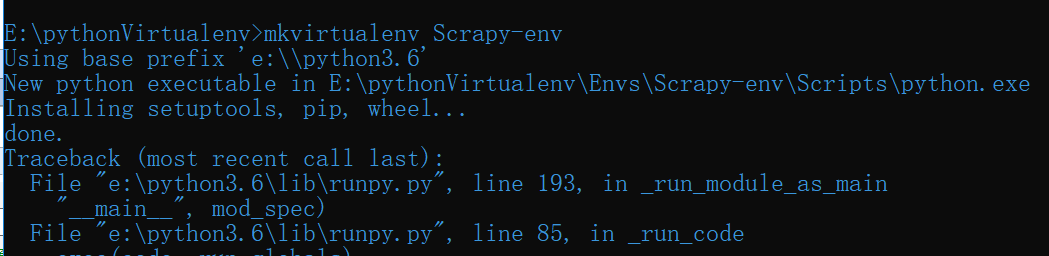
2.在虚拟环境中安装Scrapy库和pypiwin32库:
命令:pip install scrapy
pip install pypiwin32
3.安装好之后,创建Scrapy项目:
在本虚拟环境下创建一个文件夹:
mkdir ScrapyProject
cd到该目录下,创建Scrapy项目
命令:scrapy startproject PearVideo

4.完成后用pycharm打开,文件目录结构如下:
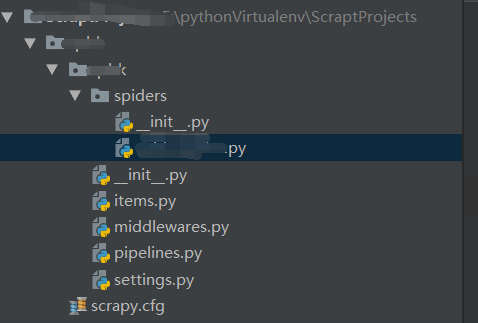
5.然后再用命令创建自己的爬虫文件:
scrapy genspider PearViode_spider "pearvideo.com"
# 注意:自己爬虫名不能和项目名称一样,否则不能创建
最新文章
- Centos7上启动vpn客户端失败问题处理
- android studio 使用 jni 编译 opencv 完整实例 之 图像边缘检测!
- struts2 validation.xml 注意点
- ACM 另一种阶乘问题
- JAVA CAS原理
- [Python] Symbol Review
- 用TextPaint来绘制文字
- android Activity的启动模式
- [转] Android获取Manifest中<meta-data>元素的值
- ci模板布局方式
- Linux中处理需要传输的IP报文流程
- 五笔拼音反查精灵 v6.69 绿色版
- PRINCE2的发展情况是什么样
- zalenium 应用
- MySQL ID排序乱了的解决办法
- Django contenttypes组件
- 分布式作业 Elastic Job 如何动态调整?
- Java RMI与RPC的区别
- jquery基础学习之动画篇(四)
- Python3 tkinter基础 Label pack 设置控件在窗体中的位置