word embeddding和keras中的embedding
2024-10-19 02:24:44

训练好的词向量模型被保存下来,该模型的本质就是一个m*n的矩阵,m代表训练语料中词的个数,n代表训练时我们设定的词向量维度。当我们训练好模型后再次调用时,就可以从该模型中直接获取到对应词的词向量。
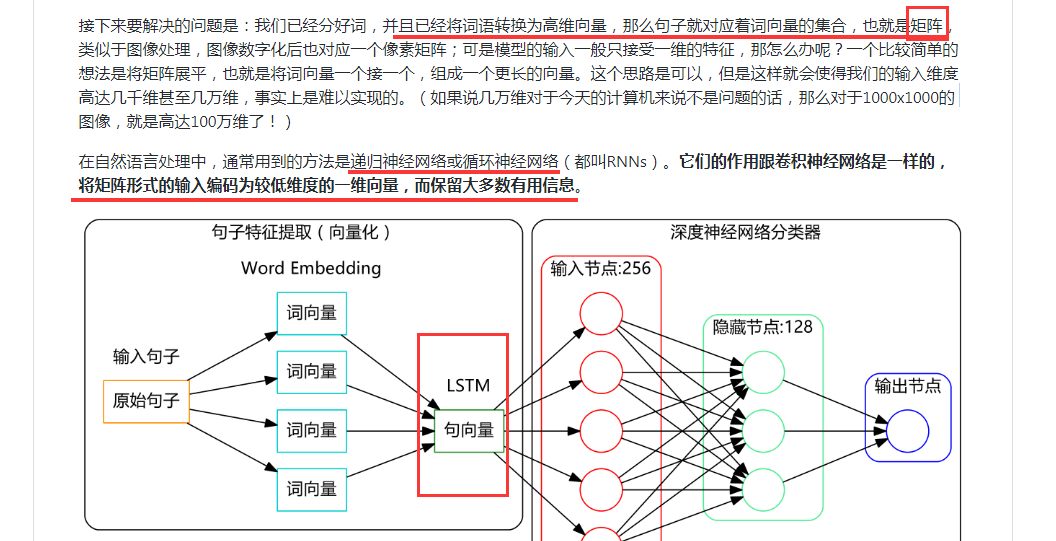
通过上面我们可以拿到每个词的词向量,但是我们任务处理时一般是对句子或文本进行操作。当我们拿到一个词向量后,那么一个句子或一个文本就可以用词表示成矩阵(假设一个句子有5个词,词向量维度是64,那么该矩阵就是5*64),然后可以用CNN或RNN(LSTM)模型将该矩阵编码成一个一维向量,并保留大多数文本信息。然后将该向量作为深度神经网络分类器的输入,即可得到最终的结果。
最新文章
- Trumbowyg - 轻量的 WYSIWYG 编辑器
- 读写锁:ReadWriteLock
- Thread线程初探
- Fixing the Great Wall
- 如何将mysql表结构导出成Excel格式的(并带备注)
- css3 翻书效果
- OpenStack Neutron DVR L2 Agent的初步解析 (一)
- 挂载(mount)深入理解
- Ubuntu12.10 下搭建基于KVM-QEMU的虚拟机环境(三)
- Maven 插件 maven-tomcat7-plugin - 常用命令及配置
- request.setcharacterencoding()和request.setcontenttype
- FreeRTOS源代码的编程标准与命名约定
- Python练手例子(9)
- SpringMVC 与 REST.
- POJ2155(二维树状数组)
- netty05(netty的一些介绍)
- [leetcode]72. Edit Distance 最少编辑步数
- Photoshop 基础五 橡皮擦工具
- springmvc访问项目默认先访问后台再返回首页
- 视频支持拖动进度条播放的实现(基于nginx)