关于深度学习中的batch_size
5.4.1 关于深度学习中的batch_size
举个例子:
例如,假设您有1050个训练样本,并且您希望设置batch_size等于100.该算法从训练数据集中获取前100个样本(从第1到第100个)并训练网络。接下来,它需要第二个100个样本(从第101到第200)并再次训练网络。我们可以继续执行此过程,直到我们通过网络传播所有样本。最后一组样本可能会出现问题。在我们的例子中,我们使用了1050,它不能被100整除,没有余数。最简单的解决方案是获取最终的50个样本并训练网络。
最终目的:
通过一批又一批的样本去优化参数
使用批量大小的优点<所有样本的数量:
它需要更少的内存。由于您使用较少的样本训练网络,因此整体训练过程需要较少的内存。如果您无法将整个数据集放入机器的内存中,那么这一点尤为重要。
通常,网络通过小批量训练更快。那是因为我们在每次传播后更新权重。在我们的例子中,我们已经传播了11批(其中10个有100个样本,1个有50个样本),在每个批次之后我们更新了网络的参数。
如果我们在传播过程中使用了所有样本,我们只会对网络参数进行1次更新。
使用批量大小的缺点<所有样本的数量:
- 批次越小,梯度的估计就越不准确。在下图中,您可以看到小批量渐变(绿色)的方向与完整批次渐变(蓝色)的方向相比波动更大。
batch_size可以理解为批处理参数,它的极限值为训练集样本总数,当数据量比较少时,可以将batch_size值设置为全数据集(Full batch cearning)。
实际上,在深度学习中所涉及到的数据都是比较多的,一般都采用小批量数据处理原则。
小批量训练网络的优点:
- 相对海量的的数据集和内存容量,小批量处理需要更少的内存就可以训练网络。
- 通常小批量训练网络速度更快,例如我们将一个大样本分成11小样本(每个样本100个数据),采用小批量训练网络时,每次传播后更新权重,就传播了11批,在每批次后我们均更新了网络的(权重)参数;如果在传播过程中使用了一个大样本,我们只会对训练网络的权重参数进行1次更新。
- 全数据集确定的方向能够更好地代表样本总体,从而能够更准确地朝着极值所在的方向;但是不同权值的梯度值差别较大,因此选取一个全局的学习率很困难。
小批量训练网络的缺点:
- 批次越小,梯度的估值就越不准确,在下图中,我们可以看到,与完整批次渐变(蓝色)方向相比,小批量渐变(绿色)的方向波动更大。
- 极端特例batch_size = 1,也成为在线学习(online learning);线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆,对于多层神经元、非线性网络,在局部依然近似是抛物面,使用online learning,每次修正方向以各自样本的梯度方向修正,这就造成了波动较大,难以达到收敛效果。
如下图所示
stochastic(红色)表示在线学习,batch_size = 1;
mini_batch(绿色)表示批梯度下降法,batch_size = 100;
batch(蓝色)表示全数据集梯度下降法,batch_size = 1100;
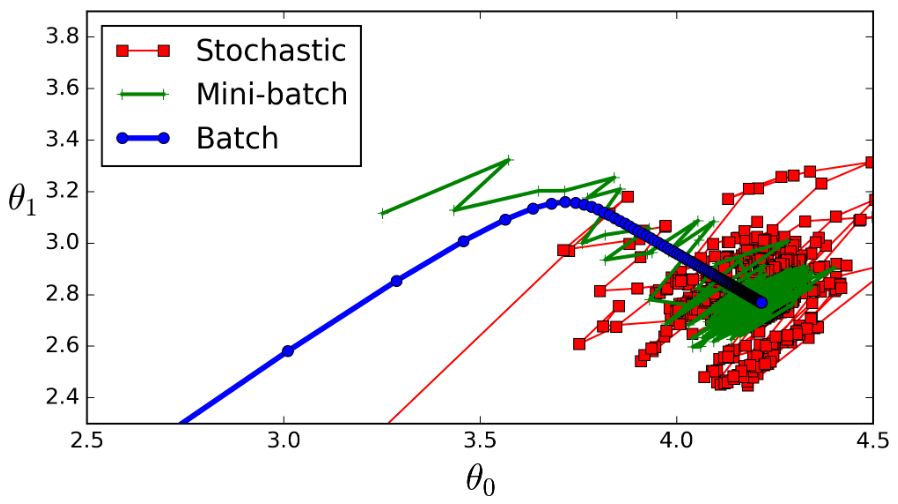
从图上可以发现,batch_szie=1 较 batch_size=100 的波动性更大。
设置mini_batch大小是一种艺术,太小时可能会使学习过于随机,虽然训练速率很快,但会收敛到不可靠的模型;mini_batch过小时,网络训练需要很长时间,更重要的是它不适合记忆。
如何选择合适的batch_size值:
采用批梯度下降法mini batch learning时,如果数据集足够充分,用一半(甚至少的多)的数据训练算出来的梯度与全数据集训练full batch learning出来的梯度几乎一样。
- 在合理的范围内,增大batch_size可以提高内存利用率,大矩阵乘法的并行化效率提高;跑完一次epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快;在适当的范围内,batch_size越大,其确定的下降方向越准,引起训练波动越小。注意,当batch_size增大到一定程度,其确定的下降方向基本不会变化。
batch_size值增大到超过合理范围时,和全数据训练full batch learning就会表现出相近的症候;内存容量占有率增加,跑完一次epoch(全数据集)所需的迭代次数减少,达到相同的精度所耗损的时间增加,从而对参数的修正也就显得更加缓慢。
调节 Batch_Size 对训练效果影响到底如何?
这里跑一个 LeNet 在 MNIST 数据集上的效果。MNIST 是一个手写体标准库
运行结果如上图所示,其中绝对时间做了标准化处理。运行结果与上文分析相印证:
- batch_size 太小,算法在 200 epoches 内不收敛。
- 随着 batch_size 增大,处理相同数据量的速度越快。
- 随着 batch_size 增大,达到相同精度所需要的 epoch 数量越来越多。
- 由于上述两种因素的矛盾,batch_size 增大到某个时候,达到时间上的最优。
- 由于最终收敛精度会陷入不同的局部极值,因此batch_size 增大到某些时候,达到最终收敛精度上的最优。
最新文章
- zabbix告警使用sendEmail
- shell常用命令归类整理
- 黑马程序员-autorelease pool
- 网络初见&网络监测
- knockout 学习实例5 style
- linux下mysql字符集编码问题的修改
- (网络层)IP 协议首部格式与其配套使用的四个协议(ARP,RARP,ICMP,IGMP)
- 反弹SHELL汇总
- HDU 4891 The Great Pan (模拟)
- 转载 基于Selenium WebDriver的Web应用自动化测试
- Java-Android 之电话拨号源码
- MySql安装与卸载
- [ ArcGIS Server技术版]如何得到本机上的所有的REST服务?
- STM32笔记总结
- APP测试中的头疼脑热:测试人员如何驱动开发做好自测
- 关于ThreadLocal和一般的线程同步的详细解释
- 基于Linux-3.9.4内核的GDB跟踪系统调用实验
- Microsoft Windows Server 2012 Ad域搭建
- PAT (Basic Level) Practise - 害死人不偿命的(3n+1)猜想
- 可在广域网部署运行的即时通讯系统 -- GGTalk总览(附源码下载)