2.keras实现-->字符级或单词级的one-hot编码 VS 词嵌入
1. one-hot编码
# 字符集的one-hot编码 characters= '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVW XYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c' |

|
# keras实现单词级的one-hot编码 |
sequences = [[2, 3, 4, 1], 发现10个unique标记 word_index = {'pig': 1, 'zzh': 2, 'is': 3, 'a': 4, 'he': 5,
|
one-hot 编码的一种办法是 one-hot散列技巧(one-hot hashing trick)如果词表中唯一标记的数量太大而无法直接处理,就可以使用这种技巧。这种方法没有为每个单词显示的分配一个索引并将这些索引保存在一个字典中,而是将单词散列编码为固定长度的向量,通常用一个非常简单的散列函数来实现。 优点:节省内存并允许数据的在线编码(读取完所有数据之前,你就可以立刻生成标记向量) 缺点:可能会出现散列冲突 如果散列空间的维度远大于需要散列的唯一标记的个数,散列冲突的可能性会减小 |
|
import numpy as np samples = ['the cat sat on the mat the cat sat on the mat the cat sat on the mat','the dog ate my homowork'] |

|
2. 词嵌入
获取词嵌入的两种方法:
- 在完成主任务的同时学习词嵌入。在这种情况下,一开始是随机的词向量,然后对这些词向量进行学习,其学习方式与学习神经网络的权重相同。
- 在不同于待解决的机器学习任务上预计算好词嵌入,然后将其加载到模型中。这些词嵌入叫作预训练词嵌入
实验数据:imdb电影评论,我们添加了以下限制,将训练数据限定为200个样本(打乱顺序)。

| (1)使用embedding层学习词嵌入 | |
# 处理imdb原始数据的标签 |
len(texts)=25000 len(labels)=25000 |
# 对imdb原始数据的文本进行分词 |
sequence[0]
|
|
word_index = tokenizer.word_index |
#88592个unique单词 word_index
|
|
data = pad_sequences(sequences,maxlen=max_len) |
data.shape = (25000,100) data[0]
|
|
labels = np.asarray(labels) |
#asarray会跟着原labels的改变,算是浅拷贝吧, |
|
indices = np.arange(data.shape[0]) np.random.shuffle(indices) |
indices array([ 2501, 4853, 2109, ..., 2357, 22166, 12397]) |
#将data,label打乱顺序 |
x_val.shape,y_val.shape (10000, 100) (10000,) |
#2014年英文维基百科的预计算嵌入:Glove词嵌入(包含400000个单词) |
len(embeddings_index) 400000 |
#准备glove词嵌入矩阵 |
把数据集里面的单词在glove中找到对应的词向量,组成embedding_matrix, 若在glove中不存在,那就为0向量 |
#定义模型 |

|
model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['acc']) |
|
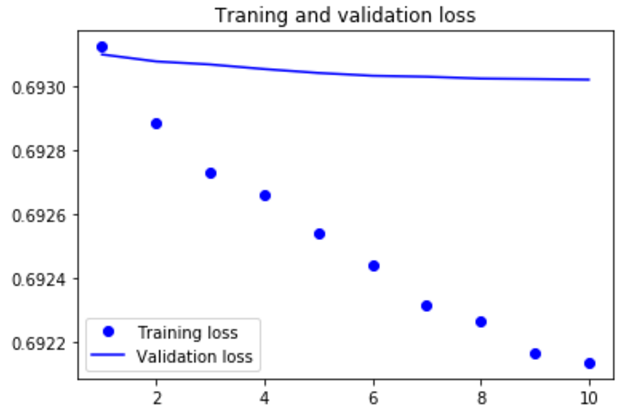
import matplotlib.pyplot as plt acc = history.history['acc'] |
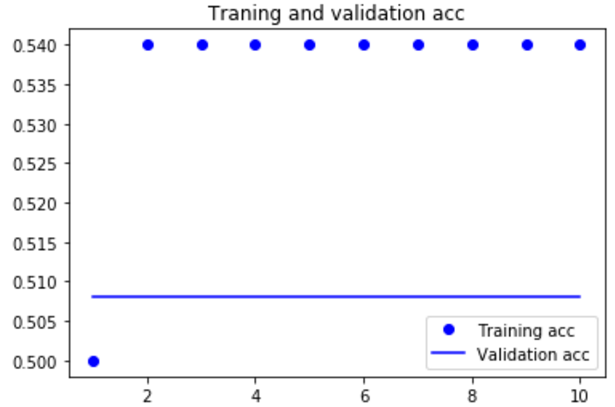
|
模型很快就开始过拟合,考虑到训练样本很少,这也很情有可原的 |

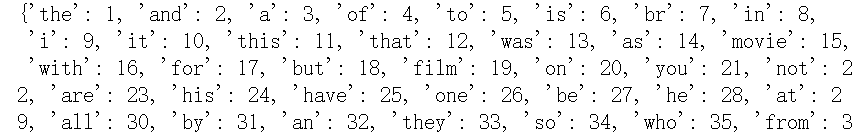

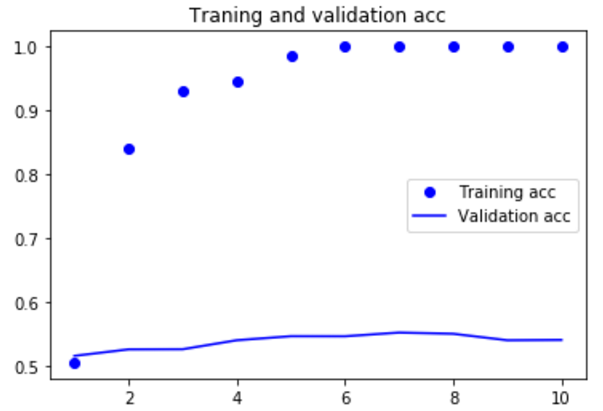
| (2)下面在不使用预训练词嵌入的情况下,训练相同的模型 | |
#定义模型 |

|
import matplotlib.pyplot as plt acc = history.history['acc'] |
|
#在测试集上评估模型 test_dir = os.path.join(imdb_dir,'test') labels = [] |
|
|
model.load_weights('pre_trained_glove_model.h5') model.evaluate(x=x_test,y=y_test) |
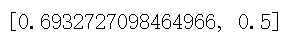 |
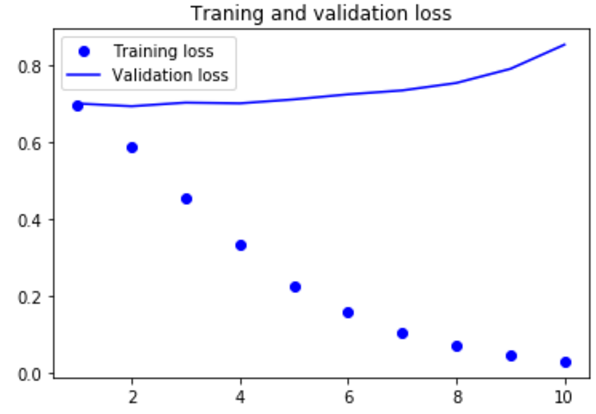
如果增加训练集样本的数量,可能使用词嵌入得到的效果会好很多。
最新文章
- <meta>指定浏览器模式(browser mode)或文档模式(document mode)无效
- 装逼名词 bottom-half,软中断,preemptive选项
- Debian 7 安装 wireshark
- sql server 2005导出数据到oracle
- 安装mmseg出错 config.status: error: cannot find input file: src/Makefile.in
- windows下mysql远程访问慢
- 深度学习入门教程UFLDL学习实验笔记二:使用向量化对MNIST数据集做稀疏自编码
- apache 访问权限基本设置
- Dreamweaver 8
- linux静态与动态库创建及使用实例
- Hadoop RPC简单实例
- Java中,当表单含有文件上传时,提交数据的如何读取
- Hadoop2.6 Ha 安装
- [原]docker 操作记录
- Java中的类变量、实例变量、类方法、实例方法的区别
- eclipse 设置maven来自动下载源码与doc
- box-shadow内阴影、外阴影
- .NET Core微服务之基于MassTransit实现数据最终一致性(Part 1)
- 兼容IE FF 获取鼠标位置
- E-commerce 中促销系统的设计
热门文章
- css笔记 - 张鑫旭css课程笔记之 relative 篇
- Spring.NET依赖注入框架学习-- 泛型对象的创建和使用
- XSS 跨站脚本攻击(Cross Site Scripting)
- Cannot assign to read only property 'exports' of object '#<Object>'
- 一键用VS编译脚本
- 如何在Computer下添加System Folder(续)
- 使用jetty的continuations实现"服务器推"
- Android studio was unable to create a local connection in order...
- Thinkphp框架下(同服务器下)不同二级域名之间session互通共享设置
- React 属性和状态的一些总结