web统计数据搜集及分析原理
在现代web应用开发中,数据扮演着越来越重要的角色:通过数据我们能够知道系统哪些地方有待改进,从而迭代开发重新上线,
随后再次通过数据我们来评估新的迭代开发是否满足了我们的预期目标,从而形成了一个数据驱动开发的业务闭环。这个闭环之所以
能够工作,其原因就是我们能够搜集到web应用使用数据,从而能够对这些数据进行分析。
本文就对web行为数据搜集做一个简单探讨。
下面的内容摘自: http://www.admin10000.com/document/1089.html
文章确实不错。
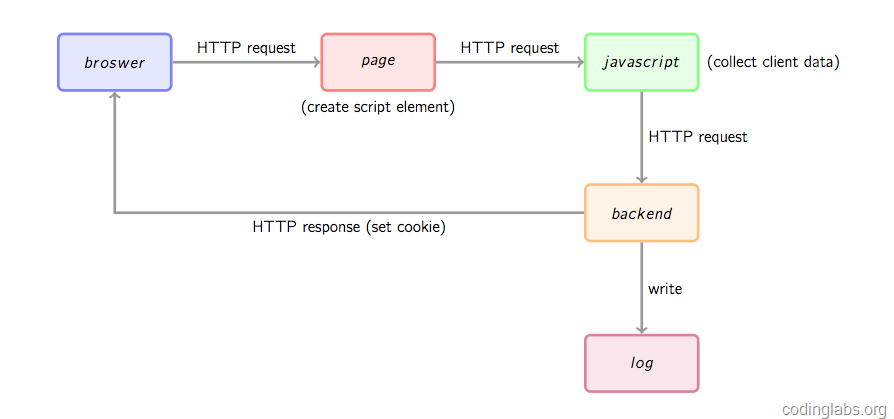
上图是一个类似百度统计,GA工作时网站统计数据收集的基本流程图,介绍如下:
1.浏览器向被统计页面发起http请求打开页面;
2.打开页面时,页面中的GA埋点js片段就会被执行,而这段代码一般来说就是执行一小段js,动态创建一个script标签,并且将其src指向google或者baidu的单独的js文件,而这个js文件本身才是真正的数据收集脚本;
3.将上述动态script标签插入到页面dom中,随后该页面就向baidu/google请求那个js文件,该文件下载后立即执行,该文件往往通过搜集比如操作系统,屏幕尺寸,浏览器名称等信息,随后这个js就会向后端请求访问;
4.但是由于javascript的跨域访问限制,往往在上述3.的步骤中并不会直接通过ajax调用后端服务,而使用了一个小的tip:将收集到的客户端数据放在url参数中,去向后端请求返回伪装1x1px image的后端脚本;
5.后端脚本获取上面的参数,插入数据库中,同时要查看是否已经在客户浏览器中种下cookie(用于标识用户唯一ID),如果有种过,则依然使用它,如果没有,则新创建一个UIDCookie,并且在返回image响应中以set-cookie头关键字返回到客户端浏览器,这样浏览器就创建或者更新自己的cookie,从而对baidu/google用户跟踪打下坚实的基础:(现代需求方广告平台DSP就依赖这些cookie及)

最新文章
- [原]如何用Android NDK编译FFmpeg
- Orleans 之 监控工具的使用
- Apache服务器的下载与安装
- 一个想了好几天的问题——关于8086cpu自己编写9号中断不能单步的问题
- python_way,day4 内置函数(callable,chr,随机验证码,ord),装饰器
- asp.net中父子页面通过gridview中的按钮事件进行回传值的问题
- js微博发布框
- mysql建表出现Timestamp错误
- Linux系统编程(37)—— socket编程之UDP服务器与客户端
- 在iOS虚拟机上使CLPlacemark获取中文信息
- How Many Maos Does the Guanxi Worth
- 读书笔记 effective c++ Item 50 了解何时替换new和delete 是有意义的
- jQuery对象和DOM对象和字符串之间的转化
- APP自动化框架LazyAndroid使用手册(3)--核心API介绍
- 【译】如何编写“移动端优先”CSS
- 使用Calender类获取系统时间和时间和运算
- php中$this->是什么意思
- everything不显示移动硬盘中路径
- 游戏行业的女性拥有强大的新盟友:Facebook
- c# sql 复制表后提示列无效解决办法