python 爬取王者荣耀高清壁纸
一、前言
打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面
预览一下桌面吧:

是不是看着这样的桌面也很带感,_ (学会这个技术,你可以爬取其他网站的类似图片,哄妹子专用,O(∩_∩)O哈哈~)
二、程序实现
我们先去找一个靠谱的网站吧,自然而然的网站地址锁定在王者荣耀官网上,正好他给我们提供了壁纸页面 http://pvp.qq.com/web201605/wallpaper.shtml
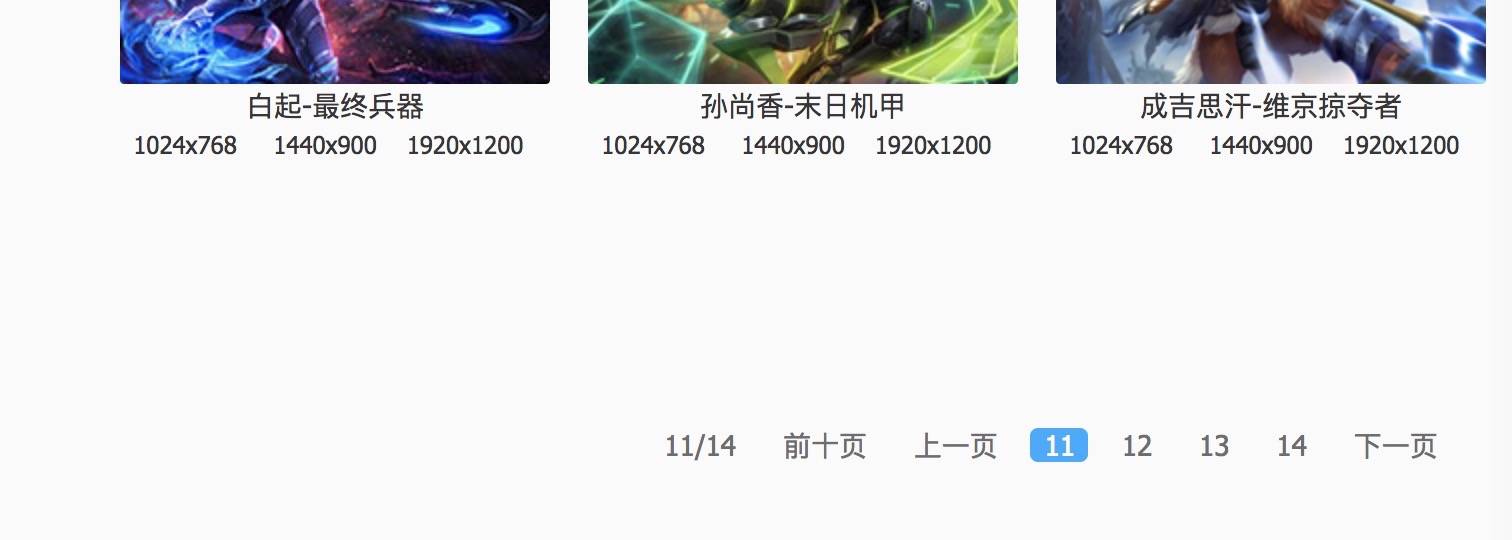
一共14页构建我们的目标数据URL
随便多翻几页,用firebug 等调试工具,观察一下我们的请求列表,找到其中特别明显的图片list api
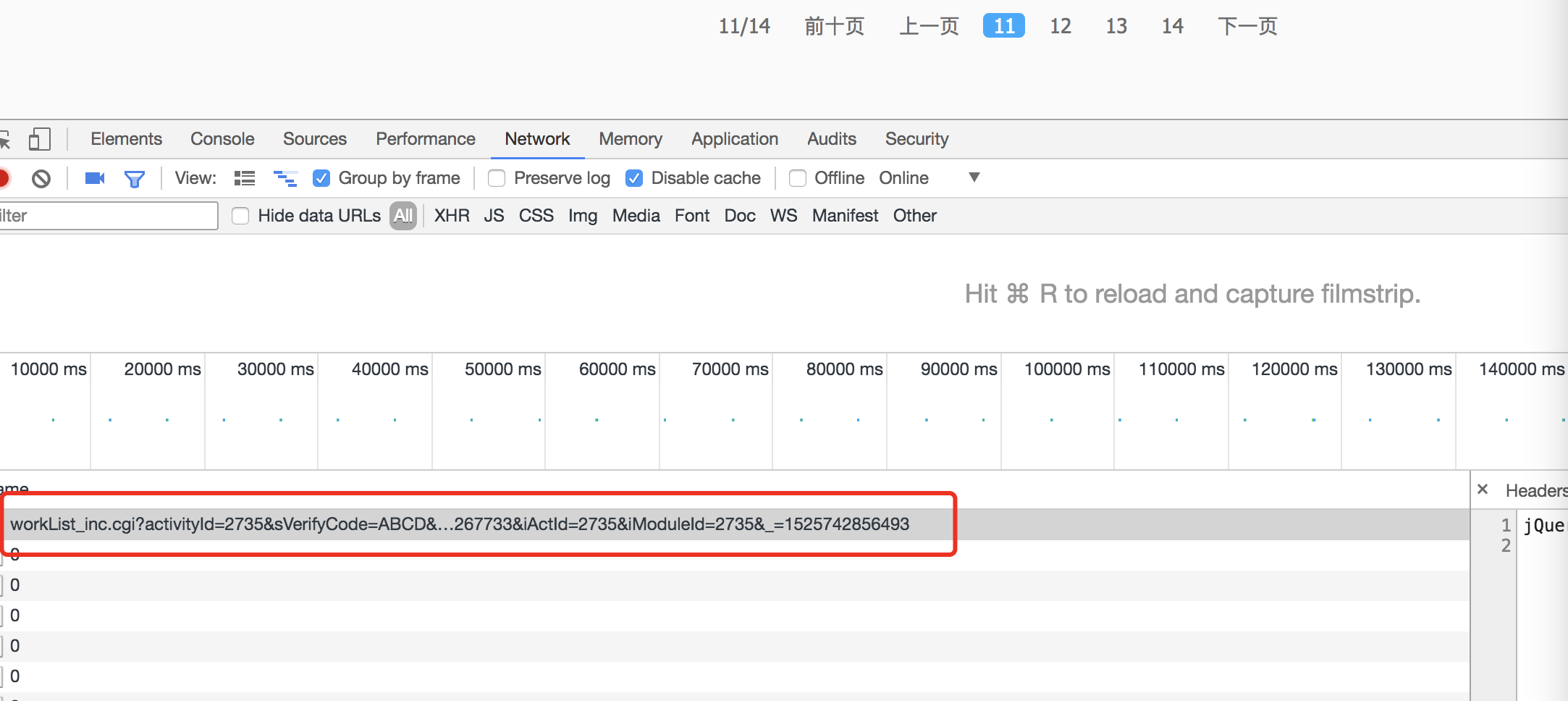
展开以后,特别详细的URL
http://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=10&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17106927574791770883_1525742053044&iAMSActivityId=51991&everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&=1525742856493
问题简单了就:
urls = [ "http://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&page=%d&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery1710881537174597735 6_1486710433816&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1486710458098" % (p) for p in range(0,14) ]
获取文档的内容:
这一步就比较简单了,requests 堪称写给人类的http 请求库,可以自己参看他的api 很强大,可以完成,任何手工在浏览器上的任何行为,用得好,你可以省掉很多的事儿,顺路贴一个api 链接吧 (http://www.python-requests.org/en/master/)[http://www.python-requests.org/en/master/]def loadUrlContent(url):
return requests.get(u).text解析文档内容 :
api 返回情况,大致如下: 是一个jsonp callback的返回
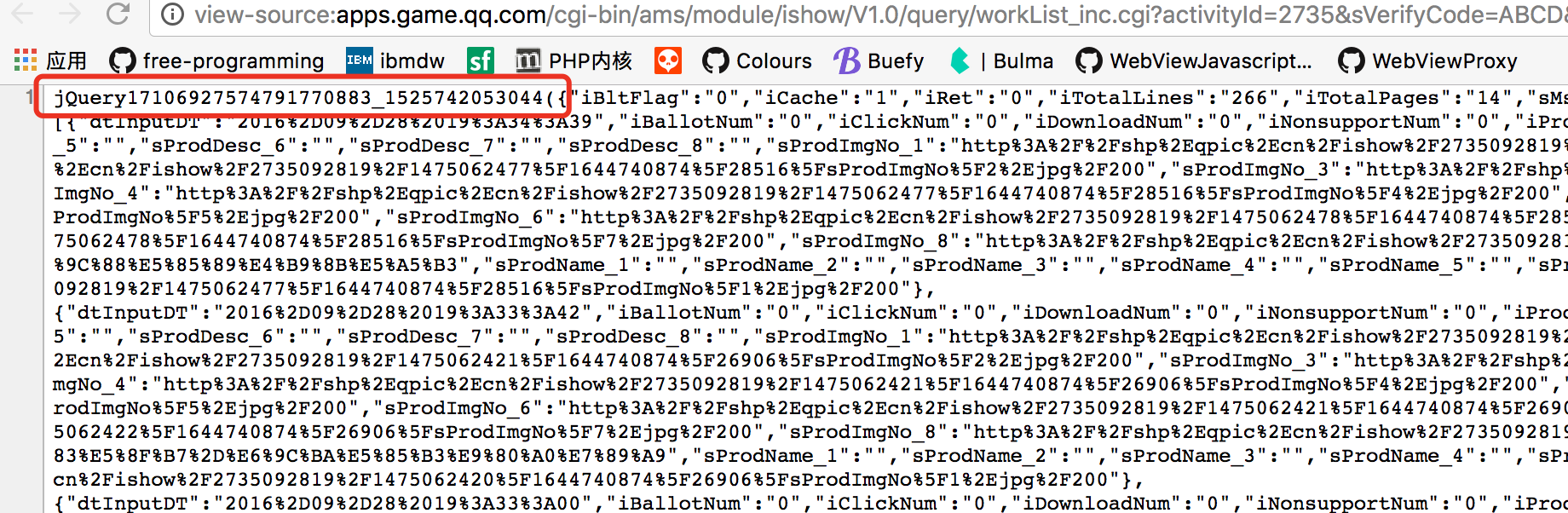
这种情况一般是callback后边对应了一个json对象,我们可以用python的 json 类库来解析:
解析数据千差万别,本文的数据相对简单,所以用了相对简单的处理方式:
## 这种解析数据的代码并不适用于所有的页面
def jsonContent(pageContent):
json_content = pageContent.split("(")[1].split(")")[0]
return json.loads(json_content)
解析完成以后的一个json对象属性如下:
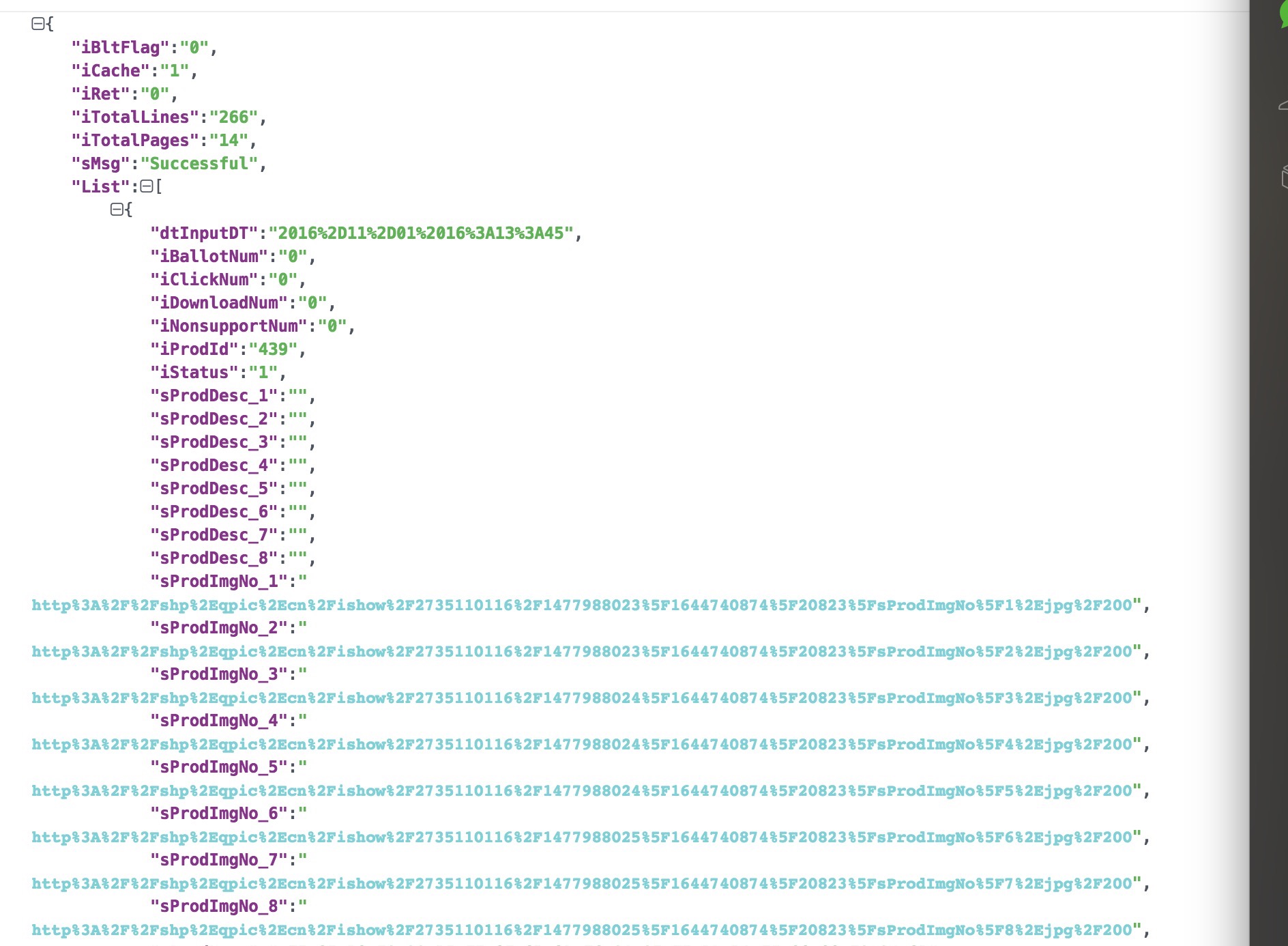
查看json 对象内容必备: https://www.json.cn/ 可以看到清晰的对象属性
很明显的,List 属性就是我们想要获取的壁纸对象了,然后,其中 sProdImgNo_1,2,3,4,5,6,7,8 中保存了,url 编码的图片url地址。
本实例为了演示我们只获取其中的 sProdImgNo_5 来做下载,大家可以根据需求做不同的遍历.
写一个简单的对象循环完成我们的子任务吧:
for item in pageJson['List']:
dealWithItem(item)
- 处理元素函数 , 下载文件图片:
观察发现图片url 是url编码好的地址: 我们可以用 urllib 的 unquote 方法转成原文:
获取的一个图片URL原文是这样的:

自行对比下,观测到的图片的真实地址如下:
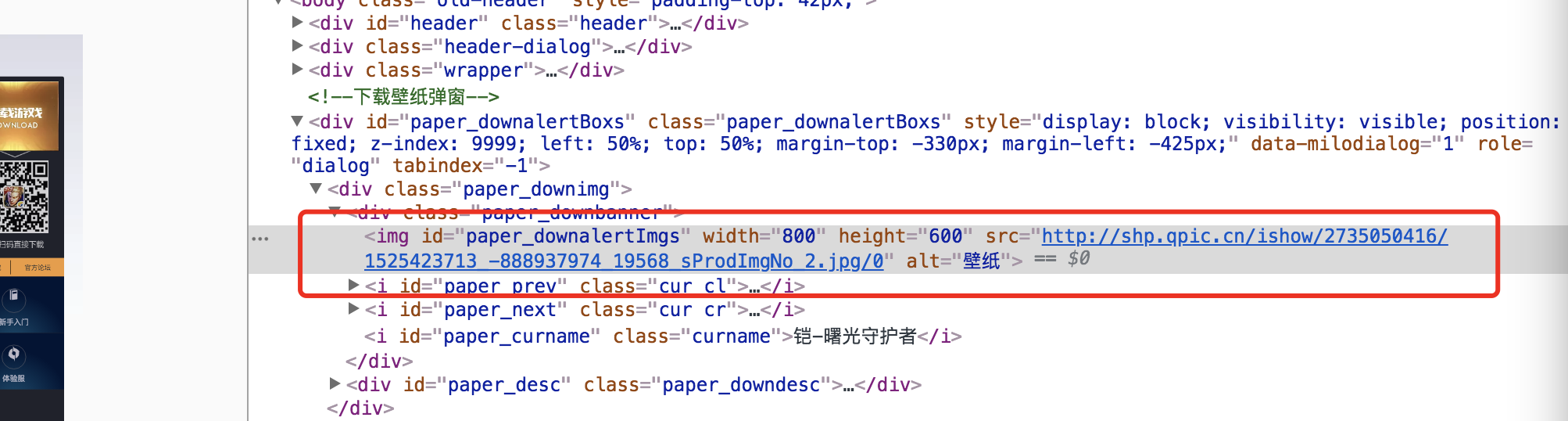
然后,我们只需要简单的把 200 replace 成0 就ok 了。
下载文件,直接通过requests get url 保存成文件就ok啦。
三、运行效果
- 最终展示下我们的成果吧:

四、项目文件结构

python 爬取王者荣耀高清壁纸
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权
最新文章
- 克隆虚机网卡出现 Device eth0 does not seem to be present, delaying initialization 错误
- [LeetCode] Subsets II 子集合之二
- linux 中更改用户权限和用户组的命令chmod,chgrp实例
- win 2012 关闭IE增强设置
- MatLab GUI Use Command for Debug 界面调试的一些方法
- MySQL无视密码进入Server
- 用一天的时间学习Java EE中的SSH框架
- java之String类型
- 浅谈 MVC中的ViewData、ViewBag和TempData
- HDU - 4995 - Revenge of kNN
- Redis主从复制(Master/Slave)
- 20165220 Java第五周学习总结
- Chapter3_操作符_直接常量和指数计数法
- 爬虫初窥day4:requests
- 并发编程之 Java 三把锁
- Week11分数
- [转载]Cortana 设计指导方针
- 12.2 linux下的线程
- gitlab人备份与恢复
- 使用maven将GitHub上项目打包作为依赖添加