urllib2爬取图片成功之后不能打开
2024-09-01 08:28:44
经过8个小时的摸索,终于决定写下此随笔!
初学爬虫,准备爬取百度美女吧的图片,爬取图片之后发现打不开,上代码:
import urllib
import urllib2
from lxml import etree def loadPage(url):
"""
作用:根据url发送请求,获取响应文件
url:需要爬取的url地址
""" print('正在下载' )
ua_headers = {
"User-Agent": "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)"
}
request = urllib2.Request(url, headers= ua_headers)
html = urllib2.urlopen(request).read()
# print html
content = etree.HTML(html)
link_list = content.xpath('//div[@class="t_con cleafix"]/div[2]/div[1]/div[1]/a/@href')
for link in link_list:
fulurl = 'http://tieba.baidu.com' + link
loadImage(fulurl) def loadImage(url):
print '正在下载图片'
ua_headers = {
"User-Agent": "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)"
}
request = urllib2.Request(url, headers=ua_headers)
html = urllib2.urlopen(request).read()
content = etree.HTML(html)
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
for link in link_list:
print(link)
writeImage(link)
def writeImage(url):
"""
作用:将HTML内容写入到本地
html:服务器响应文件内容
"""
ua_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/35.0.1916.114 Safari/537.36',
'Cookie': 'AspxAutoDetectCookieSupport=1'
}
request = urllib2.Request(url,headers = ua_headers)
response =urllib2.urlopen(request)
image = response.read()
filename = url[-10:]
print('正在保存' + filename)
# print image
with open(filename, "wb") as f:
f.write(image)
print(filename + '已保存') def tiebaSpider(url, beginPage, endPage):
""" 作用:贴吧爬虫调度器。负责组合处理每个页面的url
url:贴吧url的前部分
beginPage:起始页
endPage:结束页
""" for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50
fulurl = url + "&pn=" + str(pn)
loadPage(fulurl)
print('谢谢使用!') if __name__ == '__main__':
kw = raw_input('请输入需要爬取的贴吧名:')
beginPage = int(raw_input('请输入起始页:'))
endPage = int(raw_input('请输入结束页:')) url = 'http://tieba.baidu.com/f?'
key = urllib.urlencode({"kw": kw})
fulurl = url + key
tiebaSpider(fulurl,beginPage,endPage)
后来发现是writeImage()的参数跟函数体中调用的参数不一致导致的,
def writeImage(link):
"""
作用:将HTML内容写入到本地
html:服务器响应文件内容
"""
ua_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/35.0.1916.114 Safari/537.36',
'Cookie': 'AspxAutoDetectCookieSupport=1'
}
request = urllib2.Request(url,headers = ua_headers)
response =urllib2.urlopen(request)
image = response.read()
filename = url[-10:]
print('正在保存' + filename)
# print image
with open(filename, "wb") as f:
f.write(image)
print(filename + '已保存')
将参数改成跟函数体内一致后,爬取的图片总算可以正常查看了!下面看看成果吧: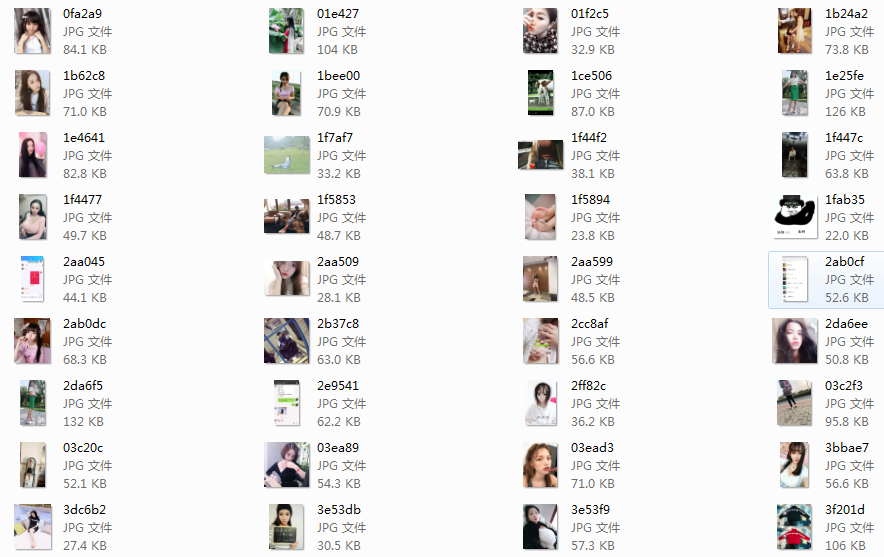
最新文章
- java根据标点英文分词
- [MySQL] SqlServer 迁移到 MySQL 方法介绍
- 下一代USB接口将支持双向拔插,于明年亮相
- RxJava学习入门
- tomcat 设置集群
- [AIR] AS3.0设置屏保功能
- delphi 更改不了窗体的标题
- Windows 8.1 (64bit) 下搭建 MongoDB 2.4.9 环境
- WampServer安装图解教程
- hdu 4300 Clairewd’s message KMP应用
- [HDU] 2063 过山车(二分图最大匹配)
- TMemoryStream、String与OleVariant互转
- C-Flex 与 box布局教程
- .NET Core快速入门教程 2、我的第一个.NET Core App(Windows篇)
- JDBCTemplate简化JDBC的操作(三)需要注意的地方
- python/SQLAchemy
- Sql学习笔记(二)—— 条件查询
- Could not resolve all dependencies for configuration ':classpath'
- keySet,entrySet用法 以及遍历map的用法
- pytest+allure+jenkins +python2.7