jmeter分析性能报告时的误区
概述
我们用jmeter做性能测试,必然需要学会分析测试报告。但是初学者常常因为对概念的不清晰,最后被测试报告带到沟里去。
常见的误区
- 分析响应时间全用平均值
- 响应时间不和吞吐量挂钩
- 响应时间和吞吐量不和成功率挂钩
。。。。。
平均值特别不靠谱
平均值为什么不靠谱?相信大家读新闻的时候经常可以看到,平均工资,平均房价,平均支出,等等字眼,你就知道为什么平均值不靠谱了。
(这些都是数学游戏)
性能测试也一样,平均数也是不靠谱,推荐一篇详细的文章《Why Averages Suck and Percentiles are Great》
我们做性能测试时,得到的结果数据不会总是一样的,而是波动的。
如果算平均值就会出现这样的情况:测试了10次,有9次是1ms,而有1次是10s,那么平均数据就是1s。
很明显,这完全不能反应性能测试的实际情况,因为那个10s的请求就是一个不正常的值。
另外,中位数(Median)可能会比平均数要稍微靠谱一些,中位数的意就是把将一组数据按大小顺序排列,处在最中间位置的一个数叫做这组数据的中位数 ,这意味着有50%的数据低于或高于这个中位数。
最为正确的统计做法是用百分比分布统计。TP50的意思是50%的响应时间都小于某个值,TP90表示90%的响应时间小于某个值。

我们有一组数据:[ 10ms, 1s, 200ms, 100ms],我们把其从小到大排个序:[10ms, 100ms, 200ms, 1s]。
于是我们知道,TP50,就是50%的请求ceil(4*0.5)=2时间是小于100ms的,TP90就是90%的请求ceil(4*0.9)=4时间小于1s。
于是:TP50就是100ms,TP90就是1s
因此,通常严格一点的响应时间要求是这样的:99%的请求必须小于XXms
响应时间务必和吞吐量(Thoughput)挂钩
系统的性能如果只看吞吐量,不看响应时间是没有意义的。
我的系统tps可以达到10000,但是响应时间已经到了20秒钟,这样的系统已经不可用了,吞吐量也是没有意义的。
当负载上升的时候,系统会逐渐变的不稳定,响应时间也会变得越来越慢,波动越来越大,而吞吐率却开始下降,包括CPU的使用率情况也会如此。
所以,当系统变得不稳定的时候,吞吐量已经没有意义了。
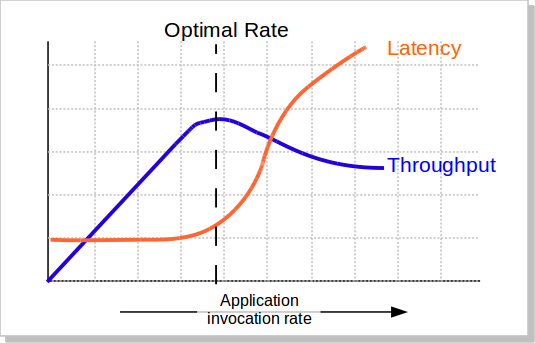
所以,吞吐量的值必需配合响应时间来看。例如:TP99小于100ms的时候,系统可以承载的最大并发数是1000。
响应时间吞吐量和成功率要挂钩
应该不难理解,如果请求都是错误的,还做什么性能测试。
比如,我说我的系统并发可以达到10万,但是失败率是50%,那么这10万的并发完全就是一个笑话。
性能测试的失败率的容忍是非常低的。对于一些关键系统,成功率必须在100%
最新文章
- TCP的阻塞和重传机制
- KANO模型
- mysql数据库的基本操作
- 入门-Arcmap网络分析示例
- dedecms不安全啊
- erl0006 - erlang 查看进程状态,查看当前系统那些进程比较占资源
- 【Unity3D】枪战游戏—发射子弹、射线检测
- Unity3D之Mecanim动画系统学习笔记(十一):高级功能应用
- 访问权限PPP(public、private、protected、default)之成员变量、成员变量权限解析
- 【HDOJ】1561 The more, The Better
- Orchard开源ASP.NET MVC CMS简介
- php导出excel数据
- 【.NET】字符串处理
- NSIndexPath 延伸
- MES设备支持快速完工
- mySQL使用实践
- HBase Rowkey 设计指南
- 4--TestNG测试报告
- CentOS 7下Samba服务安装与配置详解
- Redux 实现过程的推演