lucene_01_入门程序
索引和搜索流程图:
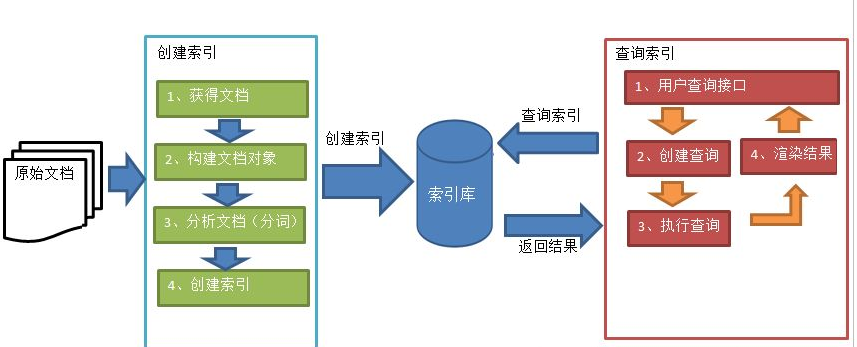
1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容->采集文档->创建文档->分析文档->素引文档
2、红色表示搜索过程,从索弓库中搜索内容,
搜索过程包括:
用户通过搜索界面->创建查询子执行搜索,从索引库搜索->渲染搜索结果
索引和搜索操作的对象为:索引库。
索引库中包含的部分:索引、原始文档。
原始文档:要索引和搜索的内容。原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。
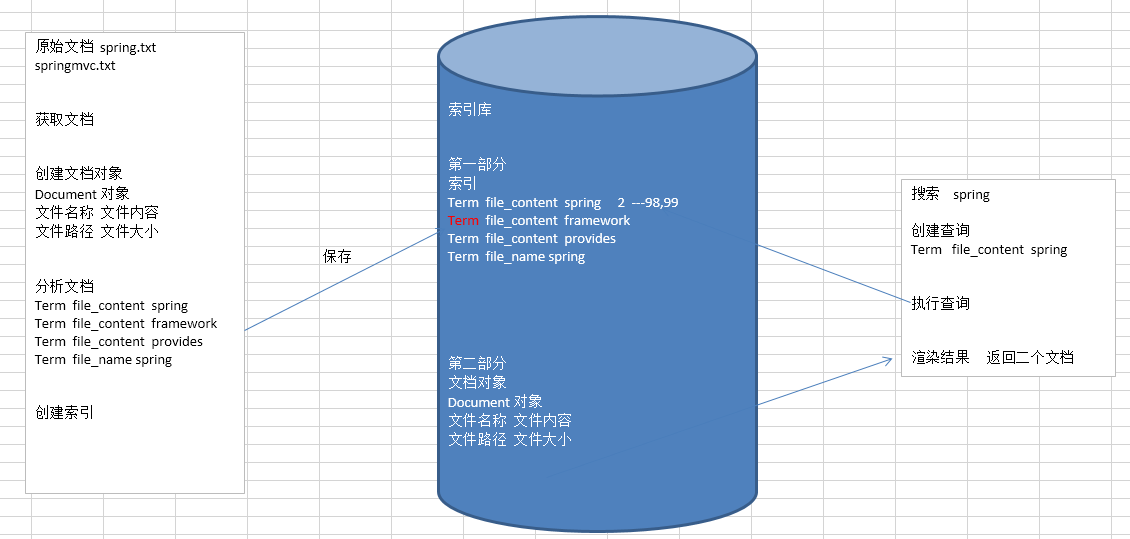
创建文档对象
获取原始内容的目的是为了索引,在索引前需要将原始內容创建成文档(Document),
文档中包括一个一个的域(Field),域中存储内容。
这里我们可以将磁盘上的-一个文件当成一个document,Document 中包括-一些Field
(file_mame文件名称、file_path文件路径、file_size 文件大小、file_content文件内容),如下图:

注意:
每个文档可以有多个Field,
不同的文档可以有不同的Field, —— 对于数据库办不到,每一行看作是一个document(文档),每一列看作是一个Filed.数据库的每一行的字段是固定的。
同一个 文档可以有相同的Field (域名和域值都相同)。—— 数据库中也不能有重复的字段
每个文档都有一个唯一的编号,就是文档id。—— 不同数据库的 id,该id不是域(对应于数据库的字段),无法进行操作,由系统维护。
域:是可以被我们操作的。
分析文档
分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过
程生成最终的语汇单元, 可以将语汇单元理解为一个一个的单词。
原文档内容:
Lucene is a Java full-text search engine.Lucene is not a completer
application,but rather a code library and API that can easily be used
to add search capabilities to applications.
分析后得到的语汇单元。
lucene、java、full、search、engine。。。
每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。
含两部分一部分是文档的域名,另一部分是单词的内容。。
例如: 文件名中包含apache和文件内容中包含的apache是不同的term.
注意: 创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。
传统方法是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺
序扫描方法,数据量大、搜索慢。
倒排索引结构是通过内容找文档,如下图:
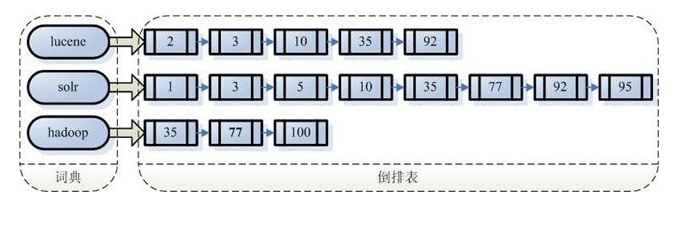
倒排索引结构也叫反向索引结构,包括索引和文档两个部分,索引即词汇表,它的规模较小,而文档集合较大。
入门代码实现
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.chen</groupId>
<artifactId>lucene</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging> <name>lucene</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.2.1</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.2.1</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.2.1</version>
</dependency> <!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency> </dependencies> <build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
创建索引
Field类
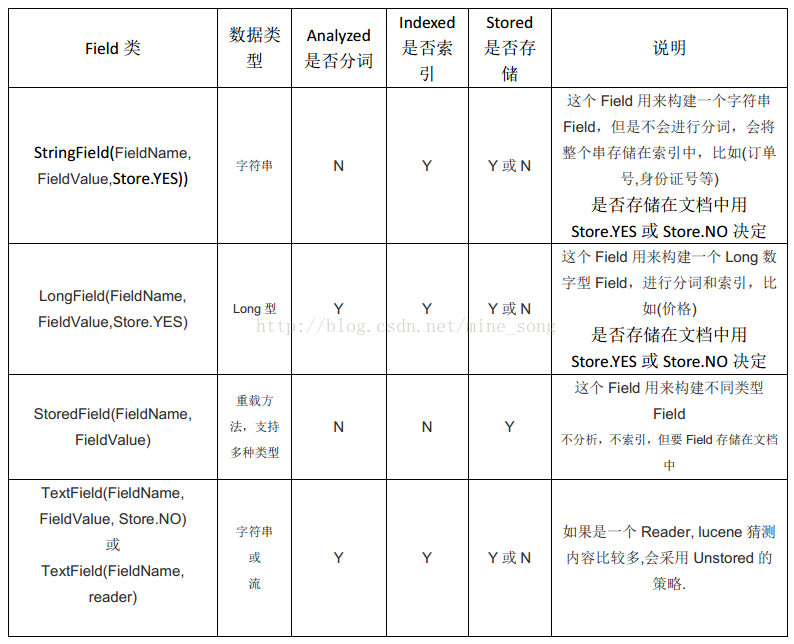
注在该版本中已经抛弃了LongField方法
@Test
public void createIndex() throws Exception{
// 第一步; 创建一个java工程,并导入jar包。
// 第二步: 创建一个indexwriter对象。
// 1) 指定索引库的存放位置Directory对象 Directory directory = FSDirectory.open(Paths.get("F:\\lucene\\indexDatabase")); // 2) 指定一个分听器,对文档内容进行分析。
IndexWriterConfig config = new IndexWriterConfig(new StandardAnalyzer());
IndexWriter indexWriter = new IndexWriter(directory,config);
// 第四步: 创建field对象,将field添加到document对象中。
File filedir = new File("F:\\lucene\\document");
if(filedir.exists() && filedir.isDirectory()){
File[] files = filedir.listFiles();
for (File file:files) {
// 第三步,创|建document对象。
Document document = new Document();
//获取文件的名称
String fileName = file.getName();
//创建textfield,保存文件名(key,value,是否存储)
TextField fileNameField = new TextField("fileName",fileName, Field.Store.YES);
//文件大小
long fileSize = FileUtils.sizeOf(file);
// new NumericDocValuesField("fileSize",fileSize);
SortedNumericDocValuesField fileSizeField = new SortedNumericDocValuesField("fileSize", fileSize);
//文件路径
String filePath = file.getPath();
StoredField filePathField = new StoredField("filePath", filePath);
//文件内容
String fileContent = FileUtils.readFileToString(file,"gbk");
TextField fileContentField = new TextField("fileContent", fileContent, Field.Store.YES);
document.add(fileNameField);
document.add(fileSizeField);
document.add(filePathField);
document.add(fileContentField); // 第五步: 使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写) 索引库。
indexWriter.addDocument(document);
}
}
// 第六步: 关闭IndexWriter对象。
indexWriter.close(); }
查询索引
根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档链表。
比如搜索语法为“fileName:lucee 表示搜索出fileName 域中包含Lucene 的文档。
搜索过程就是在索引上查找域为fileName,并且关键字为Llucene 的term,并根据term 找到文档id 列表。
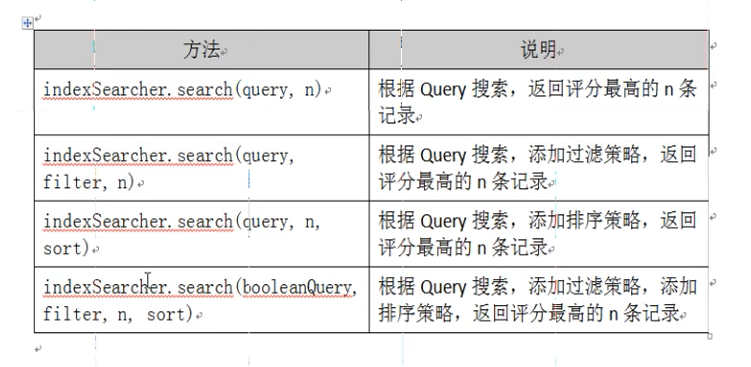
@Test
public void testSearcher() throws IOException {
// 第一步: 创建一个Directory 对象,也就是索引库存放的位置。
Directory directory = FSDirectory.open(Paths.get("F:\\lucene\\indexDatabase"));
// 第二步: 创建一个indexReader 对象,需要指定Directory 对象。
IndexReader indexReader = DirectoryReader.open(directory);
// 第三步: 创建一个indexsearcher 对象,需要指定InclexReader 对象。
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 第四步: 创建一个TermQuery对象,指定查询的域和查询的关键词。
// Term term = new Term("fileName", "java");
Term term = new Term("fileContent", "store");
Query query = new TermQuery(term);
// 第五步: 执行查询。
TopDocs topDocs = indexSearcher.search(query, 13);
// 第六步: 返回查询结果。遍历查询结果并输出。
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc doc : scoreDocs) {
int docIndex = doc.doc;
Document document = indexSearcher.doc(docIndex);
String fileName = document.get("fileName");
System.out.println(fileName);
String fileSize = document.get("fileSize");
System.out.println(fileSize);
String filePath = document.get("filePath");
System.out.println(filePath);
String fileContent = document.get("fileContent");
System.out.println(fileContent);
System.out.println("==========================");
}
// 第七步: 关闭IndexReader 对象。
indexReader.close(); }
最新文章
- wampserver 2.5 首页链接问题,wampserver Your Projects
- Java JDBC高级特性
- 数论(poj 1401)
- phpmailer 参数使用说明
- cocos进阶教程(3)Cocos2d-x多场景切换生命周期
- zabbix自定义键值原理
- java String与Byte[]和String 与InputStream转换时注意编码问题。。。
- Table of Contents - Lombok
- spring下配置dbcp,c3p0,proxool[转]
- WPF:警惕TextBox会占用过多内存
- vue 中结合百度地图获取当前城市
- weblogic10补丁升级与卸载
- 一些值得收藏的MySQL知识链接
- scrapy爬虫天猫笔记本电脑销量前60的商品
- position实现分层和遮罩层功能
- python语言中的数据类型之列表
- Codeforces Round #225 (Div. 2) E. Propagating tree dfs序+-线段树
- 问题集录--新手入门深度学习,选择TensorFlow 好吗?
- Hough变换的方法检测直线段,效果良好
- iOS NSRunloop