LPAT: Learning to Predict Adaptive Threshold for Weakly-supervised Temporal Action Localization [Paper Reading]
Motivation: 阈值分割的阈值并没有通过模型训练学出来,而是凭借主观经验设置,本文通过与背景得分比较提取对应的proposal,不用阈值的另一篇文章是Shou Zheng的AutoLoc,通过伪标签训练回归网络
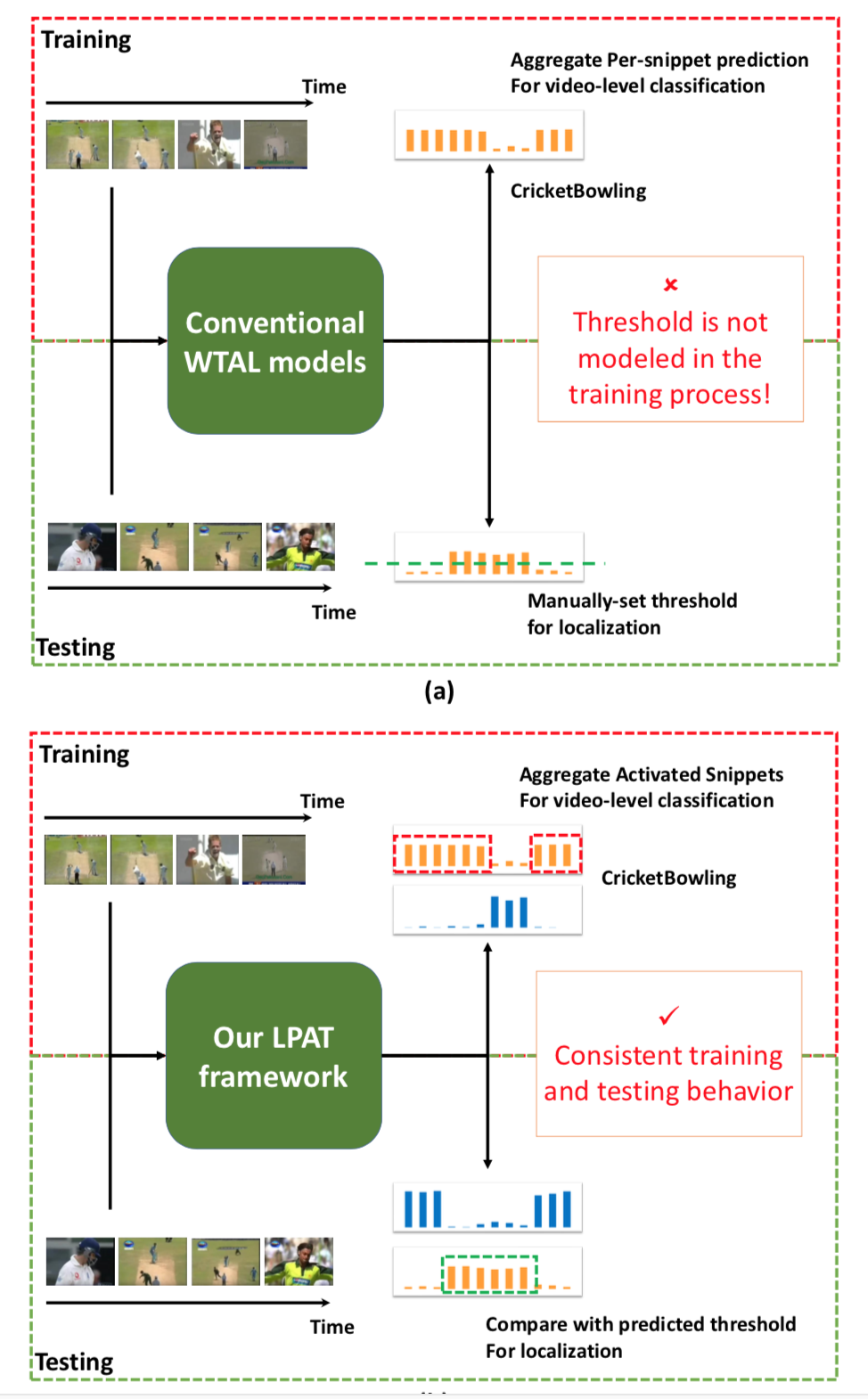
阈值分割缺点:低阈值会把多个动作实例ground-truth合并成一个动作实例,高阈值会将一个动作实例ground-truth分割成多个动作实例
忽略背景建模: 过去的方法没有对视频的背景建模无法利用动作和背景之间的先验知识
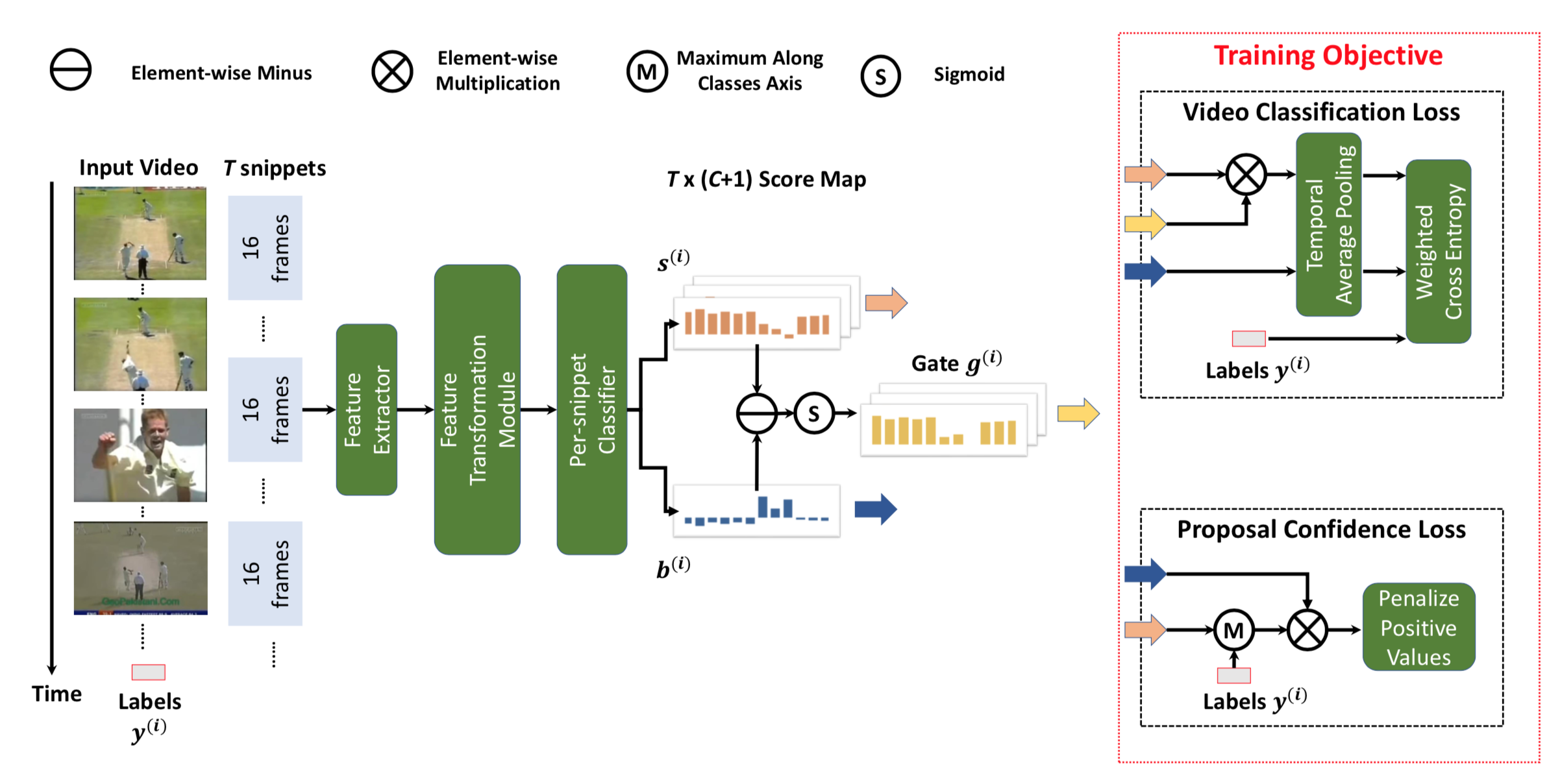
Feature Transformation Module: (1) full-connected (2) 1D时域卷积<+TemConv> 后接ReLU和Dropout(0.7)
Per-snippet Classifier: full-connected layer with linear activation
训练:
为了选出可能包含动作的视频帧用于视频分类,过去使用的方法有attention和top K(length*1/8)动作得分。作者通过添加背景类,引入这样的先验(如果帧片段的动作得分>背景得分,这样的帧片段将选为某类动作片段)
对每一个视频T*C的动作得分矩阵和T*1的背景得分矩阵求差,后接非线性函数
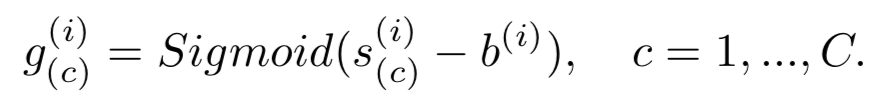
时域池化:用上一个公式求得的结果与原T*C的动作得分矩阵求加权和得到每个动作的平均分,背景类同理
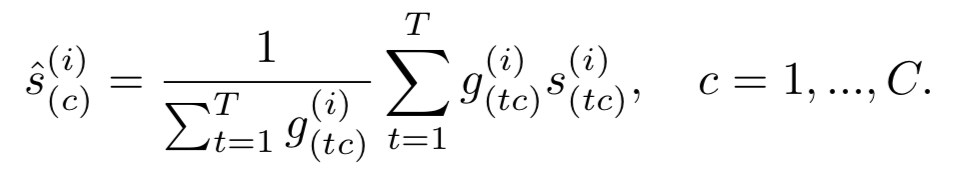
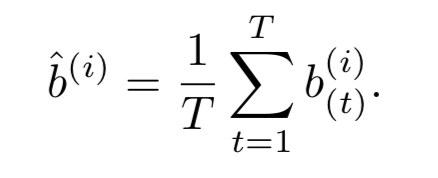
为了得到最后的置信得分对类别得分向量求softmax

最后求加权交叉熵loss用于视频分类,因为背景和动作的类别不平衡,实验将背景部分的权重wb设为1/C
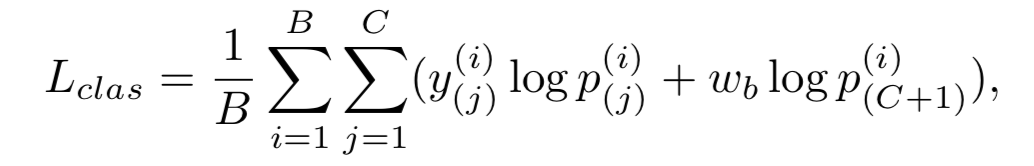
Proposal Confidence Loss
上面的约束用于对动作和背景建模,并没有对动作提名进一步约束,作者想进一步拉开threshold和动作得分之间的距离,这样产生的提名将获得高置信度
首先取ground-truth对应T*C'分数矩阵,对各个时间维度(T)沿类别维度(C')求最大值

约束每个视频片段的动作得分和背景得分是负数,有如下公式
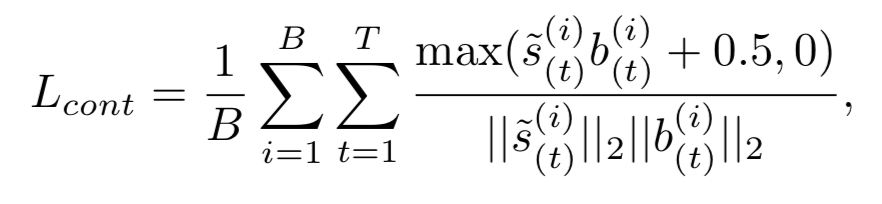
类似于余弦相似度,达到最小值时是s和b向量里每个元素都异号,这里的0.5为margin约束
Inference阶段:
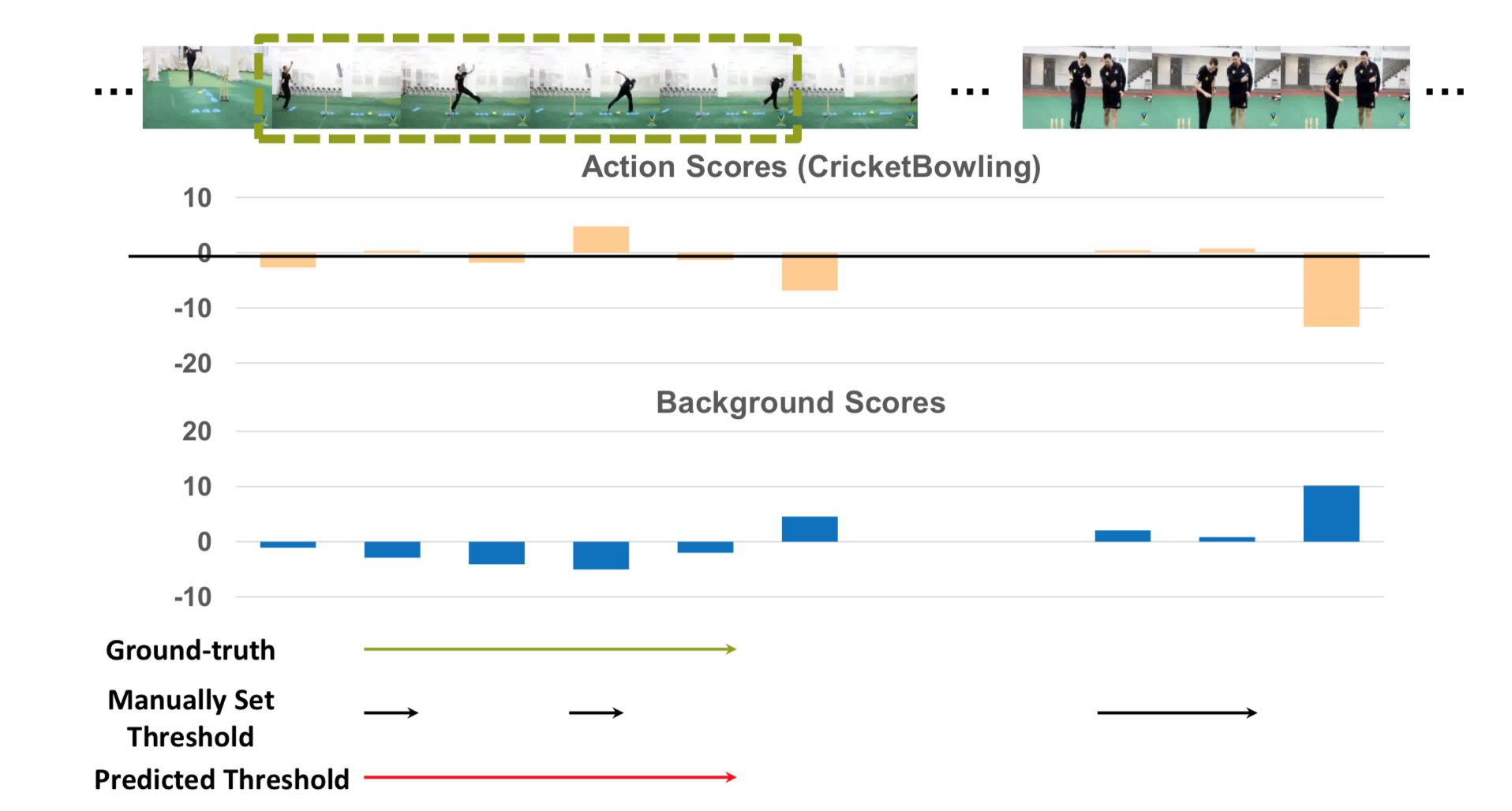
视频分类用的是softmax后的p得分向量,选取 > C类平均得分的类别为预测类别,然后定位每一个预测类别的动作片段,选取 动作得分 > 背景得分 的所有片段为最终的proposal,从而得到最终的 (start, end, score)
对比试验加入了WTALC的Co-Activity Similarity Loss约束

这种ranking hinge loss实现的约束使得最终的mAP0.5达到29.5,作为扩展视频中各类别动作发生的次数也可作为监督进一步提高模型的精度
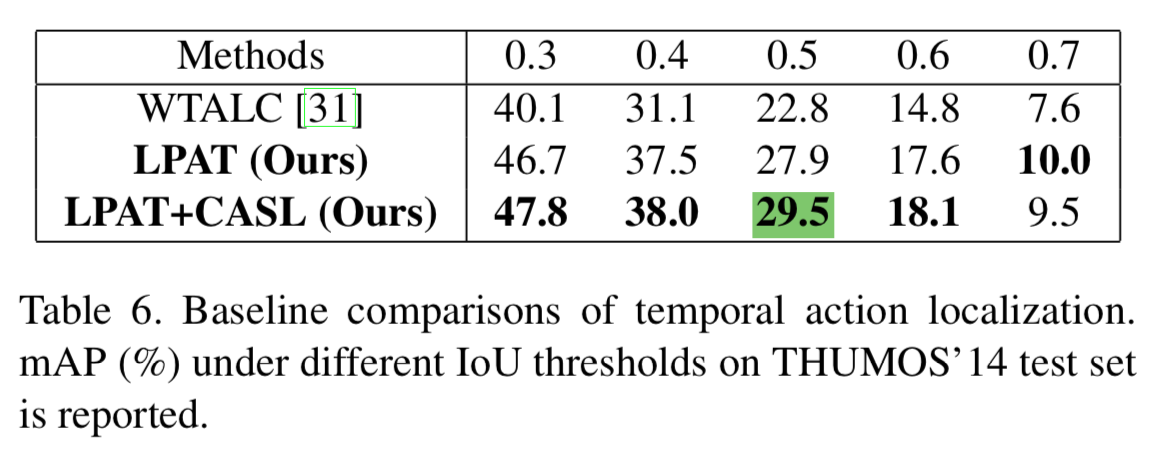
综上,个人觉得本文的方法非常clean & solid,很强的motivation没有强加模块的痕迹,最后的结果非常好,不知后续有没有这么干净的idea可以刷出新高度,拭目以待。
最新文章
- ObjectCopy
- SPOJ 11840. Sum of Squares with Segment Tree (线段树,区间更新)
- js+css3动态时钟-------Day66
- hdu2196Computer 树形DP
- arm-linux-objdump反汇编使用指南
- 【前端】Angular2 Ionic2 学习记录
- c++ 积累
- python集合set相关操作
- 移动H5页面微信支付踩坑之旅(微信支付、单页面路由模拟、按钮加锁、轮询等常见功能)
- Hdoj 2050.折线分割平面 题解
- svn 的truck、tag、 merge
- win10企业版2016长期服务版本激活
- c# Mongodb创建自增列
- Vultr搭建SS服务
- Kubernetes性能测试实践
- P4382 [八省联考2018]劈配
- ubuntu16.04 Detectron目标检测库配置(包含GPU驱动,Cuda,Caffee2等配置梳理)
- MyEclipse中出现Address already in use:JVM_Bind:8080
- 第六章 Validating with the Validation API
- IT兄弟连 JavaWeb教程 使用AJAX发送POST请求并获取响应