最近一年语义SLAM有哪些代表性工作?
点击“计算机视觉life”关注,置顶更快接收消息!
本文由作者刘骁授权发布,转载请联系原作者,个人主页http://www.liuxiao.org
目前 Semantic SLAM (注意不是 Semantic Mapping)工作还比较初步,可能很多思路还没有打开,但可以预见未来几年工作会越来越多。语义 SLAM 的难点在于怎样设计误差函数,将 Deep Learning 的检测或者分割结果作为一个观测,融入 SLAM 的优化问题中一起联合优化,同时还要尽可能做到至少 GPU 实时。
下面是一些有代表性的文章,提供下载和简单思路的理解,但个人精力、能力有限也欢迎大家随时提供更多更好的文章。
1、《Probabilistic Data Association for Semantic SLAM》 ICRA 2017
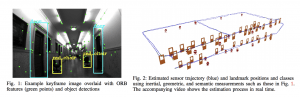
语义 SLAM 中的概率数据融合,感觉应该算开山鼻祖的一篇了。这篇也获得了 ICRA 2017 年的 Best Paper,可见工作是比较早有创新性的。文章中引入了 EM 估计来把语义 SLAM 转换成概率问题,优化目标仍然是熟悉的重投影误差。这篇文章只用了 DPM 这种传统方法做检测没有用流行的深度学习的检测网络依然取得了一定的效果。当然其文章中有很多比较强的假设,比如物体的三维中心投影过来应该是接近检测网络的中心,这一假设实际中并不容易满足。不过依然不能掩盖其在数学上开创性的思想。
文章下载:probabilistic-data-association-for-semantic-slam
2、《VSO: Visual Semantic Odometry》 ECCV 2018
既然检测可以融合,把分割结果融合当然是再自然不过的想法,而且直观看来分割有更加细粒度的对物体的划分对于 SLAM 这种需要精确几何约束的问题是更加合适的。ETH 的这篇文章紧随其后投到了今年的 ECCV 2018。这篇文章依然使用 EM 估计,在上一篇的基础上使用距离变换将分割结果的边缘作为约束,同时依然利用投影误差构造约束条件。在 ORB SLAM2 和 PhotoBundle 上做了验证取得了一定效果。这篇文章引入距离变换的思路比较直观,很多人可能都能想到,不过能够做 work 以及做了很多细节上的尝试,依然是非常不容易的。但仍然存在一个问题是,分割的边缘并不代表是物体几何上的边缘,不同的视角这一分割边缘也是不停变化的,因此这一假设也不是非常合理。
文章下载:vso-visual-semantic-odometry
3、《Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving》 ECCV 2018
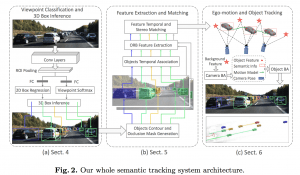
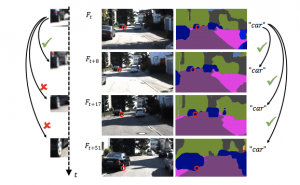
港科大沈邵劼老师团队的最新文章,他们的 VINS 在 VIO 领域具有很不错的开创性成果。现在他们切入自动驾驶领域做了这篇双目语义3D物体跟踪的工作,效果还是很不错的。在沈老师看来,SLAM 是一个多传感器融合的框架,RGB、激光、语义、IMU、码盘等等都是不同的观测,所以只要是解决关于定位的问题,SLAM 的框架都是一样适用的。在这篇文章中,他们将不同物体看成不同的 Map,一边重建一边跟踪。使用的跟踪方法仍然是传统的 Local Feature,而 VIO 作为世界坐标系的运动估计。语义融合方面,他们构造了4个优化项:
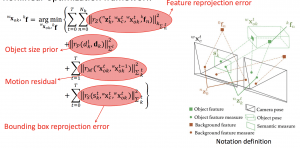
最终取得了很好的效果。
演示地址:https://www.youtube.com/watch?v=5_tXtanePdQ
文章下载:stereo-vision-based-semantic-3d-object-and-ego-motion-tracking-for-autonomous-driving
4、《Long-term Visual Localization using Semantically Segmented Images》ICRA 2018
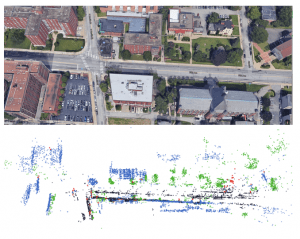
这篇论文讲得比较有意思,它不是一个完整的SLAM系统,不能解决Mapping的问题。它解决的问题是,当我已经有了一个很好的3D地图后,我用这个地图怎么来定位。在传统方法中,我们的定位也是基于特征匹配的,要么匹配 Local Feature 要么匹配线、边等等几何特征。而我们看人在定位时的思维,其实人看不到这么细节的特征的,通常人是从物体级别去定位,比如我的位置东边是某某大楼,西边有个学校,前边有个公交车,我自己在公交站牌的旁边这种方式。当你把你的位置这样描述出来的时候,如果我自己知道你说的这些东西在地图上的位置,我就可以基本确定你在什么地方了。这篇文章就有一点这种意思在里边,不过它用的观测结果是分割,用的定位方法是粒子滤波。它的地图是三维点云和点云上每个点的物体分类。利用这样语义级别的约束,它仍然达到了很好的定位效果。可想而知这样的方法有一定的优点,比如语义比局部特征稳定等;当然也有缺点,你的观测中的语义信息要比较丰富,如果场景中你只能偶尔分割出一两个物体,那是没有办法work的。
演示地址:https://www.youtube.com/watch?v=M55qTuoUPw0
文章下载:long-term-visual-localization-using-semantically-segmented-images
推荐阅读
从零开始一起学习SLAM | 为什么要学SLAM?
从零开始一起学习SLAM | 学习SLAM到底需要学什么?
从零开始一起学习SLAM | SLAM有什么用?
从零开始一起学习SLAM | C++新特性要不要学?
从零开始一起学习SLAM | 为什么要用齐次坐标?
从零开始一起学习SLAM | 三维空间刚体的旋转
从零开始一起学习SLAM | 为啥需要李群与李代数?
从零开始一起学习SLAM | 相机成像模型
从零开始一起学习SLAM | 不推公式,如何真正理解对极约束?
从零开始一起学习SLAM | 神奇的单应矩阵
从零开始一起学习SLAM | 你好,点云
从零开始一起学习SLAM | 给点云加个滤网
从零开始一起学习SLAM | 点云平滑法线估计
零基础小白,如何入门计算机视觉?
SLAM领域牛人、牛实验室、牛研究成果梳理
我用MATLAB撸了一个2D LiDAR SLAM
可视化理解四元数,愿你不再掉头发https://mp.weixin.qq.com/s?__biz=MzIxOTczOTM4NA==&mid=2247485009&idx=2&sn=3709bcff8efb4a3d1ff78fbb60d4f245&chksm=97d7e3c6a0a06ad07bfcebd0e17a9d58c821ddfc2016dc4b8914bc0c921d65b59243ed5efcc9&scene=21#wechat_redirect)
"欢迎关注公众号:计算机视觉life,一起探索计算机视觉新世界~"
最新文章
- react自学笔记总结不间断更新
- git版本回退, github版本回退
- sdcms标签
- jQuery选择器简单例子
- HDU1297 Children’s Queue (高精度+递推)
- The Shortest Path in Nya Graph---hdu4725(spfa+扩点建图)
- IOS 常用第三方库
- ScrollView与ListView合用(正确计算Listview的高度)的问题解决
- XML格式导出Excel
- [置顶] Guava学习之Immutable集合
- 【原创】leetCodeOj --- Sort List 解题报告
- Django 应用程序 + 模型 + 基本数据访问
- mysql概述
- 最全面的Spring-Boot-Cache使用与整合
- Centos7:查看某个端口被哪个进程占用
- spring的官方文档地址
- 前端开发【第5篇:JavaScript进阶】
- 手机app/h5页面http请求抓包调试
- Django源码分析之执行入口
- flush logs时做的操作
热门文章
- node 重新安装依赖模块
- [LeetCode] Fibonacci Number 斐波那契数字
- c++编译错误C2971:"std::array":array_size:包含非静态存储不能用作废类型参数;参见“std::array”的声明
- js 单行注释
- 错误提示:Dynamic Performance Tables not accessible, Automatic Statistics Disabled for this session You can disable statistics in the preference menu,or obtanin select priviliges on the v$session,v$sess
- 在win10环境下搭建 solr 开发环境
- 限制oracle某用户仅能从某IP登录
- Anveshak: Placing Edge Servers In The Wild
- [Swift]LeetCode988. 从叶结点开始的最小字符串 | Smallest String Starting From Leaf
- Storm学习笔记 - Storm初识