oneDNN
- oneDNN卷积思路
- debug捆绑套路
jit_avx2_convolution_fwd_t::execute_forward(- 整个文件oneDNN/src/cpu/x64/jit_avx2_conv_kernel_f32.hpp
- 整个文件src/cpu/x64/jit_avx2_conv_kernel_f32.cpp
- oneDNN的功效
oneDNN/src/cpu/x64/jit_generator.hpp- oneDNN源码编译和卷积demo
- oneDNN Documentation
- oneAPI Deep Neural Network Library (oneDNN)
- Documentation
- Installation
- System Requirements
- Applications Enabled with oneDNN
- Support
- Contributing
- License
- Security
- Trademark Information
- Building and Linking
- CNN f32 inference example
- 单个卷积和例子
- Alex 大例子
oneDNN/src/cpu/x64/jit_generator.hpponeDNN/src/cpu/x64/jit_generator.hpp里面的register_jit_code函数
oneDNN卷积思路
- 还是对于1x3x224x224输入
- 32个3x3s2p1
- 对于输入的每一行
- 从第1,3,5.。。行开始遍历
- 拿这这行数和卷机核的某行开始干啊!
debug捆绑套路
make -j4
cmake --build . --target install
g++ A.cc -std=c++11 -L /usr/local/lib -ldnnl
./a.out
jit_avx2_convolution_fwd_t::execute_forward(
void jit_avx2_convolution_fwd_t::execute_forward(const exec_ctx_t &ctx) const {
const auto &jcp = kernel_->jcp;
auto src = CTX_IN_MEM(const data_t *, DNNL_ARG_SRC);
auto weights = CTX_IN_MEM(const data_t *, DNNL_ARG_WEIGHTS);
auto bias = CTX_IN_MEM(const data_t *, DNNL_ARG_BIAS);
auto dst = CTX_OUT_MEM(data_t *, DNNL_ARG_DST);
const auto post_ops_binary_rhs_arg_vec
= binary_injector::prepare_binary_args(pd()->jcp_.post_ops, ctx);
const memory_desc_wrapper src_d(pd()->src_md());
const memory_desc_wrapper dst_d(pd()->dst_md());
const memory_desc_wrapper weights_d(pd()->weights_md(0));
const memory_desc_wrapper bias_d(pd()->weights_md(1));
const size_t ocb_work = div_up(jcp.nb_oc, jcp.nb_oc_blocking);
const size_t work_amount
= jcp.mb * jcp.ngroups * ocb_work * jcp.od * jcp.oh;
auto ker = [&](const int ithr, const int nthr) {
size_t start {0}, end {0};
balance211(work_amount, nthr, ithr, start, end);
//std::cout << "work_amount" << work_amount << std::endl;
//std::cout << "nthr" << nthr << std::endl;
//std::cout << "ithr" << ithr << std::endl;
bool is_ic_physically_blocked = one_of(jcp.src_tag, format_tag::nCw8c,
format_tag::nChw8c, format_tag::nCdhw8c);
int g_ic_offset = is_ic_physically_blocked ? jcp.nb_ic : jcp.ic;
int icb_ic_scale = is_ic_physically_blocked ? 1 : jcp.ic_block;
bool is_oc_physically_blocked = one_of(jcp.dst_tag, format_tag::nCw8c,
format_tag::nChw8c, format_tag::nCdhw8c);
//std::cout << "is_oc_physically_blocked" << is_oc_physically_blocked << std::endl;
int g_oc_offset = is_oc_physically_blocked ? jcp.nb_oc : jcp.oc;
std::cout << "jcp.ocjcp.ocjcp.oc" << jcp.nb_oc << std::endl;
int ocb_oc_scale = is_oc_physically_blocked ? 1 : jcp.oc_block;
int oc_bias_scale = is_oc_physically_blocked ? jcp.oc_block : 1;
int icbb = 0;
while (icbb < jcp.nb_ic) {
//std::cout << "jcp.nb_ic " << jcp.nb_ic << std::endl;
// 上面是1
//std::cout << "jcp.nb_ic " << jcp.nb_ic << std::endl;
int icb_step = jcp.nb_ic_blocking;
int icb_step_rem = jcp.nb_ic - icbb;
if (icb_step_rem < jcp.nb_ic_blocking_max) icb_step = icb_step_rem;
std::cout << "icb_stepicb_stepicb_step " << icb_step << std::endl;
size_t n {0}, g {0}, ocbb {0}, oh {0}, od {0};
nd_iterator_init(start, n, jcp.mb, g, jcp.ngroups, ocbb, ocb_work,
od, jcp.od, oh, jcp.oh);
std::cout << "ocb_numocb_num " << jcp.nb_oc_blocking << std::endl;
// 是112个数字啊!
for (size_t iwork = start; iwork < end; ++iwork) {
int ocb = ocbb * jcp.nb_oc_blocking;
// 上面每次加上4 啊!
std::cout << "ocbocbocb " << ocb << std::endl;
int ocb_num = jcp.nb_oc_blocking;
整个文件oneDNN/src/cpu/x64/jit_avx2_conv_kernel_f32.hpp
/*******************************************************************************
* Copyright 2016-2021 Intel Corporation
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*******************************************************************************/
#ifndef CPU_X64_JIT_AVX2_CONV_KERNEL_F32_HPP
#define CPU_X64_JIT_AVX2_CONV_KERNEL_F32_HPP
#include "common/c_types_map.hpp"
#include "common/memory.hpp"
#include "common/memory_tracking.hpp"
#include "cpu/x64/injectors/jit_uni_postops_injector.hpp"
#include "cpu/x64/jit_generator.hpp"
#include "cpu/x64/jit_primitive_conf.hpp"
namespace dnnl {
namespace impl {
namespace cpu {
namespace x64 {
struct jit_avx2_conv_fwd_kernel_f32 : public jit_generator {
jit_avx2_conv_fwd_kernel_f32(const jit_conv_conf_t &ajcp,
const primitive_attr_t &attr, const memory_desc_t &dst_md);
DECLARE_CPU_JIT_AUX_FUNCTIONS(jit_avx2_conv_fwd_kernel_f32)
static status_t init_conf(jit_conv_conf_t &jcp,
const convolution_desc_t &cd, const memory_desc_wrapper &src_d,
const memory_desc_wrapper &weights_d,
const memory_desc_wrapper &dst_d, const primitive_attr_t &attr);
static void init_scratchpad(memory_tracking::registrar_t &scratchpad,
const jit_conv_conf_t &jcp);
jit_conv_conf_t jcp;
const primitive_attr_t &attr_;
private:
std::unique_ptr<injector::jit_uni_postops_injector_t<avx2>>
postops_injector_;
constexpr static int isa_simd_width_
= cpu_isa_traits<avx2>::vlen / sizeof(float);
using reg64_t = const Xbyak::Reg64;
reg64_t reg_input = rax;
reg64_t aux_reg_input = r8;
reg64_t reg_kernel = rdx;
reg64_t aux_reg_kernel = r9;
reg64_t reg_output = rsi;
reg64_t reg_bias = rbx;
reg64_t aux_reg_inp_d = r11;
reg64_t aux_reg_ker_d = abi_not_param1;
reg64_t reg_ki = rsi;
reg64_t kj = r10;
reg64_t oi_iter = r11;
reg64_t ki_iter = r12;
reg64_t reg_channel = ki_iter;
reg64_t reg_kh = abi_not_param1;
reg64_t reg_oc_blocks = r14;
reg64_t imm_addr64 = r15;
reg64_t reg_long_offt = r15;
Xbyak::Reg32 reg_ci_flag = r13d;
Xbyak::Reg32 reg_oc_flag = r14d;
/* binary post-ops operand */
reg64_t temp_offset_reg = r12;
Xbyak::Ymm ytmp = Xbyak::Ymm(14);
inline void oh_step_unroll_kw(
int ur_w, int pad_l, int pad_r, int oc_blocks);
inline void oh_step_nopad(int ur_w, int pad_l, int pad_r, int oc_blocks);
void apply_postops(const int oc_blocks, const int ur_w, const int oc_tail);
inline void width_blk_step(int ur_w, int pad_l, int pad_r, int oc_blocks);
inline void solve_common(int oc_blocks);
inline dim_t filter_w_to_input(int ki, int oi = 0, int pad_l = 0) {
return ki * (jcp.dilate_w + 1) + oi * jcp.stride_w - pad_l;
};
inline dim_t filter_h_to_input(int ki) {
return ki * (jcp.dilate_h + 1) * jcp.iw;
};
inline dim_t filter_d_to_input(int ki) {
return ki * (jcp.dilate_d + 1) * jcp.iw * jcp.ih;
};
inline dim_t get_input_offset(int i_ic, int i_iw) {
dim_t offset;
if (utils::one_of(jcp.src_tag, format_tag::ncw, format_tag::nchw,
format_tag::ncdhw)) {
offset = i_ic * jcp.id * jcp.ih * jcp.iw + i_iw;
} else if (utils::one_of(jcp.src_tag, format_tag::nwc, format_tag::nhwc,
format_tag::ndhwc)) {
offset = i_iw * jcp.ic * jcp.ngroups + i_ic;
} else {
offset = i_iw * jcp.ic_block + i_ic;
}
return sizeof(float) * offset;
}
inline dim_t get_output_offset(int i_oc_block, int i_ow) {
dim_t offset;
if (utils::one_of(jcp.dst_tag, format_tag::nwc, format_tag::nhwc,
format_tag::ndhwc)) {
offset = i_ow * jcp.oc * jcp.ngroups + i_oc_block * jcp.oc_block;
} else {
offset = i_oc_block * jcp.od * jcp.oh * jcp.ow * jcp.oc_block
+ i_ow * jcp.oc_block;
}
//std::cout << "1123456532345654323456543offset "<< offset << std::endl;
return sizeof(float) * offset;
}
inline dim_t get_kernel_offset(int i_oc_block, int ki, int i_ic) {
dim_t block_step_size = jcp.ic_block * jcp.oc_block;
dim_t ic_block_step_size = jcp.kd * jcp.kh * jcp.kw * block_step_size;
//std::cout << "jcp.khjcp.khjcp.khjcp.khjcp.khjcp.kh" << jcp.kh << std::endl;
dim_t oc_block_step_size = jcp.nb_ic * ic_block_step_size;
dim_t offset = i_oc_block * oc_block_step_size + ki * block_step_size
+ i_ic * jcp.oc_block;
//std::cout << "offset" << offset << std::endl;
return sizeof(float) * offset;
}
inline bool is_src_layout_nxc() {
return utils::one_of(jcp.src_tag, format_tag::ndhwc, format_tag::nhwc,
format_tag::nwc);
}
void generate() override;
};
struct jit_avx2_conv_bwd_data_kernel_f32 : public jit_generator {
DECLARE_CPU_JIT_AUX_FUNCTIONS(jit_avx2_conv_bwd_data_kernel_f32)
jit_avx2_conv_bwd_data_kernel_f32(const jit_conv_conf_t &ajcp)
: jcp(ajcp) {}
static status_t init_conf(jit_conv_conf_t &jcp,
const convolution_desc_t &cd, const memory_desc_wrapper &diff_src_d,
const memory_desc_wrapper &weights_d,
const memory_desc_wrapper &diff_dst_d);
static void init_scratchpad(memory_tracking::registrar_t &scratchpad,
const jit_conv_conf_t &jcp);
jit_conv_conf_t jcp;
private:
using reg64_t = const Xbyak::Reg64;
reg64_t reg_ddst = rax;
reg64_t aux_reg_ddst = r8;
reg64_t reg_kernel = rdx;
reg64_t aux_reg_kernel = r10;
reg64_t reg_dsrc = rsi;
reg64_t aux_reg_ddst_oc_loop = rbx; // used in ndims < 5 case only
reg64_t aux_reg_kernel_oc_loop = abi_not_param1; /* used in ndims < 5
case only */
reg64_t aux_reg_dst_d = r12; // used in ndims == 5 case only
reg64_t aux_reg_ker_d = r14; // used in ndims == 5 case only
reg64_t reg_ki = abi_not_param1; // used in ndims == 5 case only
reg64_t kj = r11;
reg64_t oi_iter = r12;
reg64_t reg_kh = r14;
reg64_t reg_channel = r13; // used in ndims < 5 case only
reg64_t reg_channel_work = r9; // used in ndims < 5 case only
reg64_t reg_long_offt = r15;
reg64_t reg_reduce_work = reg_long_offt;
Xbyak::Reg32 reg_ci_flag = r13d; // used for nxc tails
inline void compute_loop(int ur_w, int l_overflow, int r_overflow);
void generate() override;
inline int get_iw_start(int ki, int l_overflow) {
int res = (jcp.iw - 1 + jcp.r_pad) % jcp.stride_w
+ l_overflow * jcp.stride_w
- (jcp.kw - 1 - ki) * (jcp.dilate_w + 1);
while (res < 0)
res += jcp.stride_w;
return res;
}
inline int get_iw_end(int ur_w, int ki, int r_overflow) {
if (utils::one_of(ur_w, jcp.iw, jcp.ur_w_tail))
ur_w += nstl::min(0, jcp.r_pad); // remove negative padding
int res = (ur_w - 1 + jcp.l_pad) % jcp.stride_w
+ r_overflow * jcp.stride_w - ki * (jcp.dilate_w + 1);
while (res < 0)
res += jcp.stride_w;
return ur_w - res;
}
inline dim_t filter_w_to_ddst(int ki, int oi = 0, int pad_l = 0) {
return (oi + pad_l - ki * (jcp.dilate_w + 1)) / jcp.stride_w;
}
inline dim_t get_ddst_offset(int i_oc_block, int i_ow, int i_oc) {
dim_t offset;
if (utils::one_of(jcp.dst_tag, format_tag::nwc, format_tag::nhwc,
format_tag::ndhwc)) {
offset = i_ow * jcp.oc * jcp.ngroups + i_oc_block * jcp.oc_block
+ i_oc;
} else {
offset = i_oc_block * jcp.od * jcp.oh * jcp.ow * jcp.oc_block
+ i_ow * jcp.oc_block + i_oc;
}
return sizeof(float) * offset;
}
inline dim_t get_dsrc_offset(int i_ic_block, int i_iw) {
dim_t offset;
if (utils::one_of(jcp.src_tag, format_tag::nwc, format_tag::nhwc,
format_tag::ndhwc)) {
offset = i_iw * jcp.ic * jcp.ngroups + i_ic_block * jcp.ic_block;
} else {
offset = i_ic_block * jcp.id * jcp.ih * jcp.iw * jcp.ic_block
+ i_iw * jcp.ic_block;
}
return sizeof(float) * offset;
}
inline dim_t get_kernel_offset(
int i_oc_block, int i_ic_block, int ki, int i_oc) {
dim_t block_step_size = jcp.ic_block * jcp.oc_block;
dim_t ic_block_step_size = jcp.kd * jcp.kh * jcp.kw * block_step_size;
dim_t oc_block_step_size = jcp.nb_ic * ic_block_step_size;
dim_t offset = i_oc_block * oc_block_step_size
+ i_ic_block * ic_block_step_size + ki * block_step_size
+ i_oc * jcp.ic_block;
return sizeof(float) * offset;
}
};
struct jit_avx2_conv_bwd_weights_kernel_f32 : public jit_generator {
DECLARE_CPU_JIT_AUX_FUNCTIONS(jit_avx2_conv_bwd_weights_kernel_f32)
jit_avx2_conv_bwd_weights_kernel_f32(const jit_conv_conf_t &ajcp)
: jcp(ajcp) {}
static status_t init_conf(jit_conv_conf_t &jcp,
const convolution_desc_t &cd, const memory_desc_wrapper &src_d,
const memory_desc_wrapper &diff_weights_d,
const memory_desc_wrapper &diff_dst_d);
static void init_scratchpad(memory_tracking::registrar_t &scratchpad,
const jit_conv_conf_t &jcp);
jit_conv_conf_t jcp;
private:
using reg64_t = const Xbyak::Reg64;
reg64_t reg_input = rax;
reg64_t reg_kernel = rdx;
reg64_t reg_output = rsi;
reg64_t b_ic = abi_not_param1;
reg64_t kj = r8;
reg64_t reg_kh = r9;
reg64_t reg_ur_w_trips = r10;
reg64_t reg_tmp = r11;
reg64_t reg_oj = r15;
reg64_t reg_ih_count = rbx;
reg64_t aux_reg_input = r12;
reg64_t aux_reg_kernel = r13;
reg64_t ki = r14;
reg64_t reg_long_offt = r11;
reg64_t reg_channel = reg_ih_count; // used for nxc tails
Xbyak::Reg32 reg_ci_flag = r9d; // used for nxc tails
inline void od_step_comeback_pointers();
inline void oh_step_comeback_pointers();
inline void compute_ic_block_step(int ur_w, int pad_l, int pad_r,
int ic_block_step, int input_offset, int kernel_offset,
int output_offset);
inline void compute_oh_step_disp();
inline void compute_oh_step_unroll_ow(int ic_block_step, int max_ur_w);
inline void compute_oh_step_common(int ic_block_step, int max_ur_w);
inline void compute_oh_loop_common();
inline dim_t get_input_offset(int i_ic, int i_iw) {
dim_t offset;
if (utils::one_of(jcp.src_tag, format_tag::ncw, format_tag::nchw,
format_tag::ncdhw)) {
offset = i_ic * jcp.id * jcp.ih * jcp.iw + i_iw;
} else if (utils::one_of(jcp.src_tag, format_tag::nwc, format_tag::nhwc,
format_tag::ndhwc)) {
offset = i_iw * jcp.ic * jcp.ngroups + i_ic;
} else {
offset = i_iw * jcp.ic_block + i_ic;
}
return sizeof(float) * offset;
}
inline dim_t get_output_offset(int i_oc_block, int i_ow) {
dim_t offset;
if (utils::one_of(jcp.dst_tag, format_tag::nwc, format_tag::nhwc,
format_tag::ndhwc)) {
offset = i_ow * jcp.oc * jcp.ngroups + i_oc_block * jcp.oc_block;
} else {
offset = i_oc_block * jcp.od * jcp.oh * jcp.ow * jcp.oc_block
+ i_ow * jcp.oc_block;
}
return sizeof(float) * offset;
}
inline dim_t get_kernel_offset(int ki, int i_ic) {
dim_t block_step_size = jcp.ic_block * jcp.oc_block;
dim_t offset = ki * block_step_size + i_ic * jcp.oc_block;
return sizeof(float) * offset;
}
void generate() override;
};
} // namespace x64
} // namespace cpu
} // namespace impl
} // namespace dnnl
#endif
整个文件src/cpu/x64/jit_avx2_conv_kernel_f32.cpp
/*******************************************************************************
* Copyright 2016-2021 Intel Corporation
* Copyright 2018 YANDEX LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*******************************************************************************/
#include "common/c_types_map.hpp"
#include "common/memory.hpp"
#include "common/nstl.hpp"
#include "common/type_helpers.hpp"
#include "common/utils.hpp"
#include "cpu/platform.hpp"
#include "cpu/x64/injectors/injector_utils.hpp"
#include "cpu/x64/injectors/jit_uni_binary_injector.hpp"
#include "cpu/x64/injectors/jit_uni_eltwise_injector.hpp"
#include "cpu/x64/jit_avx2_conv_kernel_f32.hpp"
#define GET_OFF(field) offsetof(jit_conv_call_s, field)
namespace dnnl {
namespace impl {
namespace cpu {
namespace x64 {
using namespace dnnl::impl::prop_kind;
using namespace dnnl::impl::format_tag;
using namespace dnnl::impl::memory_tracking::names;
using namespace dnnl::impl::utils;
using namespace Xbyak;
jit_avx2_conv_fwd_kernel_f32::jit_avx2_conv_fwd_kernel_f32(
const jit_conv_conf_t &ajcp, const primitive_attr_t &attr,
const memory_desc_t &dst_md)
: jit_generator(nullptr, MAX_CODE_SIZE, true, avx2)
, jcp(ajcp)
, attr_(attr) {
if (jcp.with_eltwise || jcp.with_binary) {
using namespace binary_injector;
static constexpr bool preserve_gpr = true;
static constexpr bool preserve_vmm = false;
static constexpr size_t helper_vmm_idx = 15;
static constexpr bool use_exact_tail_scalar_bcast = false;
const size_t tail_size = jcp.oc_without_padding % isa_simd_width_;
rhs_arg_static_params_t rhs_arg_static_params {helper_vmm_idx, r13, r14,
preserve_gpr, preserve_vmm,
GET_OFF(post_ops_binary_rhs_arg_vec),
memory_desc_wrapper(dst_md), tail_size,
use_exact_tail_scalar_bcast};
static_params_t static_params {this->param1, rhs_arg_static_params};
postops_injector_ = utils::make_unique<
injector::jit_uni_postops_injector_t<avx2>>(
this, jcp.post_ops, static_params);
}
}
void jit_avx2_conv_fwd_kernel_f32::oh_step_unroll_kw(
int ur_w, int pad_l, int pad_r, int oc_blocks) {
int kw = jcp.kw;
int stride_w = jcp.stride_w;
int dilate_w = jcp.dilate_w + 1;
int ic_block = jcp.ic_block;
int ic_tail = jcp.ic_tail;
for (int ki = 0; ki < kw; ki++) {// 这里我就选择了卷积核某行的ki列了!
int jj_start = nstl::max(0, div_up(pad_l - ki * dilate_w, stride_w));
// std::cout <<"cur_ic_blk:" <<jj_start<< std::endl;
int jj_end = ur_w
- nstl::max(0,
div_up(ki * dilate_w + pad_r - (kw - 1) * dilate_w,
stride_w));
// std::cout <<"jj_end:" <<jj_end<< std::endl;
auto compute = [=](int cur_ic_blk) {// 也就是通道啊!
// compute的函数功能是
for (int ifm2 = 0; ifm2 < cur_ic_blk; ifm2++) {// 开始选取一个通道了!0,1,2表示三个通道的意思吧!
for (int jj = jj_start; jj < jj_end; jj++) {
size_t inp_off = get_input_offset(
ifm2, filter_w_to_input(ki, jj, pad_l));
// 首先ki是每个卷积核的第ki列,jj是输出的索引吧!
//std::cout << "inp_off" << inp_off << std::endl;
//std::cout << "pad_l" << pad_l << std::endl;
vbroadcastss(Ymm(oc_blocks * ur_w + jj),//弄了3个输入到寄存器上去了!12,13,14!
make_safe_addr(
aux_reg_input, inp_off, reg_long_offt));
}
for (int ii = 0; ii < oc_blocks; ii++) {// 这是0,1,2,3表示4组,32/8=4啊!
vmovups(ymm15,
make_safe_addr(aux_reg_kernel,
get_kernel_offset(ii, ki, ifm2),
reg_long_offt));// 每组的kernekl拿到ymm15寄存器上面去!
// 牢记ifm2就是通道啊!
// ii就是命名4组的每一组啊!
//std::cout << "get_kernel_offset(ii, ki, ifm2)," <<get_kernel_offset(ii, ki, ifm2) << std::endl;
for (int jj = jj_start; jj < jj_end; jj++)//我觉得这里大部分时间都是3!
if (mayiuse(avx2))
{ vfmadd231ps(Ymm(ur_w * ii + jj),
Ymm(oc_blocks * ur_w + jj), ymm15);
//std::cout << "dsfsdfdssdfsd"<< (ur_w * ii + jj) << std::endl;
}
else { // Intel(R) Advanced Vector Extensions (Intel(R) AVX) support
vmulps(ytmp, ymm15, Ymm(oc_blocks * ur_w + jj));
vaddps(Ymm(ur_w * ii + jj), Ymm(ur_w * ii + jj),
ytmp);
}
}
}
};
if (ic_tail) {
if (jcp.ic == ic_tail)
compute(ic_tail);
else {
Label ic_blk_tail, ic_blk_done;
cmp(reg_channel, ic_block);
jl(ic_blk_tail, T_NEAR);
compute(ic_block);
jmp(ic_blk_done, T_NEAR);
L(ic_blk_tail);
compute(ic_tail);
L(ic_blk_done);
}
} else {
compute(ic_block);
}
}
}
void jit_avx2_conv_fwd_kernel_f32::oh_step_nopad(
int ur_w, int pad_l, int pad_r, int oc_blocks) {
Label kw_loop;
int kw = jcp.kw;
int ic_blk = jcp.ic_block;
xor_(ki_iter, ki_iter);
L(kw_loop);
{
int jj_start = 0;
int jj_end = ur_w;
for (int ifm2 = 0; ifm2 < ic_blk; ifm2++) {
for (int jj = jj_start; jj < jj_end; jj++) {
size_t inp_off = get_input_offset(
ifm2, filter_w_to_input(0, jj, pad_l));
vbroadcastss(Ymm(oc_blocks * ur_w + jj),
make_safe_addr(aux_reg_input, inp_off, reg_long_offt));
}
for (int ii = 0; ii < oc_blocks; ii++) {
vmovups(ymm15,
make_safe_addr(aux_reg_kernel,
get_kernel_offset(ii, 0, ifm2), reg_long_offt));
for (int jj = jj_start; jj < jj_end; jj++)
if (mayiuse(avx2))
vfmadd231ps(Ymm(ur_w * ii + jj),
Ymm(oc_blocks * ur_w + jj), ymm15);
else { // Intel AVX support
vmulps(ytmp, ymm15, Ymm(oc_blocks * ur_w + jj));
vaddps(Ymm(ur_w * ii + jj), Ymm(ur_w * ii + jj), ytmp);
}
}
}
safe_add(aux_reg_kernel, get_kernel_offset(0, 1, 0), reg_long_offt);
safe_add(aux_reg_input, get_input_offset(0, filter_w_to_input(1)),
reg_long_offt);
inc(ki_iter);
cmp(ki_iter, kw);
jl(kw_loop, T_NEAR);
}
}
static int get_ymm_idx(
const int ur_w, const int oc_block_idx, const int ur_w_idx) {
return (ur_w * oc_block_idx + ur_w_idx);
}
static Ymm get_ymm(const int ur_w, const int oc_block_idx, const int ur_w_idx) {
return Ymm(get_ymm_idx(ur_w, oc_block_idx, ur_w_idx));
}
template <typename F>
void iterate(const int load_loop_blk, const int ur, const int load_dim_tail,
const F &f) {
for (int i = 0; i < load_loop_blk; ++i) {
const bool mask_flag = (load_dim_tail > 0) && (i == load_loop_blk - 1);
for (int j = 0; j < ur; ++j)
f(mask_flag, i, j);
}
}
template <typename F>
void iterate(const int load_loop_blk, const int ur, const F &f) {
iterate(load_loop_blk, ur, 0, f);
}
void jit_avx2_conv_fwd_kernel_f32::apply_postops(
const int oc_blocks, const int ur_w, const int oc_tail) {
if (jcp.with_eltwise || jcp.with_binary) {
Label regular_store;
test(reg_ci_flag, FLAG_IC_LAST);
je(regular_store, T_NEAR);
injector_utils::vmm_index_set_t vmm_idxs;
if (jcp.with_binary) {
binary_injector::rhs_arg_dynamic_params_t rhs_arg_params,
rhs_arg_params_tail;
iterate(oc_blocks, ur_w, oc_tail,
[&](const bool mask_flag, const int i, const int j) {
const int aux_output_offset
= get_output_offset(i, j) / sizeof(float);
const auto vmm_idx = get_ymm_idx(ur_w, i, j);
vmm_idxs.emplace(vmm_idx);
rhs_arg_params_tail.vmm_idx_to_oc_elem_off_addr.emplace(
vmm_idx, ptr[param1 + GET_OFF(oc_l_off)]);
rhs_arg_params_tail.vmm_idx_to_oc_elem_off_val.emplace(
vmm_idx, i * jcp.oc_block);
rhs_arg_params_tail.vmm_idx_to_out_elem_off_val.emplace(
vmm_idx, aux_output_offset);
rhs_arg_params_tail.vmm_idx_to_out_off_oprnd.emplace(
vmm_idx, temp_offset_reg);
if (mask_flag)
rhs_arg_params_tail.vmm_tail_idx_.emplace(vmm_idx);
});
rhs_arg_params = rhs_arg_params_tail;
rhs_arg_params.vmm_tail_idx_.clear();
const injector_utils::register_preserve_guard_t register_guard(
this, {temp_offset_reg});
mov(temp_offset_reg, reg_output);
sub(temp_offset_reg, ptr[param1 + GET_OFF(dst_orig)]);
shr(temp_offset_reg, std::log2(sizeof(float)));
Label postops_done;
if (oc_tail) {
Label postops_no_tail;
test(reg_oc_flag, FLAG_OC_LAST);
je(postops_no_tail, T_NEAR);
postops_injector_->compute_vector_range(
vmm_idxs, rhs_arg_params_tail);
jmp(postops_done, T_NEAR);
L(postops_no_tail);
}
postops_injector_->compute_vector_range(vmm_idxs, rhs_arg_params);
L(postops_done);
} else {
iterate(oc_blocks, ur_w, [&](const bool, const int i, const int j) {
vmm_idxs.emplace(get_ymm_idx(ur_w, i, j));
});
postops_injector_->compute_vector_range(vmm_idxs);
}
L(regular_store);
}
}
void jit_avx2_conv_fwd_kernel_f32::width_blk_step(
int ur_w, int pad_l, int pad_r, int oc_blocks) {
int kw = jcp.kw;
int oc_blk = jcp.oc_block;
int oc_tail = jcp.oc_tail;
if (oc_tail) {
push(reg_oc_blocks);
mov(reg_oc_flag, ptr[param1 + GET_OFF(oc_flag)]);
}
auto load_output_bias_and_add_bias = [=](bool is_tail) {
Label init_done, init_first;
if (!jcp.with_sum) {
test(reg_ci_flag, FLAG_IC_FIRST);
jne(init_first, T_NEAR);
}
for (int ii = 0; ii < oc_blocks; ii++)// oc_bloaks 是32/8!
for (int jj = 0; jj < ur_w; jj++) {
const auto ymm = get_ymm(ur_w, ii, jj);
if (is_tail && ii == oc_blocks - 1)
load_bytes(ymm, reg_output, get_output_offset(ii, jj),
oc_tail * sizeof(float));
else
vmovups(ymm,
make_safe_addr(reg_output,
get_output_offset(ii, jj), reg_long_offt));
}
// 这里加了bias,那上面到底在干啥啊?
if (jcp.with_sum && jcp.with_bias) {
test(reg_ci_flag, FLAG_IC_FIRST);
je(init_done, T_NEAR);
for (int ii = 0; ii < oc_blocks; ii++)
for (int jj = 0; jj < ur_w; jj++) {
const Ymm ymm = get_ymm(ur_w, ii, jj);
if (is_tail && ii == oc_blocks - 1) {
load_bytes(ytmp, reg_bias, sizeof(float) * ii * oc_blk,
oc_tail * sizeof(float));
vaddps(ymm, ymm, ytmp);
} else {
vaddps(ymm, ymm,
yword[reg_bias + sizeof(float) * ii * oc_blk]);
}
}
}
jmp(init_done, T_NEAR);
L(init_first);
if (jcp.with_bias) {
for (int ii = 0; ii < oc_blocks; ii++)
for (int jj = 0; jj < ur_w; jj++) {
const Ymm ymm = get_ymm(ur_w, ii, jj);
if (is_tail && ii == oc_blocks - 1)
load_bytes(ymm, reg_bias, sizeof(float) * ii * oc_blk,
oc_tail * sizeof(float));
else
vmovups(ymm,
yword[reg_bias + sizeof(float) * ii * oc_blk]);
}
} else {
for (int ii = 0; ii < oc_blocks; ii++)
for (int jj = 0; jj < ur_w; jj++) {
const Ymm ymm = get_ymm(ur_w, ii, jj);
uni_vpxor(ymm, ymm, ymm);
}
}
L(init_done);
};// 上面这个lambda函数都在处理bias啊!,并且把结果放进寄存器,不拿出来了!
if (oc_tail) {
if (jcp.nb_oc > jcp.nb_oc_blocking) {
Label load_tail, load_done;
test(reg_oc_flag, FLAG_OC_LAST);
jne(load_tail, T_NEAR);
load_output_bias_and_add_bias(false);
jmp(load_done, T_NEAR);
L(load_tail);
load_output_bias_and_add_bias(true);
L(load_done);
} else {
load_output_bias_and_add_bias(true);
}
} else {
load_output_bias_and_add_bias(false);
}
if (one_of(jcp.ndims, 3, 4)) {
mov(aux_reg_input, reg_input);
mov(aux_reg_kernel, reg_kernel);
}
// 这里特码的想干啥啊?
Label skip_kh_loop, skip_kd_loop, kd_loop;
if (jcp.ndims == 5) {
push(reg_output);
push(oi_iter);
mov(reg_ki, ptr[param1 + GET_OFF(kd_padding)]);
mov(aux_reg_ker_d, ptr[param1 + GET_OFF(filt)]);
mov(aux_reg_inp_d, reg_input);
if ((jcp.dilate_d >= jcp.id)
|| (jcp.kd - 1) * (jcp.dilate_d + 1) < jcp.f_pad) {
cmp(reg_ki, 0);
je(skip_kd_loop, T_NEAR);
}
L(kd_loop);
mov(kj, ptr[param1 + GET_OFF(kh_padding)]);
} else {
mov(kj, reg_kh);
}
if (jcp.ndims == 5) {
mov(aux_reg_input, aux_reg_inp_d);
mov(aux_reg_kernel, aux_reg_ker_d);
}
if ((jcp.dilate_h >= jcp.ih)
|| (jcp.kh - 1) * (jcp.dilate_h + 1)
< nstl::max(jcp.t_pad, jcp.b_pad)) {
cmp(kj, 0);
je(skip_kh_loop, T_NEAR);
}
Label kh_loop;
// 下面的意思是kh ——loop
// 我感觉就是在这里开始了遍历卷积核的每一行了!
// 同时输入也要加一行吧?
/* 这里就开始对输入的每一行和卷积核的某一行开始搞啊搞!*/
L(kh_loop);
{
if (jcp.kw >= 5 && pad_l == 0 && pad_r == 0) {
oh_step_nopad(ur_w, pad_l, pad_r, oc_blocks);
add(aux_reg_input,
get_input_offset(0, filter_h_to_input(1))
- get_input_offset(0, filter_w_to_input(kw)));
} else {
oh_step_unroll_kw(ur_w, pad_l, pad_r, oc_blocks);
safe_add(
aux_reg_kernel, get_kernel_offset(0, kw, 0), reg_long_offt);
safe_add(aux_reg_input, get_input_offset(0, filter_h_to_input(1)),
reg_long_offt);
std::cout << "get_kernel_offset(0, kw, 0)" << get_kernel_offset(0, kw, 0) << std::endl;
// 权重是[N/8, H, W, C, 8]
// 没错!上面就是对卷积核与输入加一行啦!我真牛逼!
}
dec(kj);
cmp(kj, 0);
jg(kh_loop, T_NEAR);
}
L(skip_kh_loop);
if (jcp.ndims == 5) {
safe_add(aux_reg_inp_d, get_input_offset(0, filter_d_to_input(1)),
reg_long_offt);
safe_add(aux_reg_ker_d, get_kernel_offset(0, jcp.kw * jcp.kh, 0),
reg_long_offt);
dec(reg_ki);
cmp(reg_ki, 0);
jg(kd_loop, T_NEAR);
L(skip_kd_loop);
pop(oi_iter);
pop(reg_output);
}
apply_postops(oc_blocks, ur_w, oc_tail);
// 在这里开始store参数啦!
auto store_output = [=](bool is_tail, int tail) {
const auto is_padding = jcp.oc_without_padding != jcp.oc;
if (is_padding) uni_vxorps(ytmp, ytmp, ytmp);
for (int ii = 0; ii < oc_blocks; ii++)
for (int jj = 0; jj < ur_w; jj++) {
Ymm reg_out = get_ymm(ur_w, ii, jj);
//std::cout << reg_out.toString() << std::endl;
if (is_tail && ii == oc_blocks - 1) {
if (is_padding && jcp.with_binary) {
vmovups(make_safe_addr(reg_output,
get_output_offset(ii, jj),
reg_long_offt),
ytmp);
}
store_bytes(reg_out, reg_output, get_output_offset(ii, jj),
tail * sizeof(float));
} else
vmovups(make_safe_addr(reg_output,
get_output_offset(ii, jj), reg_long_offt),
reg_out);
}
};
if (oc_tail) {
if (jcp.nb_oc > jcp.nb_oc_blocking) {
Label store_tail, store_done;
test(reg_oc_flag, FLAG_OC_LAST);
jne(store_tail, T_NEAR);
store_output(false, oc_tail);
jmp(store_done, T_NEAR);
L(store_tail);
store_output(true, oc_tail);
L(store_done);
} else {
store_output(true, oc_tail);
}
} else {
Label regular_store;
Label store_done;
const int tail = jcp.oc_without_padding % jcp.oc_block;
if (jcp.with_binary && tail) {
test(reg_ci_flag, FLAG_IC_LAST);
je(regular_store, T_NEAR);
if (!oc_tail) mov(reg_oc_flag, ptr[param1 + GET_OFF(oc_flag)]);
test(reg_oc_flag, FLAG_OC_LAST);
je(regular_store, T_NEAR);
store_output(true, tail);
jmp(store_done, T_NEAR);
}
L(regular_store);
store_output(false, oc_tail);
L(store_done);
}
if (oc_tail) pop(reg_oc_blocks);
}
// 进入solve_coommon的时候已经可以确定输入的某行了,比如第3行
// 然后是整个卷积核了
inline void jit_avx2_conv_fwd_kernel_f32::solve_common(int oc_blocks) {
int ur_w = jcp.ur_w;
int ur_w_tail = jcp.ur_w_tail;
int n_oi = jcp.ow / ur_w;// 112/3= 37! //你的意思是每次产生3个数字吗?
int iw = jcp.iw;
int kw = jcp.kw;
int str_w = jcp.stride_w;
// oc_blocks是4啊!
int l_pad = jcp.l_pad;// 左边
int r_pad = nstl::max(0, jcp.r_pad);// 右边
// std::cout << r_pad << std::endl; //0
// std::cout << jcp.ur_w << std::endl;
// std::cout << jcp.iw << std::endl;
int r_pad1 = calculate_end_padding(l_pad, ur_w * n_oi, iw, str_w,
calculate_extended_filter_size(kw, jcp.dilate_w));
if (r_pad1 > 0) n_oi--;
if (l_pad > 0) {
n_oi--;
if (n_oi < 0 && r_pad1 > 0)
width_blk_step(ur_w, l_pad, r_pad1, oc_blocks); // "lrpad"
else
width_blk_step(ur_w, l_pad, 0, oc_blocks); // "lpad"
add(reg_input, get_input_offset(0, filter_w_to_input(0, ur_w, l_pad)));
add(reg_output, get_output_offset(0, ur_w));
}
Label ow_loop;
xor_(oi_iter, oi_iter);
if (n_oi > 0) {
L(ow_loop);
width_blk_step(ur_w, 0, 0, oc_blocks); // "middle"
add(reg_input, get_input_offset(0, filter_w_to_input(0, ur_w)));
add(reg_output, get_output_offset(0, ur_w));
// 这里才真正的开始卷积啦!,而且只展开了3 次哦!
inc(oi_iter);
cmp(oi_iter, n_oi);
jl(ow_loop, T_NEAR);
}
if (r_pad1 > 0 && n_oi >= 0) {
width_blk_step(ur_w, 0, r_pad1, oc_blocks); // "rpad"
add(reg_input, get_input_offset(0, filter_w_to_input(0, ur_w)));
add(reg_output, get_output_offset(0, ur_w));
}
if (ur_w_tail != 0)
width_blk_step(ur_w_tail, 0, r_pad, oc_blocks); // "tail"
}
void jit_avx2_conv_fwd_kernel_f32::generate() {
this->preamble();
mov(reg_input, ptr[this->param1 + GET_OFF(src)]);
mov(reg_output, ptr[this->param1 + GET_OFF(dst)]);
mov(reg_kernel, ptr[this->param1 + GET_OFF(filt)]);
if (jcp.with_bias) mov(reg_bias, ptr[this->param1 + GET_OFF(bias)]);
mov(reg_kh, ptr[this->param1 + GET_OFF(kh_padding)]);
mov(reg_ci_flag, ptr[this->param1 + GET_OFF(flags)]);
mov(reg_oc_blocks, ptr[this->param1 + GET_OFF(oc_blocks)]);
if (is_src_layout_nxc())
mov(reg_channel, ptr[param1 + GET_OFF(reduce_work)]);
int nb_oc_tail = jcp.nb_oc % jcp.nb_oc_blocking;
Label tail, exit;
if (jcp.nb_oc > jcp.nb_oc_blocking) {
cmp(reg_oc_blocks, jcp.nb_oc_blocking);
jne(nb_oc_tail ? tail : exit, T_NEAR);
solve_common(jcp.nb_oc_blocking);
jmp(exit, T_NEAR);
if (nb_oc_tail) {
L(tail);
cmp(reg_oc_blocks, nb_oc_tail);
jne(exit, T_NEAR);
solve_common(nb_oc_tail);
}
L(exit);
} else if (jcp.nb_oc == jcp.nb_oc_blocking) {
solve_common(jcp.nb_oc_blocking);
} else {
solve_common(nb_oc_tail);
}
this->postamble();
if (jcp.with_eltwise) postops_injector_->prepare_table();
}
status_t jit_avx2_conv_fwd_kernel_f32::init_conf(jit_conv_conf_t &jcp,
const convolution_desc_t &cd, const memory_desc_wrapper &src_d,
const memory_desc_wrapper &weights_d, const memory_desc_wrapper &dst_d,
const primitive_attr_t &attr) {
if (!mayiuse(avx)) return status::unimplemented;
jcp.isa = mayiuse(avx2) ? avx2 : avx;
jcp.nthr = dnnl_get_max_threads();
jcp.prop_kind = cd.prop_kind;
const bool with_groups = weights_d.ndims() == src_d.ndims() + 1;
int ndims = src_d.ndims();
jcp.ndims = ndims;
jcp.ngroups = with_groups ? weights_d.dims()[0] : 1;
jcp.mb = src_d.dims()[0];
jcp.oc = dst_d.dims()[1] / jcp.ngroups;
jcp.oc_without_padding = jcp.oc;
jcp.ic = src_d.dims()[1] / jcp.ngroups;
jcp.id = (ndims == 5) ? src_d.dims()[2] : 1;
jcp.ih = (ndims == 3) ? 1 : src_d.dims()[ndims - 2];
jcp.iw = src_d.dims()[ndims - 1];
jcp.od = (ndims == 5) ? dst_d.dims()[2] : 1;
jcp.oh = (ndims == 3) ? 1 : dst_d.dims()[ndims - 2];
jcp.ow = dst_d.dims()[ndims - 1];
jcp.kd = (ndims == 5) ? weights_d.dims()[with_groups + 2] : 1;
jcp.kh = (ndims == 3) ? 1 : weights_d.dims()[with_groups + ndims - 2];
jcp.kw = weights_d.dims()[with_groups + ndims - 1];
jcp.f_pad = (ndims == 5) ? cd.padding[0][0] : 0;
jcp.t_pad = (ndims == 3) ? 0 : cd.padding[0][ndims - 4];
jcp.l_pad = cd.padding[0][ndims - 3];
jcp.stride_d = (ndims == 5) ? cd.strides[0] : 1;
jcp.stride_h = (ndims == 3) ? 1 : cd.strides[ndims - 4];
jcp.stride_w = cd.strides[ndims - 3];
jcp.dilate_d = (ndims == 5) ? cd.dilates[0] : 0;
jcp.dilate_h = (ndims == 3) ? 0 : cd.dilates[ndims - 4];
jcp.dilate_w = cd.dilates[ndims - 3];
int ext_kw = calculate_extended_filter_size(jcp.kw, jcp.dilate_w);
int ext_kh = calculate_extended_filter_size(jcp.kh, jcp.dilate_h);
int ext_kd = calculate_extended_filter_size(jcp.kd, jcp.dilate_d);
jcp.r_pad = calculate_end_padding(
jcp.l_pad, jcp.ow, jcp.iw, jcp.stride_w, ext_kw);
jcp.b_pad = calculate_end_padding(
jcp.t_pad, jcp.oh, jcp.ih, jcp.stride_h, ext_kh);
jcp.back_pad = calculate_end_padding(
jcp.f_pad, jcp.od, jcp.id, jcp.stride_d, ext_kd);
bool kernel_outside_src = false || ext_kw <= jcp.l_pad
|| ext_kw <= jcp.r_pad || ext_kh <= jcp.t_pad || ext_kh <= jcp.b_pad
|| ext_kd <= jcp.f_pad || ext_kd <= jcp.back_pad;
if (kernel_outside_src) return status::unimplemented;
const auto dat_tag_nxc = pick(ndims - 3, nwc, nhwc, ndhwc);
const auto dat_tag_ncx = pick(ndims - 3, ncw, nchw, ncdhw);
const auto dat_tag_nCx8c = pick(ndims - 3, nCw8c, nChw8c, nCdhw8c);
auto wei_tag_OIxio = with_groups
? pick(ndims - 3, gOIw8i8o, gOIhw8i8o, gOIdhw8i8o)
: pick(ndims - 3, OIw8i8o, OIhw8i8o, OIdhw8i8o);
auto wei_tag_Oxio = with_groups ? pick(ndims - 3, gOwi8o, gOhwi8o, gOdhwi8o)
: pick(ndims - 3, Owi8o, Ohwi8o, Odhwi8o);
jcp.src_tag
= src_d.matches_one_of_tag(dat_tag_ncx, dat_tag_nxc, dat_tag_nCx8c);
jcp.wei_tag = weights_d.matches_one_of_tag(wei_tag_OIxio, wei_tag_Oxio);
jcp.dst_tag = dst_d.matches_one_of_tag(dat_tag_nxc, dat_tag_nCx8c);
jcp.typesize_in = types::data_type_size(src_d.data_type());
jcp.typesize_out = types::data_type_size(dst_d.data_type());
bool is_data_layout_nxc
= everyone_is(dat_tag_nxc, jcp.src_tag, jcp.dst_tag);
// Disable this kernel on high width 1d object as gemm performs better until
// optimizations can be made to fix it.
if (is_data_layout_nxc && ndims == 3 && jcp.ow > 11 * 1024)
return status::unimplemented;
jcp.with_bias = cd.bias_desc.format_kind != format_kind::undef;
const auto &post_ops = attr.post_ops_;
jcp.with_sum = post_ops.find(primitive_kind::sum) != -1;
const int eltwise_ind = post_ops.find(primitive_kind::eltwise);
jcp.with_eltwise = eltwise_ind != -1;
const int binary_ind = post_ops.find(primitive_kind::binary);
jcp.with_binary = binary_ind != -1;
jcp.post_ops = post_ops;
const int simd_w = 8;
const bool flat = jcp.ic < simd_w;
const bool mimo = !flat;
/* Grouped channel offset to support 'non-blocked data' format for
* convolution sizes with '(input_channel / ngroups) < simd' */
jcp.nonblk_group_off
= one_of(jcp.src_tag, ncw, nchw, ncdhw) && jcp.ngroups > 1 ? jcp.ic
: 1;
bool ok_to_pad_channels = true && !is_data_layout_nxc && jcp.ngroups == 1;
if (ok_to_pad_channels) {
jcp.oc = rnd_up(jcp.oc, simd_w);
if (mimo) jcp.ic = rnd_up(jcp.ic, simd_w);
}
if (jcp.with_eltwise || jcp.with_binary)
if (!mayiuse(avx2)) return status::unimplemented;
using namespace injector;
static constexpr bool sum_at_pos_0_only = true;
static constexpr bool sum_requires_scale_one = true;
static constexpr bool sum_requires_zp_zero = true;
const bool post_ops_ok_ = post_ops_ok({avx2, {eltwise, binary, sum},
jcp.post_ops, &dst_d, sum_at_pos_0_only, sum_requires_scale_one,
sum_requires_zp_zero});
if (!post_ops_ok_) return status::unimplemented;
bool args_ok = true
&& IMPLICATION(flat,
jcp.wei_tag == wei_tag_Oxio
&& ((jcp.src_tag == dat_tag_ncx
&& jcp.dst_tag == dat_tag_nCx8c)
|| (jcp.src_tag == dat_tag_nxc
&& jcp.dst_tag == dat_tag_nxc)))
&& IMPLICATION(mimo,
jcp.wei_tag == wei_tag_OIxio
&& ((jcp.src_tag == dat_tag_nCx8c
&& jcp.dst_tag == dat_tag_nCx8c)
|| (jcp.src_tag == dat_tag_nxc
&& jcp.dst_tag == dat_tag_nxc)))
&& jcp.ic <= src_d.padded_dims()[1]
&& jcp.oc <= dst_d.padded_dims()[1];
if (!args_ok) return status::unimplemented;
jcp.ur_h = 1; /* no code-unrolling by h so far */
jcp.ur_w = 3;
jcp.oc_block = simd_w;
jcp.nb_oc = div_up(jcp.oc, jcp.oc_block);
jcp.nb_oc_blocking = 4; /* the optimal value for the kernel */
// Intel AVX and Intel AVX2 kernels need 2 and 1 temporary YMMs, respectively
// Thus, we can only assign 14 or 15 YMMs for data storage
const int num_avail_regs = mayiuse(avx2) ? 15 : 14;
if (!mayiuse(avx2)) {
if ((jcp.nb_oc_blocking + 1) * jcp.ur_w > num_avail_regs) {
// current register assignment requires more YMMs than available
// adjust one of nb_oc_block, ur_w preserving to ur_w >= l_pad
if (jcp.ur_w > jcp.l_pad && jcp.ur_w > 1)
jcp.ur_w -= 1;
else {
for (int b = 3; b > 1; b--) {
if (jcp.nb_oc % b == 0) {
jcp.nb_oc_blocking = b;
break;
}
}
if ((jcp.nb_oc_blocking + 1) * jcp.ur_w > num_avail_regs) {
// No optimal size for 'nb_oc_blocking' with regards to
// 'nb_oc', default to only unroll by 'ur_w'.
jcp.nb_oc_blocking = 1;
}
}
}
}
if (jcp.ow < jcp.ur_w) jcp.ur_w = jcp.ow;
jcp.ur_w_tail = jcp.ow % jcp.ur_w;
args_ok = true && IMPLICATION(!is_data_layout_nxc, jcp.oc % simd_w == 0)
&& jcp.l_pad <= jcp.ur_w
&& IMPLICATION(jcp.kw > 7,
(jcp.t_pad == 0 && jcp.l_pad == 0)
|| (jcp.stride_w == 1 && jcp.stride_h == 1))
&& IMPLICATION(mimo && !is_data_layout_nxc, jcp.ic % simd_w == 0);
if (!args_ok) return status::unimplemented;
jcp.ic_tail = is_data_layout_nxc ? jcp.ic % simd_w : 0;
jcp.oc_tail = is_data_layout_nxc
? jcp.oc % simd_w
: (jcp.with_binary ? jcp.oc_without_padding % simd_w : 0);
int r_pad_no_tail = nstl::max(0,
calculate_end_padding(jcp.l_pad, jcp.ow - jcp.ur_w_tail, jcp.iw,
jcp.stride_w, ext_kw));
if (r_pad_no_tail > jcp.ur_w * jcp.stride_w && jcp.ow / jcp.ur_w > 1) {
/* recalculate ur_w, nb_oc_blocking and ur_w_tail */
jcp.ur_w = nstl::min(r_pad_no_tail / jcp.stride_w + jcp.ur_w_tail,
nstl::min(jcp.ow, num_avail_regs / 2));
jcp.nb_oc_blocking = (num_avail_regs - jcp.ur_w) / jcp.ur_w;
jcp.ur_w_tail = jcp.ow % jcp.ur_w;
/* check again ... */
r_pad_no_tail = nstl::max(0,
calculate_end_padding(jcp.l_pad, jcp.ow - jcp.ur_w_tail, jcp.iw,
jcp.stride_w, ext_kw));
if (jcp.ur_w < nstl::max(jcp.l_pad, r_pad_no_tail))
return status::unimplemented;
}
assert(jcp.nb_oc_blocking > 0);
assert(jcp.ur_w * (jcp.nb_oc_blocking + 1) <= num_avail_regs);
jcp.ic_block = flat ? jcp.ic : simd_w;
jcp.nb_ic = div_up(jcp.ic, jcp.ic_block);
jcp.nb_ic_blocking = 12;
jcp.nb_ic_blocking_max = 16;
/* adjust the thread decomposition
* to improve the perf for small problem size
* the threshold L1_cache_size is empirical
* simply set the thread as 4 for now
* TODO: Add get_thr_eff func to get the optimal thread number*/
size_t wei_size = (size_t)sizeof(float) * jcp.ic * jcp.oc * jcp.kh * jcp.kw
* jcp.kd;
size_t inp_size = (size_t)jcp.typesize_in * jcp.mb * jcp.ic * jcp.ih
* jcp.iw * jcp.id;
size_t out_size = (size_t)jcp.typesize_out * jcp.mb * jcp.oc * jcp.oh
* jcp.ow * jcp.od;
size_t total_size = jcp.ngroups * (wei_size + inp_size + out_size);
const unsigned int L1_cache_size = platform::get_per_core_cache_size(1);
if (jcp.ngroups < jcp.nthr && total_size < L1_cache_size) {
jcp.nthr = nstl::min(jcp.nthr, 4);
}
return status::success;
}
void jit_avx2_conv_fwd_kernel_f32::init_scratchpad(
memory_tracking::registrar_t &scratchpad, const jit_conv_conf_t &jcp) {
if (jcp.with_bias && jcp.oc != jcp.oc_without_padding)
scratchpad.book<float>(key_conv_padded_bias, jcp.oc);
}
void jit_avx2_conv_bwd_data_kernel_f32::compute_loop(
int ur_w, int l_overflow, int r_overflow) {
int kw = jcp.kw;
int ow = jcp.ow;
int oc_block = jcp.oc_block;
int nb_ic_block = jcp.nb_ic_blocking;
int stride_w = jcp.stride_w;
int stride_h = jcp.stride_h;
int oc_tail = jcp.oc_tail;
int ic_tail = jcp.ic_tail;
Label kd_loop, skip_kd_loop;
Label oc_loop, skip_oc_loop;
for (int ii = 0; ii < nb_ic_block; ii++)
for (int jj = 0; jj < ur_w; jj++) {
uni_vpxor(Ymm(ur_w * ii + jj), Ymm(ur_w * ii + jj),
Ymm(ur_w * ii + jj));
}
if (oc_tail) {
push(reg_long_offt);
mov(reg_reduce_work, ptr[param1 + GET_OFF(reduce_work)]);
}
if (one_of(jcp.ndims, 3, 4)) {
cmp(reg_channel_work, 0);
jle(skip_oc_loop, T_NEAR);
xor_(reg_channel, reg_channel);
mov(aux_reg_ddst_oc_loop, reg_ddst);
mov(aux_reg_kernel_oc_loop, reg_kernel);
L(oc_loop);
mov(aux_reg_ddst, aux_reg_ddst_oc_loop);
mov(aux_reg_kernel, aux_reg_kernel_oc_loop);
}
if (jcp.ndims == 5) {
assert(jcp.nb_oc_blocking == 1);
push(oi_iter);
mov(reg_ki, ptr[this->param1 + GET_OFF(kd_padding)]);
cmp(reg_ki, 0);
jle(skip_kd_loop, T_NEAR);
mov(aux_reg_dst_d, reg_ddst);
mov(aux_reg_ker_d, ptr[this->param1 + GET_OFF(filt)]);
L(kd_loop);
mov(kj, ptr[this->param1 + GET_OFF(kh_padding)]);
} else {
mov(kj, reg_kh);
}
if (jcp.ndims == 5) {
mov(aux_reg_ddst, aux_reg_dst_d);
mov(aux_reg_kernel, aux_reg_ker_d);
}
Label kh_loop, skip_kh_loop;
cmp(kj, 0);
jle(skip_kh_loop, T_NEAR);
L(kh_loop);
{
for (int ki = 0; ki < kw; ki++) {
int jj_start = get_iw_start(ki, l_overflow); // 0;
int jj_end = get_iw_end(ur_w, ki, r_overflow); // ur_w;
auto compute = [=](int cur_oc_blk) {
for (int ofm2 = 0; ofm2 < cur_oc_blk; ofm2++) {
for (int jj = jj_start; jj < jj_end; jj += stride_w) {
int aux_output_offset = get_ddst_offset(
0, filter_w_to_ddst(ki, jj, jcp.l_pad), ofm2);
vbroadcastss(Ymm(nb_ic_block * ur_w + jj / stride_w),
ptr[aux_reg_ddst + aux_output_offset]);
}
for (int ii = 0; ii < nb_ic_block; ii++) {
vmovups(ymm15,
ptr[aux_reg_kernel
+ get_kernel_offset(0, ii, ki, ofm2)]);
for (int jj = jj_start; jj < jj_end; jj += stride_w)
vfmadd231ps(Ymm(ur_w * ii + jj),
Ymm(nb_ic_block * ur_w + jj / stride_w),
ymm15);
}
}
};
if (oc_tail) {
if (jcp.oc == oc_tail)
compute(oc_tail);
else {
Label oc_blk_tail, oc_blk_done;
cmp(reg_reduce_work, oc_block);
jl(oc_blk_tail, T_NEAR);
compute(oc_block);
jmp(oc_blk_done, T_NEAR);
L(oc_blk_tail);
compute(oc_tail);
L(oc_blk_done);
}
} else {
compute(oc_block);
}
}
add(aux_reg_kernel, get_kernel_offset(0, 0, stride_h * kw, 0));
sub(aux_reg_ddst, get_ddst_offset(0, (jcp.dilate_h + 1) * ow, 0));
dec(kj);
cmp(kj, 0);
jg(kh_loop, T_NEAR);
}
L(skip_kh_loop);
if (jcp.ndims == 5) {
sub(aux_reg_dst_d,
get_ddst_offset(0, (jcp.dilate_d + 1) * jcp.oh * ow, 0));
add(aux_reg_ker_d, get_kernel_offset(0, 0, jcp.kw * jcp.kh, 0));
dec(reg_ki);
cmp(reg_ki, 0);
jg(kd_loop, T_NEAR);
L(skip_kd_loop);
pop(oi_iter);
}
if (one_of(jcp.ndims, 3, 4)) {
int ddst_oc_shift = get_ddst_offset(1, 0, 0);
int kernel_oc_shift = get_kernel_offset(1, 0, 0, 0);
add(aux_reg_ddst_oc_loop, ddst_oc_shift);
add(aux_reg_kernel_oc_loop, kernel_oc_shift);
if (oc_tail) sub(reg_reduce_work, jcp.oc_block);
inc(reg_channel);
cmp(reg_channel, reg_channel_work);
jl(oc_loop, T_NEAR);
L(skip_oc_loop);
mov(reg_channel, ptr[param1 + GET_OFF(channel)]);
}
if (oc_tail) pop(reg_long_offt);
auto load_store_dsrc = [=](bool is_tail) {
mov(reg_channel, ptr[param1 + GET_OFF(channel)]);
Label no_update_label;
cmp(reg_channel, 0);
je(no_update_label, T_NEAR);
for (int ii = 0; ii < nb_ic_block; ii++)
for (int jj = 0; jj < ur_w; jj++) {
if (is_tail && ii == nb_ic_block - 1)
load_bytes(Ymm(15), reg_dsrc, get_dsrc_offset(ii, jj),
ic_tail * sizeof(float));
else
vmovups(Ymm(15),
make_safe_addr(reg_dsrc, get_dsrc_offset(ii, jj),
reg_long_offt));
vaddps(Ymm(ur_w * ii + jj), Ymm(ur_w * ii + jj), Ymm(15));
}
L(no_update_label);
for (int ii = 0; ii < nb_ic_block; ii++)
for (int jj = 0; jj < ur_w; jj++) {
if (is_tail && ii == nb_ic_block - 1)
store_bytes(Ymm(ur_w * ii + jj), reg_dsrc,
get_dsrc_offset(ii, jj), ic_tail * sizeof(float));
else
vmovups(make_safe_addr(reg_dsrc, get_dsrc_offset(ii, jj),
reg_long_offt),
Ymm(ur_w * ii + jj));
}
};
if (ic_tail) {
Label load_store_tail, load_store_done;
mov(reg_ci_flag, ptr[param1 + GET_OFF(flags)]);
test(reg_ci_flag, FLAG_IC_LAST);
jne(load_store_tail, T_NEAR);
load_store_dsrc(false);
jmp(load_store_done, T_NEAR);
L(load_store_tail);
load_store_dsrc(true);
L(load_store_done);
} else {
load_store_dsrc(false);
}
}
void jit_avx2_conv_bwd_data_kernel_f32::generate() {
preamble();
mov(reg_dsrc, ptr[this->param1 + GET_OFF(src)]);
mov(reg_ddst, ptr[this->param1 + GET_OFF(dst)]);
mov(reg_kernel, ptr[this->param1 + GET_OFF(filt)]);
mov(reg_kh, ptr[this->param1 + GET_OFF(kh_padding)]);
mov(reg_channel, ptr[param1 + GET_OFF(channel)]);
mov(reg_channel_work, ptr[param1 + GET_OFF(ch_blocks)]);
int ddst_shift = get_ddst_offset(0, filter_w_to_ddst(0, jcp.ur_w), 0);
int dsrc_shift = get_dsrc_offset(0, jcp.ur_w);
const int ext_kw = calculate_extended_filter_size(jcp.kw, jcp.dilate_w);
int l_overflow = nstl::max(0, (ext_kw - 1 - jcp.l_pad) / jcp.stride_w);
int r_overflow = nstl::max(
0, (ext_kw - 1 - nstl::max(0, jcp.r_pad)) / jcp.stride_w);
int r_overflow1 = nstl::max(
0, (ext_kw - 1 - jcp.r_pad - jcp.ur_w_tail) / jcp.stride_w);
int n_oi = jcp.iw / jcp.ur_w;
if (r_overflow1 > 0) n_oi--;
if (jcp.ur_w == jcp.iw) {
compute_loop(jcp.ur_w, l_overflow, r_overflow);
} else if (n_oi == 0) {
compute_loop(jcp.ur_w, l_overflow, r_overflow1);
add(reg_dsrc, dsrc_shift);
add(reg_ddst, ddst_shift);
if (jcp.ur_w_tail != 0) compute_loop(jcp.ur_w_tail, 0, r_overflow);
} else {
xor_(oi_iter, oi_iter);
if (l_overflow > 0) {
compute_loop(jcp.ur_w, l_overflow, 0);
add(reg_dsrc, dsrc_shift);
add(reg_ddst, ddst_shift);
inc(oi_iter);
}
if ((l_overflow <= 0 && n_oi > 0) || (l_overflow > 0 && n_oi > 1)) {
Label ow_loop;
L(ow_loop);
{
compute_loop(jcp.ur_w, 0, 0);
add(reg_dsrc, dsrc_shift);
add(reg_ddst, ddst_shift);
inc(oi_iter);
cmp(oi_iter, n_oi);
jl(ow_loop, T_NEAR);
}
}
if (r_overflow1 > 0) {
compute_loop(jcp.ur_w, 0, r_overflow1);
add(reg_dsrc, dsrc_shift);
add(reg_ddst, ddst_shift);
}
if (jcp.ur_w_tail != 0) compute_loop(jcp.ur_w_tail, 0, r_overflow);
}
this->postamble();
}
status_t jit_avx2_conv_bwd_data_kernel_f32::init_conf(jit_conv_conf_t &jcp,
const convolution_desc_t &cd, const memory_desc_wrapper &diff_src_d,
const memory_desc_wrapper &weights_d,
const memory_desc_wrapper &diff_dst_d) {
if (!mayiuse(avx2)) return status::unimplemented;
jcp.nthr = dnnl_get_max_threads();
const bool with_groups = weights_d.ndims() == diff_src_d.ndims() + 1;
int ndims = diff_src_d.ndims();
jcp.ndims = ndims;
jcp.ngroups = with_groups ? weights_d.dims()[0] : 1;
jcp.mb = diff_src_d.dims()[0];
jcp.oc = diff_dst_d.dims()[1] / jcp.ngroups;
jcp.oc_without_padding = jcp.oc;
jcp.ic = diff_src_d.dims()[1] / jcp.ngroups;
jcp.id = (ndims == 5) ? diff_src_d.dims()[2] : 1;
jcp.ih = (ndims == 3) ? 1 : diff_src_d.dims()[ndims - 2];
jcp.iw = diff_src_d.dims()[ndims - 1];
jcp.od = (ndims == 5) ? diff_dst_d.dims()[2] : 1;
jcp.oh = (ndims == 3) ? 1 : diff_dst_d.dims()[ndims - 2];
jcp.ow = diff_dst_d.dims()[ndims - 1];
jcp.kd = (ndims == 5) ? weights_d.dims()[with_groups + 2] : 1;
jcp.kh = (ndims == 3) ? 1 : weights_d.dims()[with_groups + ndims - 2];
jcp.kw = weights_d.dims()[with_groups + ndims - 1];
jcp.f_pad = (ndims == 5) ? cd.padding[0][0] : 0;
jcp.t_pad = (ndims == 3) ? 0 : cd.padding[0][ndims - 4];
jcp.l_pad = cd.padding[0][ndims - 3];
jcp.stride_d = (ndims == 5) ? cd.strides[0] : 1;
jcp.stride_h = (ndims == 3) ? 1 : cd.strides[ndims - 4];
jcp.stride_w = cd.strides[ndims - 3];
jcp.dilate_d = (ndims == 5) ? cd.dilates[0] : 0;
jcp.dilate_h = (ndims == 3) ? 0 : cd.dilates[ndims - 4];
jcp.dilate_w = cd.dilates[ndims - 3];
if ((jcp.dilate_w != 0 && jcp.stride_w != 1)
|| (jcp.dilate_d != 0 && jcp.stride_d != 1)
|| (jcp.dilate_h != 0 && jcp.stride_h != 1))
return status::unimplemented;
const int simd_w = 8;
/* derivatives */
jcp.idp = jcp.id + 2 * jcp.f_pad;
jcp.ihp = jcp.ih + 2 * jcp.t_pad;
jcp.iwp = jcp.iw + 2 * jcp.l_pad;
jcp.ohp = jcp.oh; /* do we really need */
jcp.owp = jcp.ow; /* padded output ??? */
const auto dat_tag_nxc = pick(ndims - 3, nwc, nhwc, ndhwc);
const auto dat_tag_nCx8c = pick(ndims - 3, nCw8c, nChw8c, nCdhw8c);
auto wei_tag = with_groups
? pick(ndims - 3, gOIw8o8i, gOIhw8o8i, gOIdhw8o8i)
: pick(ndims - 3, OIw8o8i, OIhw8o8i, OIdhw8o8i);
jcp.src_tag = diff_src_d.matches_one_of_tag(dat_tag_nxc, dat_tag_nCx8c);
jcp.dst_tag = diff_dst_d.matches_one_of_tag(dat_tag_nxc, dat_tag_nCx8c);
jcp.wei_tag = weights_d.matches_one_of_tag(wei_tag);
jcp.typesize_in = types::data_type_size(diff_src_d.data_type());
jcp.typesize_out = types::data_type_size(diff_dst_d.data_type());
bool is_data_layout_nxc
= everyone_is(dat_tag_nxc, jcp.src_tag, jcp.dst_tag);
bool ok_to_pad_channels = true && !is_data_layout_nxc && jcp.ngroups == 1;
/* gemm-based convolution performs better in these cases */
if (jcp.ic < simd_w && jcp.kw > 3 && jcp.stride_w > 1)
return status::unimplemented;
if (ok_to_pad_channels) {
jcp.oc = rnd_up(jcp.oc, simd_w);
jcp.ic = rnd_up(jcp.ic, simd_w);
}
jcp.ic_block = (!is_data_layout_nxc && jcp.ic % simd_w) ? 1 : simd_w;
jcp.nb_ic = div_up(jcp.ic, jcp.ic_block);
jcp.ic_tail = is_data_layout_nxc ? jcp.ic % simd_w : 0;
jcp.oc_tail = is_data_layout_nxc ? jcp.oc % simd_w : 0;
jcp.oc_block = simd_w;
jcp.nb_oc = div_up(jcp.oc, jcp.oc_block);
jcp.ur_h = 1; /* no code-unrolling by h so far */
jcp.nb_ic_blocking = 1;
jcp.nb_oc_blocking = 1;
jcp.ur_w = 1;
if (one_of(ndims, 3, 4) && jcp.ow < 40)
jcp.nb_oc_blocking = jcp.ow < 15 ? 4 : 2;
auto required_dat_tag = is_data_layout_nxc ? dat_tag_nxc : dat_tag_nCx8c;
bool args_ok = true && jcp.stride_w == jcp.stride_h && jcp.stride_d == 1
&& IMPLICATION(!is_data_layout_nxc,
jcp.ic % simd_w == 0 && jcp.oc % simd_w == 0)
&& jcp.ic <= diff_src_d.padded_dims()[1]
&& jcp.oc <= diff_dst_d.padded_dims()[1]
&& jcp.dst_tag == required_dat_tag
&& jcp.src_tag == required_dat_tag && jcp.wei_tag == wei_tag;
if (!args_ok) return status::unimplemented;
const int ext_kw = calculate_extended_filter_size(jcp.kw, jcp.dilate_w);
const int ext_kh = calculate_extended_filter_size(jcp.kh, jcp.dilate_h);
const int ext_kd = calculate_extended_filter_size(jcp.kd, jcp.dilate_d);
jcp.r_pad = calculate_end_padding(
jcp.l_pad, jcp.ow, jcp.iw, jcp.stride_w, ext_kw);
jcp.b_pad = calculate_end_padding(
jcp.t_pad, jcp.oh, jcp.ih, jcp.stride_h, ext_kh);
jcp.back_pad = calculate_end_padding(
jcp.f_pad, jcp.od, jcp.id, jcp.stride_d, ext_kd);
bool kernel_outside_src = false || ext_kw <= jcp.l_pad
|| ext_kw <= jcp.r_pad || ext_kh <= jcp.t_pad || ext_kh <= jcp.b_pad
|| ext_kd <= jcp.f_pad || ext_kd <= jcp.back_pad;
if (kernel_outside_src) return status::unimplemented;
int l_overflow = nstl::max(0, (ext_kw - 1 - jcp.l_pad) / jcp.stride_w);
const int max_regs = 15; /* Maximum number of registers available for
result accumulation and delta dst data.
One additional register is reserved for weights
data. */
/* Find the best blocking with maximum number of fma instructions
per ur_w * nb_ic_blocking compute loops. Number of required registers
is num_regs = ur_w * nb_ic_blocking + ur_w / stride_w <= max_regs.
ur_w must be divisible by stride_w */
if (jcp.stride_w + 1 > max_regs) /* Minimal possible registers
distribution exceeds max_regs */
return status::unimplemented;
int best_nfmas = 0;
for (int b = 1; b <= 4; b++) {
if (jcp.nb_ic % b != 0) continue;
for (int u = jcp.stride_w; u * b + u / jcp.stride_w <= max_regs
&& u < jcp.iw + jcp.stride_w;
u += jcp.stride_w) {
int ur_w = nstl::min(u, jcp.iw);
/* maximum 1 step with l_overflow so far */
if (l_overflow * jcp.stride_w > ur_w && ur_w != jcp.iw) continue;
int nfmas = div_up(ur_w, jcp.stride_w) * b;
if (nfmas > best_nfmas
|| (nfmas == best_nfmas && jcp.ur_w < ur_w)) {
jcp.ur_w = ur_w;
jcp.nb_ic_blocking = b;
best_nfmas = nfmas;
}
}
}
if (best_nfmas == 0) /* can't find appropriate blocking */
return status::unimplemented;
jcp.ur_w_tail = jcp.iw % jcp.ur_w;
int r_overflow_no_tail = nstl::max(
0, (ext_kw - 1 - jcp.r_pad - jcp.ur_w_tail) / jcp.stride_w);
bool tails_not_ok = false
/* maximum 1 ur_w block with r_overflow so far */
|| r_overflow_no_tail * jcp.stride_w > jcp.ur_w
/* ur_w must be a multiple of stride */
|| ((jcp.iw > jcp.ur_w) && (jcp.ur_w % jcp.stride_w != 0))
/* r_pad must not extend beyond ur_w_tail */
|| ((jcp.iw > jcp.ur_w) && (jcp.r_pad + jcp.ur_w_tail < 0));
if (tails_not_ok) return status::unimplemented;
/* adjust the thread decomposition
* to improve the perf for small problem size
* the threshold L1_cache_size is empirical
* simply set the thread to 4 for now
* TODO: Add get_thr_eff func to get optimal thread number */
size_t wei_size = (size_t)sizeof(float) * jcp.ic * jcp.oc * jcp.kh * jcp.kw
* jcp.kd;
size_t inp_size = (size_t)jcp.typesize_in * jcp.mb * jcp.ic * jcp.ih
* jcp.iw * jcp.id;
size_t out_size = (size_t)jcp.typesize_out * jcp.mb * jcp.oc * jcp.oh
* jcp.ow * jcp.od;
size_t total_size = jcp.ngroups * (wei_size + inp_size + out_size);
const unsigned int L1_cache_size = platform::get_per_core_cache_size(1);
if (jcp.ngroups < jcp.nthr && total_size < L1_cache_size) {
jcp.nthr = nstl::min(jcp.nthr, 4);
}
return status::success;
}
void jit_avx2_conv_bwd_data_kernel_f32::init_scratchpad(
memory_tracking::registrar_t &scratchpad, const jit_conv_conf_t &jcp) {
UNUSED(scratchpad);
UNUSED(jcp);
}
void jit_avx2_conv_bwd_weights_kernel_f32::generate() {
this->preamble();
mov(reg_input, ptr[this->param1 + GET_OFF(src)]);
mov(reg_output, ptr[this->param1 + GET_OFF(dst)]);
mov(reg_kernel, ptr[this->param1 + GET_OFF(filt)]);
compute_oh_loop_common();
this->postamble();
}
status_t jit_avx2_conv_bwd_weights_kernel_f32::init_conf(jit_conv_conf_t &jcp,
const convolution_desc_t &cd, const memory_desc_wrapper &src_d,
const memory_desc_wrapper &diff_weights_d,
const memory_desc_wrapper &diff_dst_d) {
if (!mayiuse(avx2)) return status::unimplemented;
const bool with_groups = diff_weights_d.ndims() == src_d.ndims() + 1;
int ndims = src_d.ndims();
jcp.ndims = ndims;
jcp.ngroups = with_groups ? diff_weights_d.dims()[0] : 1;
jcp.mb = src_d.dims()[0];
jcp.oc = diff_dst_d.dims()[1] / jcp.ngroups;
jcp.oc_without_padding = jcp.oc;
jcp.ic = src_d.dims()[1] / jcp.ngroups;
jcp.ic_without_padding = jcp.ic;
jcp.id = (ndims == 5) ? src_d.dims()[2] : 1;
jcp.ih = (ndims == 3) ? 1 : src_d.dims()[ndims - 2];
jcp.iw = src_d.dims()[ndims - 1];
jcp.od = (ndims == 5) ? diff_dst_d.dims()[2] : 1;
jcp.oh = (ndims == 3) ? 1 : diff_dst_d.dims()[ndims - 2];
jcp.ow = diff_dst_d.dims()[ndims - 1];
jcp.kd = (ndims == 5) ? diff_weights_d.dims()[with_groups + 2] : 1;
jcp.kh = (ndims == 3) ? 1 : diff_weights_d.dims()[with_groups + ndims - 2];
jcp.kw = diff_weights_d.dims()[with_groups + ndims - 1];
jcp.f_pad = (ndims == 5) ? cd.padding[0][0] : 0;
jcp.t_pad = (ndims == 3) ? 0 : cd.padding[0][ndims - 4];
jcp.l_pad = cd.padding[0][ndims - 3];
jcp.stride_d = (ndims == 5) ? cd.strides[0] : 1;
jcp.stride_h = (ndims == 3) ? 1 : cd.strides[ndims - 4];
jcp.stride_w = cd.strides[ndims - 3];
jcp.dilate_d = (ndims == 5) ? cd.dilates[0] : 0;
jcp.dilate_h = (ndims == 3) ? 0 : cd.dilates[ndims - 4];
jcp.dilate_w = cd.dilates[ndims - 3];
const auto dat_tag_nxc = pick(ndims - 3, nwc, nhwc, ndhwc);
const auto dat_tag_ncx = pick(ndims - 3, ncw, nchw, ncdhw);
const auto dat_tag_nCx8c = pick(ndims - 3, nCw8c, nChw8c, nCdhw8c);
auto wei_tag_OIxio = with_groups
? pick(ndims - 3, gOIw8i8o, gOIhw8i8o, gOIdhw8i8o)
: pick(ndims - 3, OIw8i8o, OIhw8i8o, OIdhw8i8o);
auto wei_tag_Oxio = with_groups ? pick(ndims - 3, gOwi8o, gOhwi8o, gOdhwi8o)
: pick(ndims - 3, Owi8o, Ohwi8o, Odhwi8o);
jcp.src_tag
= src_d.matches_one_of_tag(dat_tag_ncx, dat_tag_nxc, dat_tag_nCx8c);
jcp.wei_tag
= diff_weights_d.matches_one_of_tag(wei_tag_OIxio, wei_tag_Oxio);
jcp.dst_tag = diff_dst_d.matches_one_of_tag(dat_tag_nxc, dat_tag_nCx8c);
bool is_data_layout_nxc
= everyone_is(dat_tag_nxc, jcp.src_tag, jcp.dst_tag);
jcp.with_bias = cd.diff_bias_desc.format_kind != format_kind::undef;
const bool flat = jcp.ic == 3;
const bool mimo = !flat;
const int simd_w = 8;
int ext_kw = calculate_extended_filter_size(jcp.kw, jcp.dilate_w);
int ext_kh = calculate_extended_filter_size(jcp.kh, jcp.dilate_h);
int ext_kd = calculate_extended_filter_size(jcp.kd, jcp.dilate_d);
jcp.r_pad = nstl::max(0,
calculate_end_padding(
jcp.l_pad, jcp.ow, jcp.iw, jcp.stride_w, ext_kw));
jcp.b_pad = nstl::max(0,
calculate_end_padding(
jcp.t_pad, jcp.oh, jcp.ih, jcp.stride_h, ext_kh));
jcp.back_pad = nstl::max(0,
calculate_end_padding(
jcp.f_pad, jcp.od, jcp.id, jcp.stride_d, ext_kd));
const int max_h_pad = ext_kh;
const int max_w_pad = ext_kw;
const bool boundaries_ok = true && jcp.t_pad < max_h_pad
&& jcp.b_pad < max_h_pad && jcp.l_pad < max_w_pad
&& jcp.r_pad < max_w_pad && jcp.f_pad == 0 && jcp.back_pad == 0;
if (!boundaries_ok) return status::unimplemented;
bool ok_to_pad_channels = true && !is_data_layout_nxc && jcp.ngroups == 1;
if (ok_to_pad_channels) {
jcp.oc = rnd_up(jcp.oc, simd_w);
if (mimo) jcp.ic = rnd_up(jcp.ic, simd_w);
}
jcp.ic_tail = is_data_layout_nxc ? jcp.ic % simd_w : 0;
jcp.oc_tail = is_data_layout_nxc ? jcp.oc % simd_w : 0;
bool args_ok = true
&& IMPLICATION(flat,
jcp.wei_tag == wei_tag_Oxio
&& ((jcp.src_tag == dat_tag_ncx
&& jcp.dst_tag == dat_tag_nCx8c)
|| (jcp.src_tag == dat_tag_nxc
&& jcp.dst_tag == dat_tag_nxc)))
&& IMPLICATION(mimo,
jcp.wei_tag == wei_tag_OIxio
&& ((jcp.src_tag == dat_tag_nCx8c
&& jcp.dst_tag == dat_tag_nCx8c)
|| (jcp.src_tag == dat_tag_nxc
&& jcp.dst_tag == dat_tag_nxc)))
&& IMPLICATION(mimo && !is_data_layout_nxc, jcp.ic % simd_w == 0)
&& IMPLICATION(!is_data_layout_nxc, jcp.oc % simd_w == 0)
&& jcp.kw < 14 && jcp.kh <= jcp.t_pad + jcp.ih /* [bwd_w:r1] */
&& jcp.kh <= jcp.ih /* [bwd_w:r2] */
&& jcp.kd <= jcp.f_pad + jcp.id && jcp.kd <= jcp.id
&& jcp.t_pad < jcp.kh /* XXX: must fix the kernel! */
&& jcp.dilate_d == 0 && jcp.dilate_h == 0 && jcp.dilate_w == 0
&& jcp.ic <= src_d.padded_dims()[1]
&& jcp.oc <= diff_dst_d.padded_dims()[1];
if (!args_ok) return status::unimplemented;
jcp.ic_block = flat ? jcp.ic : simd_w;
jcp.nb_ic = div_up(jcp.ic, jcp.ic_block);
jcp.oc_block = simd_w;
jcp.nb_oc = div_up(jcp.oc, jcp.oc_block);
jcp.nb_ic_blocking = jcp.nb_oc_blocking = 1;
return status::success;
}
void jit_avx2_conv_bwd_weights_kernel_f32::init_scratchpad(
memory_tracking::registrar_t &scratchpad, const jit_conv_conf_t &jcp) {
if (jcp.with_bias && (jcp.oc_without_padding % jcp.oc_block != 0)) {
const size_t nelems_padded_bias
= jcp.ngroups * rnd_up(jcp.oc, jcp.oc_block);
scratchpad.book<float>(key_conv_padded_bias, nelems_padded_bias);
}
}
inline void jit_avx2_conv_bwd_weights_kernel_f32::od_step_comeback_pointers() {
Label kd_comeback_loop;
mov(kj, jcp.kd); //FIXME (Anton): this works only if f_pad = back_pad = 0
L(kd_comeback_loop);
{
sub(aux_reg_input, get_input_offset(0, jcp.iw * jcp.ih));
sub(aux_reg_kernel, get_kernel_offset(jcp.kw * jcp.kh, 0));
dec(kj);
cmp(kj, 0);
jg(kd_comeback_loop, T_NEAR);
}
}
inline void jit_avx2_conv_bwd_weights_kernel_f32::oh_step_comeback_pointers() {
mov(kj, reg_kh);
Label kh_comeback_loop;
L(kh_comeback_loop);
{
sub(reg_input, get_input_offset(0, jcp.iw));
sub(reg_kernel, get_kernel_offset(jcp.kw, 0));
dec(kj);
cmp(kj, 0);
jg(kh_comeback_loop, T_NEAR);
}
}
inline void jit_avx2_conv_bwd_weights_kernel_f32::compute_ic_block_step(
int ur_w, int pad_l, int pad_r, int ic_block_step, int input_offset,
int kernel_offset, int output_offset) {
if (ic_block_step <= 0) return;
const int kw = jcp.kw;
const int oc_tail = jcp.oc_tail;
if (oc_tail) {
push(reg_kh);
mov(reg_ci_flag, ptr[param1 + GET_OFF(flags)]);
}
auto load_compute_store = [=](bool is_tail) {
for (int i_kw = 0; i_kw < kw; i_kw++)
for (int i_ic = 0; i_ic < ic_block_step; i_ic++) {
size_t off = get_kernel_offset(i_kw, i_ic) + kernel_offset;
if (is_tail)
load_bytes(Ymm(i_kw * ic_block_step + i_ic), reg_kernel,
off, oc_tail * sizeof(float));
else
vmovups(Ymm(i_kw * ic_block_step + i_ic),
yword[reg_kernel + off]);
}
for (int i_ur = 0; i_ur < ur_w; i_ur++) {
if (is_tail)
load_bytes(Ymm(kw * ic_block_step + 0), reg_output,
get_output_offset(0, i_ur) + output_offset,
oc_tail * sizeof(float));
else
vmovups(Ymm(kw * ic_block_step + 0),
yword[reg_output + get_output_offset(0, i_ur)
+ output_offset]);
for (int i_kw = 0; i_kw < kw; i_kw++) {
int i_iw = i_ur * jcp.stride_w + i_kw;
if (i_iw - pad_l < 0
|| i_iw > (ur_w - 1) * jcp.stride_w + kw - 1 - pad_r)
continue;
for (int i_ic = 0; i_ic < ic_block_step; i_ic++) {
size_t i_off = get_input_offset(i_ic, i_iw - pad_l);
vbroadcastss(Ymm(kw * ic_block_step + 1),
make_safe_addr(reg_input, i_off, reg_long_offt));
vfmadd231ps(Ymm(i_kw * ic_block_step + i_ic),
Ymm(kw * ic_block_step + 0),
Ymm(kw * ic_block_step + 1));
}
}
}
for (int i_kw = 0; i_kw < kw; i_kw++)
for (int i_ic = 0; i_ic < ic_block_step; i_ic++) {
size_t off = get_kernel_offset(i_kw, i_ic) + kernel_offset;
if (is_tail)
store_bytes(Ymm(i_kw * ic_block_step + i_ic), reg_kernel,
off, oc_tail * sizeof(float));
else
vmovups(yword[reg_kernel + off],
Ymm(i_kw * ic_block_step + i_ic));
}
};
if (oc_tail) {
Label load_tail, load_done;
test(reg_ci_flag, FLAG_OC_LAST);
jne(load_tail, T_NEAR);
load_compute_store(false);
jmp(load_done, T_NEAR);
L(load_tail);
load_compute_store(true);
L(load_done);
} else {
load_compute_store(false);
}
if (oc_tail) pop(reg_kh);
}
inline void jit_avx2_conv_bwd_weights_kernel_f32::compute_oh_step_disp() {
int ic_block_step;
if (one_of(jcp.src_tag, ncw, nchw, ncdhw)) {
ic_block_step = jcp.kw >= 5 ? 1 : jcp.ic_block;
} else if (one_of(jcp.src_tag, nwc, nhwc, ndhwc)) {
ic_block_step = jcp.kw > 7 ? 1 : jcp.kw > 3 ? 2 : jcp.kw > 1 ? 4 : 8;
if (jcp.ic_block % ic_block_step != 0) {
ic_block_step = jcp.ic_block < ic_block_step ? jcp.ic_block : 1;
}
if (jcp.ic < ic_block_step) ic_block_step = jcp.ic;
} else {
ic_block_step = jcp.kw > 7 ? 1 : jcp.kw > 3 ? 2 : jcp.kw > 1 ? 4 : 8;
}
const int max_ur_w = jcp.ow > 56 ? 14 : 28;
if (jcp.ow <= max_ur_w || one_of(jcp.src_tag, nwc, nhwc, ndhwc))
compute_oh_step_unroll_ow(ic_block_step, max_ur_w);
else
compute_oh_step_common(ic_block_step, max_ur_w);
if (jcp.ndims == 5) {
od_step_comeback_pointers();
mov(reg_input, aux_reg_input);
mov(reg_kernel, aux_reg_kernel);
} else {
oh_step_comeback_pointers();
}
}
inline void jit_avx2_conv_bwd_weights_kernel_f32::compute_oh_step_unroll_ow(
int ic_block_step, int max_ur_w) {
UNUSED(max_ur_w);
const int r_pad = jcp.r_pad;
const int ic_tail = jcp.ic_tail;
const int ic_block = jcp.ic_block;
const int ic_block_step_tail = jcp.ic % ic_block_step;
const size_t inp_icblk_stride = get_input_offset(ic_block_step, 0);
if (ic_tail) {
push(reg_ih_count);
mov(reg_channel, ptr[param1 + GET_OFF(channel)]);
}
Label kd_loop;
if (jcp.ndims == 5) {
mov(aux_reg_input, reg_input);
mov(aux_reg_kernel, reg_kernel);
mov(ki, jcp.kd);
L(kd_loop);
mov(reg_input, aux_reg_input);
mov(reg_kernel, aux_reg_kernel);
}
mov(kj, reg_kh);
Label kh_loop, kh_loop_ic_tail, kh_loop_done;
if (ic_tail) {
cmp(reg_channel, ic_block);
jl(kh_loop_ic_tail, T_NEAR);
}
L(kh_loop);
{
xor_(b_ic, b_ic);
Label ic_block_loop;
L(ic_block_loop);
{
compute_ic_block_step(
jcp.ow, jcp.l_pad, r_pad, ic_block_step, 0, 0, 0);
safe_add(reg_input, inp_icblk_stride, reg_long_offt);
add(reg_kernel, get_kernel_offset(0, ic_block_step));
add(b_ic, ic_block_step);
cmp(b_ic, ic_block);
jl(ic_block_loop, T_NEAR);
}
add(reg_input,
get_input_offset(0, jcp.iw) - get_input_offset(ic_block, 0));
add(reg_kernel, get_kernel_offset((jcp.kw - 1), 0));
dec(kj);
cmp(kj, 0);
jg(kh_loop, T_NEAR);
}
jmp(kh_loop_done, T_NEAR);
L(kh_loop_ic_tail);
{
Label ic_block_loop, ic_block_loop_done;
cmp(reg_channel, ic_block_step);
jl(ic_block_loop_done, T_NEAR);
mov(b_ic, ic_tail);
L(ic_block_loop);
{
compute_ic_block_step(
jcp.ow, jcp.l_pad, r_pad, ic_block_step, 0, 0, 0);
safe_add(reg_input, inp_icblk_stride, reg_long_offt);
add(reg_kernel, get_kernel_offset(0, ic_block_step));
sub(b_ic, ic_block_step);
cmp(b_ic, ic_block_step);
jge(ic_block_loop, T_NEAR);
}
L(ic_block_loop_done);
if (ic_block_step_tail) {
compute_ic_block_step(
jcp.ow, jcp.l_pad, r_pad, ic_block_step_tail, 0, 0, 0);
add(reg_input, get_input_offset(ic_block_step_tail, 0));
add(reg_kernel, get_kernel_offset(0, ic_block_step_tail));
}
add(reg_input,
get_input_offset(0, jcp.iw) - get_input_offset(ic_tail, 0));
add(reg_kernel,
get_kernel_offset(0, ic_block - ic_tail)
+ get_kernel_offset((jcp.kw - 1), 0));
dec(kj);
cmp(kj, 0);
jg(kh_loop_ic_tail, T_NEAR);
}
L(kh_loop_done);
if (jcp.ndims == 5) {
add(aux_reg_input, get_input_offset(0, jcp.ih * jcp.iw));
add(aux_reg_kernel, get_kernel_offset(jcp.kh * jcp.kw, 0));
dec(ki);
cmp(ki, 0);
jg(kd_loop, T_NEAR);
}
if (ic_tail) pop(reg_ih_count);
}
inline void jit_avx2_conv_bwd_weights_kernel_f32::compute_oh_step_common(
int ic_block_step, int max_ur_w) {
// TODO: suppport channel tails for nxc format
const int ic_block = jcp.ic_block;
const int stride_w = jcp.stride_w;
Label kd_loop;
const int r_pad = jcp.r_pad;
int ur_w = nstl::min(jcp.ow, max_ur_w);
int ur_w_trips = jcp.ow / ur_w;
int ur_w_tail = jcp.ow % ur_w;
if ((ur_w_tail == 0 && r_pad != 0) || r_pad >= ur_w_tail) {
if (ur_w_trips > 1) {
ur_w_tail += ur_w;
ur_w_trips--;
} else {
ur_w_tail += (ur_w - ur_w / 2);
ur_w = ur_w / 2;
}
}
int input_comeback
= get_input_offset(0, ur_w_trips * ur_w * stride_w - jcp.l_pad);
int output_comeback = get_output_offset(0, ur_w_trips * ur_w);
if (jcp.ndims == 5) {
mov(aux_reg_input, reg_input);
mov(aux_reg_kernel, reg_kernel);
mov(ki, jcp.kd);
L(kd_loop);
mov(reg_input, aux_reg_input);
mov(reg_kernel, aux_reg_kernel);
}
mov(kj, reg_kh);
Label kh_loop;
L(kh_loop);
{
xor_(b_ic, b_ic);
Label ic_block_loop;
L(ic_block_loop);
{
if (jcp.l_pad != 0) {
ur_w_trips--;
compute_ic_block_step(
ur_w, jcp.l_pad, 0, ic_block_step, 0, 0, 0);
add(reg_input,
get_input_offset(0, ur_w * stride_w - jcp.l_pad));
add(reg_output, get_output_offset(0, ur_w));
}
if (ur_w_trips > 0) {
xor_(reg_ur_w_trips, reg_ur_w_trips);
Label ow_block_loop;
L(ow_block_loop);
{
compute_ic_block_step(ur_w, 0, 0, ic_block_step, 0, 0, 0);
add(reg_output, get_output_offset(0, ur_w));
add(reg_input, get_input_offset(0, ur_w * stride_w));
inc(reg_ur_w_trips);
cmp(reg_ur_w_trips, ur_w_trips);
jl(ow_block_loop, T_NEAR);
}
}
if (ur_w_tail > 0)
compute_ic_block_step(
ur_w_tail, 0, r_pad, ic_block_step, 0, 0, 0);
sub(reg_input, input_comeback);
sub(reg_output, output_comeback);
size_t inp_icblk_stride = get_input_offset(ic_block_step, 0);
safe_add(reg_input, inp_icblk_stride, reg_long_offt);
add(reg_kernel, get_kernel_offset(0, ic_block_step));
add(b_ic, ic_block_step);
cmp(b_ic, jcp.ic_block);
jl(ic_block_loop, T_NEAR);
}
add(reg_input,
get_input_offset(0, jcp.iw) - get_input_offset(ic_block, 0));
add(reg_kernel, get_kernel_offset((jcp.kw - 1), 0));
dec(kj);
cmp(kj, 0);
jg(kh_loop, T_NEAR);
}
if (jcp.ndims == 5) {
add(aux_reg_input, get_input_offset(0, jcp.ih * jcp.iw));
add(aux_reg_kernel, get_kernel_offset(jcp.kh * jcp.kw, 0));
dec(ki);
cmp(ki, 0);
jg(kd_loop, T_NEAR);
}
}
inline void jit_avx2_conv_bwd_weights_kernel_f32::compute_oh_loop_common() {
const int t_pad = jcp.t_pad;
const int stride_h = jcp.stride_h;
int b_pad = jcp.b_pad;
Label oh_tpad_loop, oh_loop, oh_loop_end;
mov(reg_kh, jcp.kh);
xor_(reg_ih_count, reg_ih_count);
xor_(reg_oj, reg_oj);
if (t_pad > 0) {
assert(jcp.kh <= t_pad + jcp.ih); /* [bwd_w:r1] */
mov(reg_kh, jcp.kh <= t_pad + jcp.ih ? jcp.kh - t_pad : jcp.ih);
add(reg_kernel, get_kernel_offset(t_pad * jcp.kw, 0));
L(oh_tpad_loop);
{
compute_oh_step_disp();
add(reg_output, get_output_offset(0, jcp.ow));
sub(reg_kernel, get_kernel_offset(stride_h * jcp.kw, 0));
inc(reg_oj);
add(reg_ih_count, stride_h);
add(reg_kh, stride_h);
/* the overlap between input and kernel may not reach kernel size.
* so far we do not support that (until we put constant here) */
const int final_inp_ker_overlap = jcp.kh; /* [bwd_w:r2] */
cmp(reg_kh, final_inp_ker_overlap);
jl(oh_tpad_loop, T_NEAR);
}
if (t_pad % stride_h != 0) {
int inp_corr = stride_h - t_pad % stride_h;
add(reg_kernel, get_kernel_offset(inp_corr * jcp.kw, 0));
add(reg_input, get_input_offset(0, inp_corr * jcp.iw));
}
}
cmp(reg_ih_count, jcp.ih + t_pad - jcp.kh + 1);
jge(oh_loop_end, T_NEAR);
cmp(reg_oj, jcp.oh);
jge(oh_loop, T_NEAR);
mov(reg_kh, jcp.kh);
L(oh_loop);
{
compute_oh_step_disp();
add(reg_input, get_input_offset(0, stride_h * jcp.iw));
add(reg_output, get_output_offset(0, jcp.ow));
inc(reg_oj);
add(reg_ih_count, stride_h);
cmp(reg_ih_count, jcp.ih + t_pad - jcp.kh + 1);
jge(oh_loop_end, T_NEAR);
cmp(reg_oj, jcp.oh);
jl(oh_loop, T_NEAR);
}
L(oh_loop_end);
if (b_pad > 0) {
Label oh_bpad_loop, oh_bpad_loop_end;
cmp(reg_oj, jcp.oh);
jge(oh_bpad_loop_end, T_NEAR);
mov(reg_kh, jcp.ih + t_pad);
sub(reg_kh, reg_ih_count);
L(oh_bpad_loop);
{
compute_oh_step_disp();
add(reg_input, get_input_offset(0, stride_h * jcp.iw));
add(reg_output, get_output_offset(0, jcp.ow));
sub(reg_kh, stride_h);
cmp(reg_kh, 0);
jle(oh_bpad_loop_end, T_NEAR);
inc(reg_oj);
cmp(reg_oj, jcp.oh);
jl(oh_bpad_loop, T_NEAR);
}
L(oh_bpad_loop_end);
}
}
} // namespace x64
} // namespace cpu
} // namespace impl
} // namespace dnnl
// vim: et ts=4 sw=4 cindent cino+=l0,\:4,N-s
oneDNN的功效
- 单线程
| 输入 | oneDNN | PaddleLite |
|---|---|---|
| 1x3x224x224,32核,s2,p1 | 0.16 ms |
oneDNN/src/cpu/x64/jit_generator.hpp
#ifdef _WIN32
static const Xbyak::Reg64 abi_param1(Xbyak::Operand::RCX),
abi_param2(Xbyak::Operand::RDX), abi_param3(Xbyak::Operand::R8),
abi_param4(Xbyak::Operand::R9), abi_not_param1(Xbyak::Operand::RDI);
#else
static const Xbyak::Reg64 abi_param1(Xbyak::Operand::RDI),
abi_param2(Xbyak::Operand::RSI), abi_param3(Xbyak::Operand::RDX),
abi_param4(Xbyak::Operand::RCX), abi_param5(Xbyak::Operand::R8),
abi_param6(Xbyak::Operand::R9), abi_not_param1(Xbyak::Operand::RCX);
#endif
#endif
- 上面定义了参数。第一个参数是linux 下面就是RDI和RSI分别是第1个和第二个参数。
oneDNN源码编译和卷积demo
oneDNN Documentation
上面这个文档基本就是一本书了,讲解了好多东西,分成好多章节
- oneDNN不是框架,识别不了模型文件,也没有这样的接口
- 只能自己一个一个primitive去搭建,primitive类似于kernel这样的概念
源码编译
- 进入huipu,我选择在docker玩它
git clone https://github.com/oneapi-src/oneDNN.git
cd oneDNN
mkdir -p build
cd build
cmake .. -DCMAKE_BUILD_TYPE=Debug
make -j4
上面编译好了,下面继续在build目录里执行cmake --build . --target install,
然后库就安装好了。
默认头文件是安装在/usr/local/include,库安装在/usr/local/lib
上面多详细过程可参考oneDNN Documentation的Building and Linking这一章节
relu demo
- 官方给了一个好的例子
- 下面这个cpp文件名字为
getting_started.cpp
- 下面这个cpp文件名字为
- 但是它包含了一个
#include "../examples/example_utils.hpp"- 这个头文件不在
usr/local/include里面 - 他在源码里面,记得填写正确的
include路径
- 这个头文件不在
- 下面这个文件告诉了我们如何
Wrapping data into a oneDNN memory objectmemory object是一个重要概念 ,对应于dnnl::memory类型,类似于paddlelite中的tensor- 想创建一个
dnnl::memory,必须先创建一个Memory descriptor,也就是dnnl::memory::desc
#include <cmath>
#include <numeric>
#include <stdexcept>
#include <vector>
#include <iostream>
#include "oneapi/dnnl/dnnl.hpp"
#include "oneapi/dnnl/dnnl_debug.h"
#include "../examples/example_utils.hpp"
using namespace dnnl;
using namespace std;
// [Prologue]
// [Prologue]
void getting_started_tutorial(engine::kind engine_kind) {
// [Initialize engine]
engine eng(engine_kind, 0);
// [Initialize engine]
// [Initialize stream]
stream engine_stream(eng);
// [Initialize stream]
// [Create user's data]
const int N = 1, H = 13, W = 13, C = 3;
// Compute physical strides for each dimension
const int stride_N = H * W * C;
const int stride_H = W * C;
const int stride_W = C;
const int stride_C = 1;
// An auxiliary function that maps logical index to the physical offset
auto offset = [=](int n, int h, int w, int c) {
return n * stride_N + h * stride_H + w * stride_W + c * stride_C;
};
// The image size
const int image_size = N * H * W * C;
// Allocate a buffer for the image
std::vector<float> image(image_size);
// Initialize the image with some values
for (int n = 0; n < N; ++n)
for (int h = 0; h < H; ++h)
for (int w = 0; w < W; ++w)
for (int c = 0; c < C; ++c) {
int off = offset(
n, h, w, c); // Get the physical offset of a pixel
image[off] = -std::cos(off / 10.f);
}
// [Create user's data]
// [Init src_md]
auto src_md = memory::desc(
{N, C, H, W}, // logical dims, the order is defined by a primitive
memory::data_type::f32, // tensor's data type
memory::format_tag::nhwc // memory format, NHWC in this case
);
// [Init src_md]
// [Init alt_src_md]
auto alt_src_md = memory::desc(
{N, C, H, W}, // logical dims, the order is defined by a primitive
memory::data_type::f32, // tensor's data type
{stride_N, stride_C, stride_H, stride_W} // the strides
);
// Sanity check: the memory descriptors should be the same
if (src_md != alt_src_md)
throw std::logic_error("Memory descriptor initialization mismatch.");
// [Init alt_src_md]
// [Create memory objects]
// src_mem contains a copy of image after write_to_dnnl_memory function
auto src_mem = memory(src_md, eng);
write_to_dnnl_memory(image.data(), src_mem);
// For dst_mem the library allocates buffer
auto dst_mem = memory(src_md, eng);
// [Create memory objects]
// [Create a ReLU primitive]
// ReLU op descriptor (no engine- or implementation-specific information)
auto relu_d = eltwise_forward::desc(
prop_kind::forward_inference, algorithm::eltwise_relu,
src_md, // the memory descriptor for an operation to work on
0.f, // alpha parameter means negative slope in case of ReLU
0.f // beta parameter is ignored in case of ReLU
);
// ReLU primitive descriptor, which corresponds to a particular
// implementation in the library
auto relu_pd
= eltwise_forward::primitive_desc(relu_d, // an operation descriptor
eng // an engine the primitive will be created for
);
// ReLU primitive
auto relu = eltwise_forward(relu_pd); // !!! this can take quite some time
// [Create a ReLU primitive]
// [Execute ReLU primitive]
// Execute ReLU (out-of-place)
relu.execute(engine_stream, // The execution stream
{
// A map with all inputs and outputs
{DNNL_ARG_SRC, src_mem}, // Source tag and memory obj
{DNNL_ARG_DST, dst_mem}, // Destination tag and memory obj
});
// Wait the stream to complete the execution
engine_stream.wait();
// [Execute ReLU primitive]
// [Execute ReLU primitive in-place]
// Execute ReLU (in-place)
// relu.execute(engine_stream, {
// {DNNL_ARG_SRC, src_mem},
// {DNNL_ARG_DST, src_mem},
// });
// [Execute ReLU primitive in-place]
// [Check the results]
// Obtain a buffer for the `dst_mem` and cast it to `float *`.
// This is safe since we created `dst_mem` as f32 tensor with known
// memory format.
std::vector<float> relu_image(image_size);
read_from_dnnl_memory(relu_image.data(), dst_mem);
/*
// Check the results
for (int n = 0; n < N; ++n)
for (int h = 0; h < H; ++h)
for (int w = 0; w < W; ++w)
for (int c = 0; c < C; ++c) {
int off = offset(
n, h, w, c); // get the physical offset of a pixel
float expected = image[off] < 0
? 0.f
: image[off]; // expected value
if (relu_image[off] != expected) {
std::cout << "At index(" << n << ", " << c << ", " << h
<< ", " << w << ") expect " << expected
<< " but got " << relu_image[off]
<< std::endl;
throw std::logic_error("Accuracy check failed.");
}
}
// [Check the results]
*/
}
// [Main]
int main(int argc, char **argv) {
int exit_code = 0;
engine::kind engine_kind = parse_engine_kind(argc, argv);
try {
getting_started_tutorial(engine_kind);
} catch (dnnl::error &e) {
std::cout << "oneDNN error caught: " << std::endl
<< "\tStatus: " << dnnl_status2str(e.status) << std::endl
<< "\tMessage: " << e.what() << std::endl;
exit_code = 1;
} catch (std::string &e) {
std::cout << "Error in the example: " << e << "." << std::endl;
exit_code = 2;
}
std::cout << "Example " << (exit_code ? "failed" : "passed") << " on "
<< engine_kind2str_upper(engine_kind) << "." << std::endl;
return exit_code;
}
// [Main]
- 执行
g++ getting_started.cpp -std=c++11 -L /usr/local/lib -ldnnl export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH- 然后就可以执行生成的可执行文件了!
- 关于这个demo的详细解释请阅读Getting started
卷积 demo
- 文档中给了一个CNN f32 inference example
- 链接里面搭建了一个AlexNet网络。
- 下面是一个很小的demo,只干了一件事,那就是卷积+bias
- 下面大致讲解一下他的每一步骤的目的。
#include <assert.h>
#include <chrono>
#include <vector>
#include <unordered_map>
#include "oneapi/dnnl/dnnl.hpp"
#include "../examples/example_utils.hpp"
using namespace dnnl;
- 上面是一些必要的头文件和空间声明
void simple_net(engine::kind engine_kind, int times = 100) {
using tag = memory::format_tag;
using dt = memory::data_type;
//[Initialize engine and stream]
engine eng(engine_kind, 0);
stream s(eng);
//[Initialize engine and stream]
- 上面声明了一个函数simple_net,这个函数里面我搭建了一个网络,这个网络只有卷积+bias
- 第一个参数是
engine::kind,一般都是CPU,一般都用parse_engine_kind(argc, argv);传入即可。 engine eng(engine_kind, 0);定义了一个engine,0表示第0个CPU- 然后定义了一个stream,oneDNN中的primitive执行必须依赖一个
stream,通过不断将网络中的每个primitive放入stream中执行,就达到了执行整个网络的目的了。
//[Create network]
std::vector<primitive> net;
std::vector<std::unordered_map<int, memory>> net_args;
//[Create network]
- 上面就声明了一个网络,网络由
primitive组成 - 网络中的每个
primitive具有很多参数,每个参数都是memory。也就是dnnl::memory类型- 因此每个
primitive的参数都由std::unordered_map<int, memory表示。
- 因此每个
const memory::dim batch = 1;
// {batch, 3, 224, 224} (x) {32, 3, 3, 3} -> {batch, 32, 112, 112}
// strides: {2, 2}
memory::dims conv1_src_tz = {batch, 3, 224, 224};
memory::dims conv1_weights_tz = {32, 3, 3, 3};
memory::dims conv1_bias_tz = {32};
memory::dims conv1_dst_tz = {batch, 32, 112, 112};
memory::dims conv1_strides = {2, 2};
memory::dims conv1_padding = {1, 1};
memory::dim其实就是个int64而已memory::dims其实就是个int64的vector而已
//[Allocate buffers]
std::vector<float> user_src(batch * 3 * 224 * 224);
std::vector<float> conv1_weights(product(conv1_weights_tz));
std::vector<float> conv1_bias(product(conv1_bias_tz));
//[Allocate buffers]
- 上面就是分配点用户空间来放置用户的输入。
//[Create user memory]
auto user_src_memory = memory({{conv1_src_tz}, dt::f32, tag::nchw}, eng);
write_to_dnnl_memory(user_src.data(), user_src_memory);
auto user_weights_memory
= memory({{conv1_weights_tz}, dt::f32, tag::oihw}, eng);
write_to_dnnl_memory(conv1_weights.data(), user_weights_memory);
auto conv1_user_bias_memory
= memory({{conv1_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(conv1_bias.data(), conv1_user_bias_memory);
//[Create user memory]
- 上面就是创建了
dnnl::memory类型的东西,同时把输入数据拷贝到里面去。 user_src_memory,user_weights_memory,conv1_user_bias_memory- 这三个东西是可以被
primitive操纵的东西。
- 这三个东西是可以被
- 下面就要创建conv这个
primitive了! - 分成4步
- 先创建这个
primitive的输入的memory descriptors- 这里注意他们和上面的
user_src_memory等不同,他们的tag都是any - 也就是输入和权重和bias的排布方式可任意,如果卷积要求的数据排步方式和输入的用户给的不一样,那就需要加上一些reorder算子来搞一搞
- 这里注意他们和上面的
- 再去创建卷积描述,这个描述是不涉及平台的!
- 最后创建
primitive_desc,他是涉及到平台的 - 最后根据
primitive_desc搞到primitive
- 先创建这个
//[Create convolution memory descriptors]
auto conv1_src_md = memory::desc({conv1_src_tz}, dt::f32, tag::any);
auto conv1_bias_md = memory::desc({conv1_bias_tz}, dt::f32, tag::any);
auto conv1_weights_md = memory::desc({conv1_weights_tz}, dt::f32, tag::any);
auto conv1_dst_md = memory::desc({conv1_dst_tz}, dt::f32, tag::any);
//[Create convolution memory descriptors]
//[Create convolution descriptor]
auto conv1_desc = convolution_forward::desc(prop_kind::forward_inference,
algorithm::convolution_auto, conv1_src_md, conv1_weights_md,
conv1_bias_md, conv1_dst_md, conv1_strides, conv1_padding,
conv1_padding);
//[Create convolution descriptor]
//[Create convolution primitive descriptor]
auto conv1_prim_desc = convolution_forward::primitive_desc(conv1_desc, eng);
//[Create convolution primitive descriptor]
- 下面就需要看看
conv1_src_memory和conv1_prim_desc所描述的数据拍步骤是否一样,如果不一样,那就需要干俩件事情- 根据
conv1_prim_desc.src_desc()为中间结果申请空间放置
- 根据
- 搞一个reorder把用户输入的权重
user_src_memory搞到刚刚申请到的conv1_src_memory里
- 搞一个reorder把用户输入的权重
- 同样对于权重也这样搞。
//[Reorder data and weights]
auto conv1_src_memory = user_src_memory;
if (conv1_prim_desc.src_desc() != user_src_memory.get_desc()) {
conv1_src_memory = memory(conv1_prim_desc.src_desc(), eng);
net.push_back(reorder(user_src_memory, conv1_src_memory));
net_args.push_back({{DNNL_ARG_FROM, user_src_memory},
{DNNL_ARG_TO, conv1_src_memory}});
}
auto conv1_weights_memory = user_weights_memory;
if (conv1_prim_desc.weights_desc() != user_weights_memory.get_desc()) {
conv1_weights_memory = memory(conv1_prim_desc.weights_desc(), eng);
reorder(user_weights_memory, conv1_weights_memory)
.execute(s, user_weights_memory, conv1_weights_memory);
}
//[Reorder data and weights]
- 输入和权重整理好了之后,就为输出申请空间吧,也就是搞一个tensor出来
//[Create memory for output]
auto conv1_dst_memory = memory(conv1_prim_desc.dst_desc(), eng);
//[Create memory for output]
//[Create convolution primitive]
net.push_back(convolution_forward(conv1_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv1_src_memory},
{DNNL_ARG_WEIGHTS, conv1_weights_memory},
{DNNL_ARG_BIAS, conv1_user_bias_memory},
{DNNL_ARG_DST, conv1_dst_memory}});
//[Create convolution primitive]
- 下面执行这个网络 吧
//[Execute model]
for (int j = 0; j < times; ++j) {
assert(net.size() == net_args.size() && "something is missing");
for (size_t i = 0; i < net.size(); ++i)
net.at(i).execute(s, net_args.at(i));
}
//[Execute model]
s.wait();
std::vector<float> output(batch * 32 * 112 * 112);
read_from_dnnl_memory(output.data(), conv1_dst_memory);
}
- 上面还把输出结果给读出来了,读到了output这个vector里了
void cnn_inference_f32(engine::kind engine_kind) {
auto begin = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::steady_clock::now().time_since_epoch())
.count();
int times = 1000;
simple_net(engine_kind, times);
auto end = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::steady_clock::now().time_since_epoch())
.count();
std::cout << "Use time: " << (end - begin) / (times + 0.0)
<< " ms per iteration." << std::endl;
}
int main(int argc, char **argv) {
return handle_example_errors(
cnn_inference_f32, parse_engine_kind(argc, argv));
}
- 完整的代码
#include <assert.h>
#include <chrono>
#include <vector>
#include <unordered_map>
#include "oneapi/dnnl/dnnl.hpp"
#include "../examples/example_utils.hpp"
using namespace dnnl;
void simple_net(engine::kind engine_kind, int times = 100) {
using tag = memory::format_tag;
using dt = memory::data_type;
//[Initialize engine and stream]
engine eng(engine_kind, 0);
stream s(eng);
//[Initialize engine and stream]
//[Create network]
std::vector<primitive> net;
std::vector<std::unordered_map<int, memory>> net_args;
//[Create network]
const memory::dim batch = 1;
// {batch, 3, 224, 224} (x) {32, 3, 3, 3} -> {batch, 32, 112, 112}
// strides: {2, 2}
memory::dims conv1_src_tz = {batch, 3, 224, 224};
memory::dims conv1_weights_tz = {32, 3, 3, 3};
memory::dims conv1_bias_tz = {32};
memory::dims conv1_dst_tz = {batch, 32, 112, 112};
memory::dims conv1_strides = {2, 2};
memory::dims conv1_padding = {1, 1};
//[Allocate buffers]
std::vector<float> user_src(batch * 3 * 224 * 224);
std::vector<float> conv1_weights(product(conv1_weights_tz));
std::vector<float> conv1_bias(product(conv1_bias_tz));
//[Allocate buffers]
//[Create user memory]
auto user_src_memory = memory({{conv1_src_tz}, dt::f32, tag::nchw}, eng);
write_to_dnnl_memory(user_src.data(), user_src_memory);
auto user_weights_memory
= memory({{conv1_weights_tz}, dt::f32, tag::oihw}, eng);
write_to_dnnl_memory(conv1_weights.data(), user_weights_memory);
auto conv1_user_bias_memory
= memory({{conv1_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(conv1_bias.data(), conv1_user_bias_memory);
//[Create user memory]
//[Create convolution memory descriptors]
auto conv1_src_md = memory::desc({conv1_src_tz}, dt::f32, tag::any);
auto conv1_bias_md = memory::desc({conv1_bias_tz}, dt::f32, tag::any);
auto conv1_weights_md = memory::desc({conv1_weights_tz}, dt::f32, tag::any);
auto conv1_dst_md = memory::desc({conv1_dst_tz}, dt::f32, tag::any);
//[Create convolution memory descriptors]
//[Create convolution descriptor]
auto conv1_desc = convolution_forward::desc(prop_kind::forward_inference,
algorithm::convolution_auto, conv1_src_md, conv1_weights_md,
conv1_bias_md, conv1_dst_md, conv1_strides, conv1_padding,
conv1_padding);
//[Create convolution descriptor]
//[Create convolution primitive descriptor]
auto conv1_prim_desc = convolution_forward::primitive_desc(conv1_desc, eng);
//[Create convolution primitive descriptor]
//[Reorder data and weights]
auto conv1_src_memory = user_src_memory;
if (conv1_prim_desc.src_desc() != user_src_memory.get_desc()) {
conv1_src_memory = memory(conv1_prim_desc.src_desc(), eng);
net.push_back(reorder(user_src_memory, conv1_src_memory));
net_args.push_back({{DNNL_ARG_FROM, user_src_memory},
{DNNL_ARG_TO, conv1_src_memory}});
}
auto conv1_weights_memory = user_weights_memory;
if (conv1_prim_desc.weights_desc() != user_weights_memory.get_desc()) {
conv1_weights_memory = memory(conv1_prim_desc.weights_desc(), eng);
reorder(user_weights_memory, conv1_weights_memory)
.execute(s, user_weights_memory, conv1_weights_memory);
}
//[Reorder data and weights]
//[Create memory for output]
auto conv1_dst_memory = memory(conv1_prim_desc.dst_desc(), eng);
//[Create memory for output]
//[Create convolution primitive]
net.push_back(convolution_forward(conv1_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv1_src_memory},
{DNNL_ARG_WEIGHTS, conv1_weights_memory},
{DNNL_ARG_BIAS, conv1_user_bias_memory},
{DNNL_ARG_DST, conv1_dst_memory}});
//[Create convolution primitive]
//[Execute model]
for (int j = 0; j < times; ++j) {
assert(net.size() == net_args.size() && "something is missing");
for (size_t i = 0; i < net.size(); ++i)
net.at(i).execute(s, net_args.at(i));
}
//[Execute model]
s.wait();
std::vector<float> output(batch * 32 * 112 * 112);
read_from_dnnl_memory(output.data(), conv1_dst_memory);
}
void cnn_inference_f32(engine::kind engine_kind) {
auto begin = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::steady_clock::now().time_since_epoch())
.count();
int times = 1000;
simple_net(engine_kind, times);
auto end = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::steady_clock::now().time_since_epoch())
.count();
std::cout << "Use time: " << (end - begin) / (times + 0.0)
<< " ms per iteration." << std::endl;
}
int main(int argc, char **argv) {
return handle_example_errors(
cnn_inference_f32, parse_engine_kind(argc, argv));
}
- 执行上面的代码你会发现,运行时间变化好大啊,可能这就是JIT的特点吧
- 毕竟上面的代码只有2个算子
- src/cpu/x64/jit_uni_reorder.cpp
- jit_uni_reorder_kernel_f32
- src/cpu/x64/jit_avx2_conv_kernel_f32.hpp
- jit_avx2_conv_fwd_kernel_f32
然后我把输入通道改成8个通道,他就居然还多了一个kernel,气死我了!
jit_avx2_conv_fwd_kernel_f32这个结构体就是执行上面的那个卷积
struct jit_avx2_conv_fwd_kernel_f32 : public jit_generator {
jit_avx2_conv_fwd_kernel_f32(const jit_conv_conf_t &ajcp,
const primitive_attr_t &attr, const memory_desc_t &dst_md);
inline void jit_avx2_conv_fwd_kernel_f32::solve_common(int oc_blocks) {
int ur_w = jcp.ur_w;
int ur_w_tail = jcp.ur_w_tail;
int n_oi = jcp.ow / ur_w;
int iw = jcp.iw;
int kw = jcp.kw;
std::cout <<iw << std::endl;
int str_w = jcp.stride_w;
- 上面这个就是卷积的入口了!
- 哪个地方开始调这个卷积呢?
- 就是
jit_avx2_conv_fwd_kernel_f32::generate
void jit_avx2_conv_fwd_kernel_f32::generate() {
this->preamble();
void preamble() {
if (xmm_to_preserve) {
sub(rsp, xmm_to_preserve * xmm_len);
for (size_t i = 0; i < xmm_to_preserve; ++i)
uni_vmovdqu(ptr[rsp + i * xmm_len],
Xbyak::Xmm(xmm_to_preserve_start + i));
}
for (size_t i = 0; i < num_abi_save_gpr_regs; ++i)
push(Xbyak::Reg64(abi_save_gpr_regs[i]));
if (is_valid_isa(avx512_common)) {
mov(reg_EVEX_max_8b_offt, 2 * EVEX_max_8b_offt);
}
}
mov(reg_input, ptr[this->param1 + GET_OFF(src)]);
mov(reg_output, ptr[this->param1 + GET_OFF(dst)]);
mov(reg_kernel, ptr[this->param1 + GET_OFF(filt)]);
if (jcp.with_bias) mov(reg_bias, ptr[this->param1 + GET_OFF(bias)]);
mov(reg_kh, ptr[this->param1 + GET_OFF(kh_padding)]);
mov(reg_ci_flag, ptr[this->param1 + GET_OFF(flags)]);
mov(reg_oc_blocks, ptr[this->param1 + GET_OFF(oc_blocks)]);
if (is_src_layout_nxc())
mov(reg_channel, ptr[param1 + GET_OFF(reduce_work)]);
- 你看上面:
- 他是依靠这种方法把指针传给寄存器的!
- 但是如果我这样做的话,他会报错,说offset is too big!
this->param1到底是jit_avx2_conv_fwd_kernel_f32类的哪个成员啊?
- 他妈的,居然是
jit_generator的成员啊!
Xbyak::Reg64 param1 = abi_param1;
const int EVEX_max_8b_offt = 0x200;
int nb_oc_tail = jcp.nb_oc % jcp.nb_oc_blocking;
Label tail, exit;
if (jcp.nb_oc > jcp.nb_oc_blocking) {
cmp(reg_oc_blocks, jcp.nb_oc_blocking);
jne(nb_oc_tail ? tail : exit, T_NEAR);
solve_common(jcp.nb_oc_blocking);
jmp(exit, T_NEAR);
if (nb_oc_tail) {
L(tail);
cmp(reg_oc_blocks, nb_oc_tail);
jne(exit, T_NEAR);
solve_common(nb_oc_tail);
}
L(exit);
} else if (jcp.nb_oc == jcp.nb_oc_blocking) {
solve_common(jcp.nb_oc_blocking);
} else {
solve_common(nb_oc_tail);
}
this->postamble();
if (jcp.with_eltwise) postops_injector_->prepare_table();
}
- 上面从
generate这个地方开始调用了solve_common函数! - 上面都是在kernel层面的东西。
- 我感觉就是在
this->postamble();和this->preamble();之间生成代码的!
struct jit_avx2_conv_fwd_kernel_f32 : public jit_generator {
jit_avx2_conv_fwd_kernel_f32(const jit_conv_conf_t &ajcp,
const primitive_attr_t &attr, const memory_desc_t &dst_md);
DECLARE_CPU_JIT_AUX_FUNCTIONS(jit_avx2_conv_fwd_kernel_f32)
static status_t init_conf(jit_conv_conf_t &jcp,
const convolution_desc_t &cd, const memory_desc_wrapper &src_d,
const memory_desc_wrapper &weights_d,
const memory_desc_wrapper &dst_d, const primitive_attr_t &attr);
static void init_scratchpad(memory_tracking::registrar_t &scratchpad,
const jit_conv_conf_t &jcp);
jit_conv_conf_t jcp;
const primitive_attr_t &attr_;
private:
std::unique_ptr<injector::jit_uni_postops_injector_t<avx2>>
postops_injector_;
constexpr static int isa_simd_width_
= cpu_isa_traits<avx2>::vlen / sizeof(float);
using reg64_t = const Xbyak::Reg64;
reg64_t reg_input = rax;
reg64_t aux_reg_input = r8;
reg64_t reg_kernel = rdx;
reg64_t aux_reg_kernel = r9;
reg64_t reg_output = rsi;
reg64_t reg_bias = rbx;
reg64_t aux_reg_inp_d = r11;
reg64_t aux_reg_ker_d = abi_not_param1;
reg64_t reg_ki = rsi;
reg64_t kj = r10;
reg64_t oi_iter = r11;
reg64_t ki_iter = r12;
reg64_t reg_channel = ki_iter;
reg64_t reg_kh = abi_not_param1;
reg64_t reg_oc_blocks = r14;
reg64_t imm_addr64 = r15;
reg64_t reg_long_offt = r15;
Xbyak::Reg32 reg_ci_flag = r13d;
Xbyak::Reg32 reg_oc_flag = r14d;
/* binary post-ops operand */
reg64_t temp_offset_reg = r12;
Xbyak::Ymm ytmp = Xbyak::Ymm(14);
inline void oh_step_unroll_kw(
int ur_w, int pad_l, int pad_r, int oc_blocks);
inline void oh_step_nopad(int ur_w, int pad_l, int pad_r, int oc_blocks);
void apply_postops(const int oc_blocks, const int ur_w, const int oc_tail);
inline void width_blk_step(int ur_w, int pad_l, int pad_r, int oc_blocks);
inline void solve_common(int oc_blocks);
inline dim_t filter_w_to_input(int ki, int oi = 0, int pad_l = 0) {
return ki * (jcp.dilate_w + 1) + oi * jcp.stride_w - pad_l;
};
inline dim_t filter_h_to_input(int ki) {
return ki * (jcp.dilate_h + 1) * jcp.iw;
};
inline dim_t filter_d_to_input(int ki) {
return ki * (jcp.dilate_d + 1) * jcp.iw * jcp.ih;
};
inline dim_t get_input_offset(int i_ic, int i_iw) {
dim_t offset;
if (utils::one_of(jcp.src_tag, format_tag::ncw, format_tag::nchw,
format_tag::ncdhw)) {
offset = i_ic * jcp.id * jcp.ih * jcp.iw + i_iw;
} else if (utils::one_of(jcp.src_tag, format_tag::nwc, format_tag::nhwc,
format_tag::ndhwc)) {
offset = i_iw * jcp.ic * jcp.ngroups + i_ic;
} else {
offset = i_iw * jcp.ic_block + i_ic;
}
return sizeof(float) * offset;
}
inline dim_t get_output_offset(int i_oc_block, int i_ow) {
dim_t offset;
if (utils::one_of(jcp.dst_tag, format_tag::nwc, format_tag::nhwc,
format_tag::ndhwc)) {
offset = i_ow * jcp.oc * jcp.ngroups + i_oc_block * jcp.oc_block;
} else {
offset = i_oc_block * jcp.od * jcp.oh * jcp.ow * jcp.oc_block
+ i_ow * jcp.oc_block;
}
return sizeof(float) * offset;
}
inline dim_t get_kernel_offset(int i_oc_block, int ki, int i_ic) {
dim_t block_step_size = jcp.ic_block * jcp.oc_block;
dim_t ic_block_step_size = jcp.kd * jcp.kh * jcp.kw * block_step_size;
dim_t oc_block_step_size = jcp.nb_ic * ic_block_step_size;
dim_t offset = i_oc_block * oc_block_step_size + ki * block_step_size
+ i_ic * jcp.oc_block;
return sizeof(float) * offset;
}
inline bool is_src_layout_nxc() {
return utils::one_of(jcp.src_tag, format_tag::ndhwc, format_tag::nhwc,
format_tag::nwc);
}
void generate() override;
};
- 下面是在
primitive层面的东西src/cpu/x64/jit_avx2_convolution.hpp
struct jit_avx2_convolution_fwd_t : public primitive_t {
struct pd_t : public cpu_convolution_fwd_pd_t {
pd_t(const convolution_desc_t *adesc, const primitive_attr_t *attr,
const typename pd_t::base_class *hint_fwd_pd)
: cpu_convolution_fwd_pd_t(adesc, attr, hint_fwd_pd), jcp_() {}
DECLARE_COMMON_PD_T(JIT_IMPL_NAME_HELPER("jit:", jcp_.isa, ""),
jit_avx2_convolution_fwd_t);
status_t init(engine_t *engine) {
bool ok = true && is_fwd()
&& set_default_alg_kind(alg_kind::convolution_direct)
&& expect_data_types(data_type::f32, data_type::f32,
data_type::f32, data_type::f32, data_type::f32)
&& attr()->has_default_values(
primitive_attr_t::skip_mask_t::post_ops,
data_type::f32)
&& !has_zero_dim_memory() && set_default_formats()
&& attr_.set_default_formats(dst_md(0)) == status::success;
if (!ok) return status::unimplemented;
CHECK(jit_avx2_conv_fwd_kernel_f32::init_conf(
jcp_, *desc(), src_md(), weights_md(), dst_md(), *attr()));
auto scratchpad = scratchpad_registry().registrar();
jit_avx2_conv_fwd_kernel_f32::init_scratchpad(scratchpad, jcp_);
return status::success;
}
jit_conv_conf_t jcp_;
protected:
bool set_default_formats() {
using namespace format_tag;
const bool flat = IC() < 8;
auto src_tag = flat
? utils::pick(ndims() - 3, ncw, nchw, ncdhw)
: utils::pick(ndims() - 3, nCw8c, nChw8c, nCdhw8c);
auto dst_tag = utils::pick(ndims() - 3, nCw8c, nChw8c, nCdhw8c);
auto wei_tag = with_groups()
? utils::pick(2 * ndims() - 6 + flat, gOIw8i8o, gOwi8o,
gOIhw8i8o, gOhwi8o, gOIdhw8i8o, gOdhwi8o)
: utils::pick(2 * ndims() - 6 + flat, OIw8i8o, Owi8o,
OIhw8i8o, Ohwi8o, OIdhw8i8o, Odhwi8o);
return set_default_formats_common(src_tag, wei_tag, dst_tag);
}
};
jit_avx2_convolution_fwd_t(const pd_t *apd) : primitive_t(apd) {}
typedef typename prec_traits<data_type::f32>::type data_t;
status_t init(engine_t *engine) override {
CHECK(safe_ptr_assign(kernel_,
new jit_avx2_conv_fwd_kernel_f32(
pd()->jcp_, *pd()->attr(), *pd()->dst_md(0))));
return kernel_->create_kernel();
}
status_t execute(const exec_ctx_t &ctx) const override {
execute_forward(ctx);
return status::success;
}
private:
void execute_forward(const exec_ctx_t &ctx) const;
const pd_t *pd() const { return (const pd_t *)primitive_t::pd().get(); }
std::unique_ptr<jit_avx2_conv_fwd_kernel_f32> kernel_;
};
- 上面是
jit_avx2_convolution_fwd_t这个primitive- 他有一个成员函数,看到他在这里面new了一个
jit_avx2_conv_fwd_kernel_f32
- 他有一个成员函数,看到他在这里面new了一个
status_t init(engine_t *engine) override {
CHECK(safe_ptr_assign(kernel_,
new jit_avx2_conv_fwd_kernel_f32(
pd()->jcp_, *pd()->attr(), *pd()->dst_md(0))));
return kernel_->create_kernel();
}
- 并且上面已经创建了kernel。
- 而且,这个create_kernel()居然是
jit_generator的函数
- 而且,这个create_kernel()居然是
virtual status_t create_kernel() {
generate();
jit_ker_ = getCode();
return (jit_ker_) ? status::success : status::runtime_error;
}
crete_kernel是jit_generator的函数,里面掉了generate(),jit_avx2_conv_fwd_kernel_f32也含有这个函数,那请问这里的generate();到底是谁的呢?当然不是是jit_generator的啦!它的是纯虚函数!哈哈!
- 下面是
jit_generator的getCode函数!
const Xbyak::uint8 *getCode() {
this->ready();
if (!is_initialized()) return nullptr;
const Xbyak::uint8 *code = CodeGenerator::getCode();
register_jit_code(code, getSize());
return code;
}
oneDNN的卷积类型
- Direct.
- using SIMD
- 大多数形状都用它
- int8, f32 and bf16 data types.
- Winograd.
- 减少计算量,可能降低精度,增加内存操作
- 只对特定shape
- int8 and f32
- Implicit GEMM
- The convolution operation is reinterpreted in terms of matrix-matrix multiplication by rearranging the source data into a scratchpad memory.
- This is a fallback algorithm that is dispatched automatically when other implementations are not available.
- int8, f32, and bf16
oneDNN Documentation
- 链接在这
- 这个文档基本就是一本书了,讲解了好多东西,分成好多章节
Basic Concepts
Introduction
- In this page, an outline of the oneDNN programming model is presented, and the key concepts are discussed, including
Primitives,Engines,Streams, andMemory Objects - In essence, oneDNN programming model consists in
- executing one or several primitives to process data in one or several memory objects.
- The execution is performed on an engine in the context of a stream.
stream类似于啥呢?
- The relationship between these entities is briefly presented in Figure 1, which also includes additional concepts relevant to the oneDNN programming model, such as primitive attributes and descriptors. These concepts are described below in much more details.

Primitives
- oneDNN is built around the notion of a primitive (
dnnl::primitive) - A primitive is an object that encapsulates a particular computation such as forward convolution, backward LSTM computations, or a data transformation operation.
- Additionally, using primitive attributes (
dnnl::primitive_attr) certain primitives can represent more complex fused computations such as a forward convolution followed by a ReLU.
- The most important difference between a primitive and a pure function is that a primitive can store state.
- One part of the primitive’s state is immutable.
- convolution primitives store parameters like tensor shapes and can pre-compute other dependent parameters like cache blocking.
啥叫cache blocking呢,记得问啊!
- This approach allows oneDNN primitives to pre-generate code specifically tailored for the operation to be performed.
- The oneDNN programming model assumes that the time it takes to perform the pre-computations is amortized by reusing the same primitive to perform computations multiple times.
预测里面一个卷积只执行一次哦!可是训练的时候要执行很多次啊!
- The mutable part of the primitive’s state is referred to as a scratchpad.
- It is a memory buffer that a primitive may use for temporary storage only during computations.
- The scratchpad can either be owned by a primitive object (which makes that object non-thread safe) or be an execution-time parameter.

Engines
dnnl::engineis an abstraction of a computational device: a CPU, a specific GPU card in the system, etc.- Most primitives are created to execute computations on one specific engine.
- The only exceptions are reorder primitives that transfer data between two different engines.
Streams
dnnl::streamencapsulate execution context tied to a particular engine.- For example, they can correspond to OpenCL command queues.
Memory Objects
dnnl::memoryencapsulate handles to memory allocated on a specific engine, tensor dimensions, data type, and memory format – the way tensor indices map to offsets in linear memory space.- Memory objects are passed to primitives during execution.
下面还有好多东西没写呢!
Getting started
- This C++ API example demonstrates the basics of the oneDNN programming model.
- Example code: getting_started.cpp
- demonstrates the basics of the oneDNN programming model:
- How to create oneDNN memory objects.
- How to get data from the user’s buffer into a oneDNN memory object.
- How a tensor’s logical dimensions and memory object formats relate.
- How to create oneDNN primitives.
- How to execute the primitives.
- The example uses the ReLU operation and comprises the following steps:
- Creating Engine and stream to execute a primitive.
- Performing Data preparation (code outside of oneDNN).
- Wrapping data into a oneDNN memory object (using different flavors).
- Creating a ReLU primitive.
- Executing the ReLU primitive.
- Obtaining the result and validation (checking that the resulting image does not contain negative values).
- These steps are implemented in the getting_started_tutorial(),
- which in turn is called from main() (which is also responsible for error handling).
Public headers
- To start using oneDNN we must first include dnnl.hpp
- We also include dnnl_debug.h in example_utils.hpp,
- which contains some debugging facilities like returning a string representation for common oneDNN C types.
getting_started_tutorial() function
Engine and stream
- All oneDNN primitives and memory objects are attached to a particular dnnl::engine, which is an abstraction of a computational device (see also Basic Concepts).
- The primitives are created and optimized for the device they are attached to and the memory objects refer to memory residing on the corresponding device.
- In particular, that means neither memory objects nor primitives that were created for one engine can be used on another.
- To create an engine, we should specify the
dnnl::engine::kind- and the index of the device of the given kind.
engine eng(engine_kind, 0);
- and the index of the device of the given kind.
- In addition to an engine, all primitives require a
dnnl::streamfor the execution. - The stream encapsulates an execution context and is tied to a particular engine.
- The creation is pretty straightforward:
stream engine_stream(eng); - In the simple cases, when a program works with one device only (e.g. only on CPU), an engine and a stream can be created once and used throughout the program.
- Some frameworks create singleton objects that hold oneDNN engine and stream and use them throughout the code.
Data preparation (code outside of oneDNN)
- Now that the preparation work is done, let’s create some data to work with.
- We will create a 4D tensor in NHWC format, which is quite popular in many frameworks.
- Note that even though we work with one image only, the image tensor is still 4D.
- The extra dimension (here N) corresponds to the batch, and, in case of a single image, is equal to 1.
- It is pretty typical to have the batch dimension even when working with a single image.
- In oneDNN, all CNN primitives assume that tensors have the batch dimension, which is always the first logical dimension (see also Naming Conventions).
他妈逼,下面有猫病吧!还[=],记得问啊!
const int N = 1, H = 13, W = 13, C = 3;
// Compute physical strides for each dimension
const int stride_N = H * W * C;
const int stride_H = W * C;
const int stride_W = C;
const int stride_C = 1;
// An auxiliary function that maps logical index to the physical offset
auto offset = [=](int n, int h, int w, int c) {
return n * stride_N + h * stride_H + w * stride_W + c * stride_C;
};
// The image size
const int image_size = N * H * W * C;
// Allocate a buffer for the image
std::vector<float> image(image_size);
// Initialize the image with some values
for (int n = 0; n < N; ++n)
for (int h = 0; h < H; ++h)
for (int w = 0; w < W; ++w)
for (int c = 0; c < C; ++c) {
int off = offset(
n, h, w, c); // Get the physical offset of a pixel
image[off] = -std::cos(off / 10.f);
}
Wrapping data into a oneDNN memory object
- Now, having the image ready, let’s wrap it in a
dnnl::memoryobject to be able to pass the data to oneDNN primitives. - Creating dnnl::memory comprises two steps:
- Initializing the
dnnl::memory::descstruct (also referred to as a memory descriptor), which only describes the tensor data and doesn’t contain the data itself. - Memory descriptors are used to create
dnnl::memoryobjects and to initialize primitive descriptors (shown later in the example).
- Creating the
dnnl::memoryobject itself (also referred to as a memory object), based on the memory descriptor initialized in step 1, an engine, and, optionally, a handle to data. The memory object is used when a primitive is executed.
- Thanks to the list initialization introduced in C++11, it is possible to combine these two steps whenever a memory descriptor is not used anywhere else but in creating a dnnl::memory object.
- However, for the sake of demonstration, we will show both steps explicitly.
Memory descriptor
- To initialize the
dnnl::memory::desc, we need to pass: - The tensor’s dimensions, the semantic order of which is defined by the primitive that will use this memory (descriptor). Which leads to the following: .. warning:
Memory descriptors and objects are not aware of any meaning of the data they describe or contain.
- The data type for the tensor (dnnl::memory::data_type).
- The memory format tag (
dnnl::memory::format_tag) that describes how the data is going to be laid out in the device’s memory. - The memory format is required for the primitive to correctly handle the data.
auto src_md = memory::desc(
{N, C, H, W}, // logical dims, the order is defined by a primitive
memory::data_type::f32, // tensor's data type
memory::format_tag::nhwc // memory format, NHWC in this case
);
- The first thing to notice here is that we pass dimensions as {N, C, H, W} while it might seem more natural to pass {N, H, W, C}, which better corresponds to the user’s code.
- This is because oneDNN CNN primitives like ReLU always expect tensors in the following form:
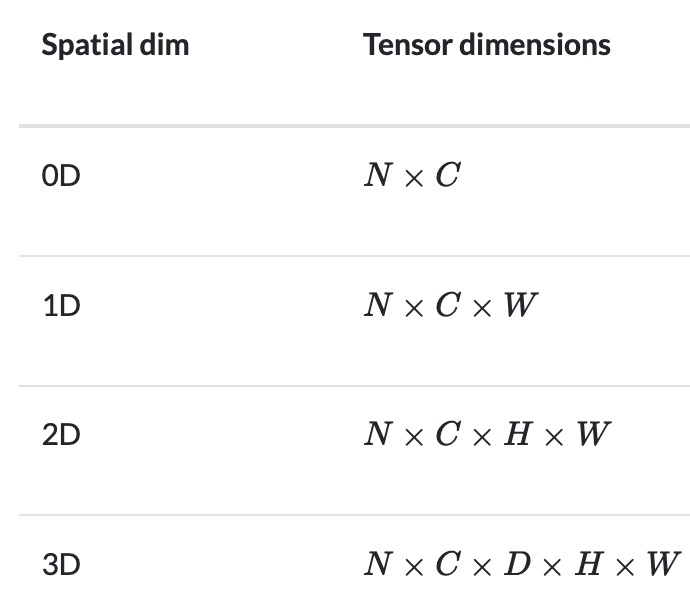
- N is a batch dimension (discussed above),
- C is channel (aka feature maps) dimension, and
- D, H, and W are spatial dimensions.
- Now that the logical order of dimension is defined, we need to specify the memory format (the third parameter), which describes how logical indices map to the offset in memory.
- This is the place where the user’s format NHWC comes into play.
- oneDNN has different
dnnl::memory::format_tagvalues that cover the most popular memory formats like NCHW, NHWC, CHWN, and some others.
- The memory descriptor for the image is called src_md.
- The src part comes from the fact that the image will be a source for the ReLU primitive (that is, we formulate memory names from the primitive perspective; hence we will use dst to name the output memory).
- The md is an initialism for Memory Descriptor.
Alternative way to create a memory descriptor¶
- Before we continue with memory creation, let us show the alternative way to create the same memory descriptor:
- instead of using the dnnl::memory::format_tag, we can directly specify the strides of each tensor dimension:
auto alt_src_md = memory::desc(
{N, C, H, W}, // logical dims, the order is defined by a primitive
memory::data_type::f32, // tensor's data type
{stride_N, stride_C, stride_H, stride_W} // the strides
);
// Sanity check: the memory descriptors should be the same
if (src_md != alt_src_md)
throw std::logic_error("Memory descriptor initialization mismatch.");
- Just as before, the tensor’s dimensions come in the N, C, H, W order as required by CNN primitives.
- To define the physical memory format, the strides are passed as the third parameter. Note that the order of the strides corresponds to the order of the tensor’s dimensions. .. warning:
Using the wrong order might lead to incorrect results or even a crash.
Creating a memory object
- a memory descriptor and an engine prepared,
- create input and output memory objects for a ReLU primitive.
// src_mem contains a copy of image after write_to_dnnl_memory function
auto src_mem = memory(src_md, eng);
write_to_dnnl_memory(image.data(), src_mem);
// For dst_mem the library allocates buffer
auto dst_mem = memory(src_md, eng);
- We already have a memory buffer for the source memory object.
- We pass it to the
dnnl::memory::memory(const desc &, const engine &, void *)constructor that takes a buffer pointer as its last argument.
- Let’s use a constructor that instructs the library to allocate a memory buffer for the dst_mem for educational purposes.
- The key difference between these two are:
- The library will own the memory for dst_mem and will deallocate it when dst_mem is destroyed.
- That means the memory buffer can be used only while dst_mem is alive.
Library-allocated buffers have good alignment, which typically results in better performance.
- Memory allocated outside of the library and passed to oneDNN should have good alignment for better performance.
In the subsequent section we will show how to get the buffer (pointer) from the dst_mem memory object.
Creating a ReLU primitive
- Let’s now create a ReLU primitive.
- The library implements ReLU primitive as a particular algorithm of a more general Eltwise primitive, which applies a specified function to each and every element of the source tensor.
- Just as in the case of
dnnl::memory, a user should always go through (at least) three creation steps (which however, can be sometimes combined thanks to C++11):
- Initialize an operation descriptor (here,
dnnl::eltwise_forward::desc), which defines the operation parameters.
算子参数啊!
- Create an operation primitive descriptor (here
dnnl::eltwise_forward::primitive_desc), which is a lightweight descriptor of the actual algorithm that implements the given operation. The user can query different characteristics of the chosen implementation such as memory consumptions and some others that will be covered in the next topic (Memory Format Propagation). - Create a primitive (here
dnnl::eltwise_forward) that can be executed on memory objects to compute the operation.
- oneDNN separates steps 2 and 3 to enable the user to inspect details of a primitive implementation prior to creating the primitive.
- This may be expensive, because, for example, oneDNN generates the optimized computational code on the fly.
- Primitive creation might be a very expensive operation, so consider creating primitive objects once and executing them multiple times.
// ReLU op descriptor (no engine- or implementation-specific information)
auto relu_d = eltwise_forward::desc(
prop_kind::forward_inference, algorithm::eltwise_relu,
src_md, // the memory descriptor for an operation to work on
0.f, // alpha parameter means negative slope in case of ReLU
0.f // beta parameter is ignored in case of ReLU
);
// ReLU primitive descriptor, which corresponds to a particular
// implementation in the library
auto relu_pd
= eltwise_forward::primitive_desc(relu_d, // an operation descriptor
eng // an engine the primitive will be created for
);
// ReLU primitive
auto relu = eltwise_forward(relu_pd); // !!! this can take quite some time
- It is worth mentioning that we specified the exact tensor and its memory format when we were initializing the relu_d.
- That means relu primitive would perform computations with memory objects that correspond to this description.
- This is the one and only one way of creating non-compute-intensive primitives like Eltwise, Batch Normalization, and others.
最后一句话啥意思啊?
- Compute-intensive primitives (like Convolution) have an ability to define the appropriate memory format on their own.
- This is one of the key features of the library and will be discussed in detail in the next topic: Memory Format Propagation.
啥意思?卷积还能自己定义内存形式啊?
Executing the ReLU primitive
- Finally, let’s execute the primitive and wait for its completion.
- The input and output memory objects are passed to the execute() method using a <tag, memory> map.
- Each tag specifies what kind of tensor each memory object represents.
- All Eltwise primitives require the map to have two elements: a source memory object (input) and a destination memory (output).
- A primitive is executed in a stream (the first parameter of the execute() method).
- Depending on a stream kind, an execution might be blocking or non-blocking.
- This means that we need to call dnnl::stream::wait before accessing the results.
// Execute ReLU (out-of-place)
relu.execute(engine_stream, // The execution stream
{
// A map with all inputs and outputs
{DNNL_ARG_SRC, src_mem}, // Source tag and memory obj
{DNNL_ARG_DST, dst_mem}, // Destination tag and memory obj
});
// Wait the stream to complete the execution
engine_stream.wait();
- The Eltwise is one of the primitives that support in-place operations,
- meaning that the source and destination memory can be the same.
- To perform in-place transformation, the user must pass the same memory object for both the DNNL_ARG_SRC and DNNL_ARG_DST tags:
// Execute ReLU (in-place)
// relu.execute(engine_stream, {
// {DNNL_ARG_SRC, src_mem},
// {DNNL_ARG_DST, src_mem},
// });
Supported Primitives
Convolution
General
- The convolution primitive computes forward, backward, or weight update for a batched convolution operation on 1D, 2D, or 3D spatial data with bias.
- The convolution operation is defined by the following formulas.
- We show formulas only for 2D spatial data which are straightforward to generalize to cases of higher and lower dimensions.
- Variable names follow the standard Naming Conventions.

- The following formulas show how oneDNN computes convolutions.
- They are broken down into several types to simplify the exposition, but in reality the convolution types can be combined.

好多没写啊!
Algorithms
- oneDNN implements convolution primitives using several different algorithms:
- Direct.
- using SIMD instructions.
- This is the algorithm used for the most shapes
- int8, f32 and bf16 data types.
- Winograd.
- reduces computational complexity of convolution at the expense of accuracy loss and additional memory operations.
- The implementation is based on the Fast Algorithms for Convolutional Neural Networks by A. Lavin and S. Gray.
- The Winograd algorithm often results in the best performance, but it is applicable only to particular shapes.
- int8 and f32 data types.
- Implicit GEMM.
- The convolution operation is reinterpreted in terms of matrix-matrix multiplication by rearranging the source data into a scratchpad memory.
- This is a fallback algorithm that is dispatched automatically when other implementations are not available.
- int8, f32, and bf16
Direct Algorithm
- oneDNN supports the direct convolution algorithm on all supported platforms for the following conditions:
- Data and weights memory formats are defined by the convolution primitive (user passes any).
- The number of channels per group is a multiple of SIMD width for grouped convolutions.
请问指的ic呢还是oc呢?
- For each spatial direction padding does not exceed one half of the corresponding dimension of the weights tensor.
- Weights tensor width does not exceed 14.
- In case any of these constraints are not met, the implementation will silently fall back to an explicit GEMM algorithm.
oneAPI Deep Neural Network Library (oneDNN)
- This software was previously known as Intel(R) Math Kernel Library for Deep Neural Networks (Intel(R) MKL-DNN)
- and Deep Neural Network Library (DNNL)
![]()
- oneAPI Deep Neural Network Library (oneDNN) is an open-source cross-platform
performance library of basic building blocks for deep learning applications.
oneDNN is part of oneAPI. - The library is optimized for Intel Architecture Processors, Intel Processor
Graphics and Xe Architecture graphics. - oneDNN has experimental support for the following architectures:
- Arm* 64-bit Architecture (AArch64),
- NVIDIA* GPU,
- OpenPOWER* Power ISA (PPC64),
- IBMz* (s390x).
- oneDNN is intended for deep learning applications and framework developers interested in improving application performance on Intel CPUs and GPUs.
- Deep learning practitioners should use one of the applications enabled with oneDNN
Documentation
- Developer guide explains programming
model, supported functionality, and implementation details, and includes annotated examples.
特码比,我应该看这个啊!
- API reference provides
a comprehensive reference of the library API.
Installation
Binary distribution of this software is available as:
- Intel oneAPI Deep Neural Network Library
in Intel oneAPI. - oneAPI Deep Neural Network Library
in Anaconda.
Pre-built binaries for Linux*, Windows*, and macOS* are available for download in the
releases section.
Package names use the following convention:
| OS | Package name |
|---|---|
| Linux | dnnl_lnx_<version>_cpu_<cpu runtime>[_gpu_<gpu runtime>].tgz |
| Windows | dnnl_win_<version>_cpu_<cpu runtime>[_gpu_<gpu runtime>].zip |
| macOS | dnnl_mac_<version>_cpu_<cpu runtime>.tgz |
Several packages are available for each operating system to ensure
interoperability with CPU or GPU runtime libraries used by the application.
| Configuration | Dependency |
|---|---|
cpu_iomp |
Intel OpenMP runtime |
cpu_gomp |
GNU* OpenMP runtime |
cpu_vcomp |
Microsoft Visual C OpenMP runtime |
cpu_tbb |
Threading Building Blocks (TBB) |
cpu_dpcpp_gpu_dpcpp |
Intel oneAPI DPC++ Compiler, TBB, OpenCL runtime, oneAPI Level Zero runtime |
The packages do not include library dependencies and these need to be resolved
in the application at build time. See the
System Requirements section below and the
Build Options
section in the developer guide for more
details on CPU and GPU runtimes.
If the configuration you need is not available, you can
build the library from source.
System Requirements
oneDNN supports platforms based on the following architectures:
- Intel 64 or AMD64,
- Arm 64-bit Architecture (AArch64).
- OpenPOWER / IBM Power ISA.
- IBMz z/Architecture (s390x).
WARNING
Arm 64-bit Architecture (AArch64), Power ISA (PPC64) and IBMz (s390x) support
is experimental with limited testing validation.
The library is optimized for the following CPUs:
- Intel Atom processor with Intel SSE4.1 support
- 4th, 5th, 6th, 7th, and 8th generation Intel(R) Core(TM) processor
- Intel(R) Xeon(R) processor E3, E5, and E7 family (formerly Sandy Bridge,
Ivy Bridge, Haswell, and Broadwell) - Intel(R) Xeon Phi(TM) processor (formerly Knights Landing and Knights Mill)
- Intel Xeon Scalable processor (formerly Skylake, Cascade Lake, and Cooper
Lake) - future Intel Xeon Scalable processor (code name Sapphire Rapids)
On a CPU based on Intel 64 or on AMD64 architecture,
oneDNN detects the ISA at runtime and uses JIT code generation to deploy the code optimized for the latest supported ISA.
Future ISAs may have initial support in the library disabled by default and
require the use of run-time controls to enable them.
这啥意思啊?See CPU dispatcher control for more details.
- On a CPU based on Arm AArch64 architecture, oneDNN can be built with Arm Compute Library integration.
- Compute Library is an open-source library for machine learning applications
and provides AArch64 optimized implementations of core functions. This functionality currently
requires that Compute Library is downloaded and built separately, see
Build from Source. oneDNN is only
compatible with Compute Library versions 21.05 or later.
WARNING
On macOS, applications that use oneDNN may need to request special
entitlements if they use the hardened runtime. See the
linking guide
for more details.
The library is optimized for the following GPU architectures:
- Intel Processor Graphics Gen9, Gen9.5 and Gen11 architectures
- Xe architecture
Requirements for Building from Source
oneDNN supports systems meeting the following requirements:
- Operating system with Intel 64 / Arm 64 / Power / IBMz architecture support
- C++ compiler with C++11 standard support
- CMake 2.8.12 or later
- Arm Compute Library
for builds using Compute Library on AArch64.
The following tools are required to build oneDNN documentation:
- Doxygen 1.8.5 or later
- Doxyrest 2.1.2 or later
- Sphinx 4.0.2 or later
- sphinx-book-theme 0.0.41 or later
卧槽他妈,编译文档还要上面的东西啊?
Configurations of CPU and GPU engines may introduce additional build time
dependencies.
CPU Engine
oneDNN CPU engine is used to execute primitives on Intel Architecture
Processors, 64-bit Arm Architecture (AArch64) processors,
64-bit Power ISA (PPC64) processors, IBMz (s390x), and compatible devices.
The CPU engine is built by default but can be disabled at build time by setting
DNNL_CPU_RUNTIME to NONE. In this case, GPU engine must be enabled.
The CPU engine can be configured to use the OpenMP, TBB or DPCPP runtime.
The following additional requirements apply:
- OpenMP runtime requires C++ compiler with OpenMP 2.0 or later
standard support - TBB runtime requires
Threading Building Blocks (TBB)
2017 or later. - DPCPP runtime requires
Some implementations rely on OpenMP 4.0 SIMD extensions. For the best
performance results on Intel Architecture Processors we recommend using the
Intel C++ Compiler.
GPU Engine
Intel Processor Graphics and Xe Architecture graphics are supported by
the oneDNN GPU engine. The GPU engine is disabled in the default build
configuration. The following additional requirements apply when GPU engine
is enabled:
- OpenCL runtime requires
- OpenCL* runtime library (OpenCL version 1.2 or later)
- OpenCL driver (with kernel language support for OpenCL C 2.0 or later)
with Intel subgroups and USM extensions support
- DPCPP runtime requires
- Intel oneAPI DPC++ Compiler
- OpenCL runtime library (OpenCL version 1.2 or later)
- oneAPI Level Zero
- DPCPP runtime with NVIDIA GPU support requires
- oneAPI DPC++ Compiler
- OpenCL runtime library (OpenCL version 1.2 or later)
- NVIDIA CUDA* driver
- cuBLAS 10.1 or later
- cuDNN 7.6 or later
WARNING
NVIDIA GPU support is experimental. General information, build instructions
and implementation limitations is available in
NVIDIA backend readme.
Runtime Dependencies
When oneDNN is built from source, the library runtime dependencies
and specific versions are defined by the build environment.
Linux
Common dependencies:
- GNU C Library (
libc.so) - GNU Standard C++ Library v3 (
libstdc++.so) - Dynamic Linking Library (
libdl.so) - C Math Library (
libm.so) - POSIX Threads Library (
libpthread.so)
Runtime-specific dependencies:
| Runtime configuration | Compiler | Dependency |
|---|---|---|
DNNL_CPU_RUNTIME=OMP |
GCC | GNU OpenMP runtime (libgomp.so) |
DNNL_CPU_RUNTIME=OMP |
Intel C/C++ Compiler | Intel OpenMP runtime (libiomp5.so) |
DNNL_CPU_RUNTIME=OMP |
Clang | Intel OpenMP runtime (libiomp5.so) |
DNNL_CPU_RUNTIME=TBB |
any | TBB (libtbb.so) |
DNNL_CPU_RUNTIME=DPCPP |
Intel oneAPI DPC++ Compiler | Intel oneAPI DPC++ Compiler runtime (libsycl.so), TBB (libtbb.so), OpenCL loader (libOpenCL.so) |
DNNL_GPU_RUNTIME=OCL |
any | OpenCL loader (libOpenCL.so) |
DNNL_GPU_RUNTIME=DPCPP |
Intel oneAPI DPC++ Compiler | Intel oneAPI DPC++ Compiler runtime (libsycl.so), OpenCL loader (libOpenCL.so), oneAPI Level Zero loader (libze_loader.so) |
Windows
Common dependencies:
- Microsoft Visual C++ Redistributable (
msvcrt.dll)
Runtime-specific dependencies:
| Runtime configuration | Compiler | Dependency |
|---|---|---|
DNNL_CPU_RUNTIME=OMP |
Microsoft Visual C++ Compiler | No additional requirements |
DNNL_CPU_RUNTIME=OMP |
Intel C/C++ Compiler | Intel OpenMP runtime (iomp5.dll) |
DNNL_CPU_RUNTIME=TBB |
any | TBB (tbb.dll) |
DNNL_CPU_RUNTIME=DPCPP |
Intel oneAPI DPC++ Compiler | Intel oneAPI DPC++ Compiler runtime (sycl.dll), TBB (tbb.dll), OpenCL loader (OpenCL.dll) |
DNNL_GPU_RUNTIME=OCL |
any | OpenCL loader (OpenCL.dll) |
DNNL_GPU_RUNTIME=DPCPP |
Intel oneAPI DPC++ Compiler | Intel oneAPI DPC++ Compiler runtime (sycl.dll), OpenCL loader (OpenCL.dll), oneAPI Level Zero loader (ze_loader.dll) |
macOS
Common dependencies:
- System C/C++ runtime (
libc++.dylib,libSystem.dylib)
Runtime-specific dependencies:
| Runtime configuration | Compiler | Dependency |
|---|---|---|
DNNL_CPU_RUNTIME=OMP |
Intel C/C++ Compiler | Intel OpenMP runtime (libiomp5.dylib) |
DNNL_CPU_RUNTIME=TBB |
any | TBB (libtbb.dylib) |
Validated Configurations
CPU engine was validated on RedHat* Enterprise Linux 7 with
- GNU Compiler Collection 4.8, 5.4, 6.1, 7.2, 8.1, and 9.1
- Clang* 3.8.1, 7.1, 8.0, and 9.0
- Intel C/C++ Compiler
19.1 - Intel oneAPI DPC++ Compiler 2021.1
on Windows Server* 2016 with
- Microsoft Visual Studio 2015, 2017, and 2019
- Intel C/C++ Compiler
19.1 - Intel oneAPI DPC++ Compiler 2021.1
on macOS 10.13 (High Sierra) with
- Apple LLVM version 9.1
- Intel C/C++ Compiler
19.1
GPU engine was validated on Ubuntu* 20.04 with
- GNU Compiler Collection 7.2, 8.1, and 9.1
- Clang 3.8.1, 7.1, 8.0, and 9.0
- Intel C/C++ Compiler
19.1 - Intel oneAPI DPC++ Compiler 2021.1
- Intel Software for General Purpose GPU capabilities
latest stable version available at the time of release
on Windows Server 2019 with
- Microsoft Visual Studio 2015, 2017, and 2019
- Intel C/C++ Compiler
19.1 - Intel oneAPI DPC++ Compiler 2021.1
- Intel Graphics - Windows 10 DCH Drivers
latest stable version available at the time of release
Requirements for Pre-built Binaries
See the README included in the corresponding binary package.
Applications Enabled with oneDNN
- Apache* MXNet
- Apache* SINGA
- DeepLearning4J*
- Flashlight*
- Korali
- MATLAB* Deep Learning Toolbox
- ONNX Runtime
- OpenVINO(TM) toolkit
- PaddlePaddle*
- PyTorch*
- Tensorflow*
Support
Please submit your questions, feature requests, and bug reports on the
GitHub issues page.
You may reach out to project maintainers privately
at dnnl.maintainers@intel.com.
WARNING
This is pre-production software and functionality may change without prior
notice.
Contributing
We welcome community contributions to oneDNN. If you have an idea on how
to improve the library:
- For changes impacting the public API or library overall, such as adding new
primitives or changes to the architecture, submit an
RFC pull request. - Ensure that the changes are consistent with the
code contribution guidelines
and coding standards. - Ensure that you can build the product and run all the examples with your
patch. - Submit a pull request.
For additional details, see contribution guidelines.
This project is intended to be a safe, welcoming space for collaboration, and
contributors are expected to adhere to the
Contributor Covenant code of conduct.
License
oneDNN is licensed under Apache License Version 2.0. Refer to the
"LICENSE" file for the full license text and copyright notice.
This distribution includes third party software governed by separate license
terms.
3-clause BSD license:
2-clause BSD license:
Apache License Version 2.0:
Boost Software License, Version 1.0:
MIT License:
- Intel Graphics Compute Runtime for oneAPI Level Zero and OpenCL Driver
- Intel Graphics Compiler
- Doxyrest
This third party software, even if included with the distribution of
the Intel software, may be governed by separate license terms, including
without limitation, third party license terms, other Intel software license
terms, and open source software license terms. These separate license terms
govern your use of the third party programs as set forth in the
"THIRD-PARTY-PROGRAMS" file.
Security
See Intel's Security Center
for information on how to report a potential security issue or vulnerability.
See also: Security Policy
Trademark Information
Intel, the Intel logo, Intel Atom, Intel Core, Intel Xeon Phi, Iris, OpenVINO,
the OpenVINO logo, Pentium, VTune, and Xeon are trademarks
of Intel Corporation or its subsidiaries.
* Other names and brands may be claimed as the property of others.
Microsoft, Windows, and the Windows logo are trademarks, or registered
trademarks of Microsoft Corporation in the United States and/or other
countries.
OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission
by Khronos.
(C) Intel Corporation
Building and Linking
Build from Source
- Download the Source Code
- Download oneDNN source code or clone the repository.
git clone https://github.com/oneapi-src/oneDNN.git
Build the Library
- Ensure that all software dependencies are in place and have at least the minimal supported version.
- The oneDNN build system is based on CMake.
- Use
CMAKE_INSTALL_PREFIXto control the library installation location, CMAKE_BUILD_TYPEto select between build type (Release, Debug, RelWithDebInfo).CMAKE_PREFIX_PATHto specify directories to be searched for the dependencies located at non-standard locations.- See Build Options for detailed description of build-time configuration options.
Linux/macOS
- GCC, Clang, or Intel C/C++ Compiler
- Set up the environment for the compiler
- Configure CMake and generate makefiles
- 脚本中mkdir 与 mkdir -p 的区别
mkdir -p build
cd build
# Uncomment the following lines to build with Clang
# export CC=clang
# export CXX=clang++
# Uncomment the following lines to build with Intel C/C++ Compiler
# export CC=icc
# export CXX=icpc
cmake .. <extra build options>
- Build the library
make -j
- 就他妈的编译出来了
[100%] Linking CXX executable benchdnn
[100%] Built target benchdnn
Validate the Build¶
- If the library is built for the host system, you can run unit tests using:
ctest
Install library
- Install the library, headers, and documentation
cmake --build . --target install
- The install directory is specified by the
CMAKE_INSTALL_PREFIXcmake variable. - When installing in the default directory,
- the above command needs to be run with administrative privileges using sudo on Linux/Mac or a command prompt run as administrator on Windows.
- 我执行了之后就出来下面这样的东西了
[ 29%] Built target dnnl_cpu_x64
[ 35%] Built target dnnl_common
[ 48%] Built target dnnl_cpu
[ 49%] Built target dnnl
[ 49%] Built target compat_libs.2.3
[ 49%] Built target compat_libs.2
[ 49%] Built target compat_libs
[ 50%] Built target cnn-inference-f32-c
[ 51%] Built target tutorials-matmul-inference-int8-matmul-cpp
[ 51%] Built target cpu-tutorials-matmul-sgemm-and-matmul-cpp
[ 51%] Built target cpu-tutorials-matmul-matmul-quantization-cpp
[ 51%] Built target rnn-training-f32-cpp
[ 52%] Built target primitives-softmax-cpp
[ 52%] Built target primitives-shuffle-cpp
[ 52%] Built target primitives-resampling-cpp
[ 53%] Built target primitives-reduction-cpp
[ 53%] Built target primitives-prelu-cpp
[ 53%] Built target memory-format-propagation-cpp
[ 53%] Built target primitives-reorder-cpp
[ 53%] Built target primitives-binary-cpp
[ 53%] Built target cpu-cnn-training-f32-c
[ 53%] Built target bnorm-u8-via-binary-postops-cpp
[ 53%] Built target primitives-inner-product-cpp
[ 53%] Built target cnn-training-f32-cpp
[ 54%] Built target cnn-training-bf16-cpp
[ 54%] Built target cnn-inference-int8-cpp
[ 54%] Built target getting-started-cpp
[ 54%] Built target primitives-eltwise-cpp
[ 54%] Built target primitives-batch-normalization-cpp
[ 54%] Built target primitives-convolution-cpp
[ 54%] Built target cpu-rnn-inference-int8-cpp
[ 55%] Built target primitives-layer-normalization-cpp
[ 55%] Built target performance-profiling-cpp
[ 55%] Built target primitives-logsoftmax-cpp
[ 55%] Built target primitives-lrn-cpp
[ 56%] Built target primitives-concat-cpp
[ 57%] Built target primitives-lstm-cpp
[ 57%] Built target primitives-sum-cpp
[ 57%] Built target cnn-inference-f32-cpp
[ 57%] Built target primitives-matmul-cpp
[ 58%] Built target cpu-rnn-inference-f32-cpp
[ 58%] Built target primitives-pooling-cpp
[ 58%] Built target api-c
[ 58%] Built target test_c_symbols-c
[ 58%] Built target dnnl_gtest
[ 58%] Built target test_brgemm
[ 59%] Built target test_isa_iface
[ 59%] Built target test_isa_hints
[ 59%] Built target test_isa_mask
[ 60%] Built target test_global_scratchpad
[ 60%] Built target test_convolution_format_any
[ 60%] Built target test_gemm_u8u8s32
[ 60%] Built target test_gemm_s8u8s32
[ 61%] Built target test_gemm_u8s8s32
[ 61%] Built target test_gemm_bf16bf16f32
[ 61%] Built target test_gemm_f16f16f32
[ 62%] Built target test_softmax
[ 63%] Built target test_iface_primitive_cache
[ 63%] Built target test_concat
[ 64%] Built target test_logsoftmax
[ 65%] Built target test_cross_engine_reorder
[ 65%] Built target test_lrn_backward
[ 66%] Built target test_iface_runtime_dims
[ 66%] Built target test_matmul
[ 66%] Built target test_sum
[ 66%] Built target test_convolution_forward_u8s8s32
[ 67%] Built target test_convolution_backward_weights_f32
[ 67%] Built target test_convolution_backward_data_f32
[ 67%] Built target test_iface_wino_convolution
[ 67%] Built target test_iface_pd
[ 68%] Built target test_iface_handle
[ 68%] Built target test_gemm_bf16bf16bf16
[ 68%] Built target test_primitive_cache_mt
[ 68%] Built target test_reorder
[ 69%] Built target test_eltwise
[ 69%] Built target test_deconvolution
[ 69%] Built target test_batch_normalization_s8
[ 69%] Built target test_iface_pd_iter
[ 70%] Built target test_comparison_operators
[ 70%] Built target test_iface_attr
[ 71%] Built target test_pooling_forward
[ 72%] Built target test_inner_product_backward_data
[ 72%] Built target test_dnnl_threading
[ 72%] Built target test_iface_binary_bcast
[ 73%] Built target test_convolution_eltwise_forward_x8s8f32s32
[ 73%] Built target test_iface_weights_format
[ 73%] Built target test_iface_runtime_attr
[ 73%] Built target test_pooling_backward
[ 74%] Built target test_binary
[ 75%] Built target test_gemm_f16
[ 76%] Built target test_batch_normalization_f32
[ 77%] Built target test_lrn_forward
[ 78%] Built target test_inner_product_forward
[ 79%] Built target test_convolution_forward_u8s8fp
[ 79%] Built target test_inner_product_backward_weights
[ 79%] Built target test_shuffle
[ 79%] Built target test_gemm_s8s8s32
[ 79%] Built target test_convolution_forward_f32
[ 79%] Built target test_rnn_forward
[ 79%] Built target test_convolution_eltwise_forward_f32
[ 80%] Built target test_gemm_f32
[ 80%] Built target test_layer_normalization
[ 81%] Built target test_reduction
[ 82%] Built target test_resampling
[ 83%] Built target test_api
[ 83%] Built target test_internals
[ 83%] Built target test_regression
[ 96%] Built target benchdnn
[ 96%] Built target mkldnn-compat-cpu-cnn-training-f32-c
[ 97%] Built target mkldnn-compat-cnn-inference-f32-c
[ 97%] Built target mkldnn-compat-cpu-memory-format-propagation-cpp
[ 98%] Built target mkldnn-compat-cpu-rnn-inference-int8-cpp
[ 98%] Built target mkldnn-compat-cnn-training-f32-cpp
[ 98%] Built target mkldnn-compat-cnn-inference-int8-cpp
[ 98%] Built target mkldnn-compat-cnn-inference-f32-cpp
[ 99%] Built target mkldnn-compat-cpu-cnn-training-bf16-cpp
[ 99%] Built target mkldnn-compat-cpu-rnn-inference-f32-cpp
[ 99%] Built target mkldnn-compat-getting-started-cpp
[ 99%] Built target mkldnn-compat-performance-profiling-cpp
[ 99%] Built target mkldnn-compat-rnn-training-f32-cpp
[100%] Built target noexcept-cpp
Install the project...
-- Install configuration: "Release"
-- Installing: /usr/local/share/doc/dnnl/LICENSE
-- Installing: /usr/local/share/doc/dnnl/THIRD-PARTY-PROGRAMS
-- Installing: /usr/local/share/doc/dnnl/README
-- Installing: /usr/local/lib/libdnnl.so.2.3
-- Installing: /usr/local/lib/libdnnl.so.2
-- Installing: /usr/local/lib/libdnnl.so
-- Installing: /usr/local/include/dnnl.h
-- Installing: /usr/local/include/dnnl_config.h
-- Installing: /usr/local/include/dnnl_debug.h
-- Installing: /usr/local/include/dnnl_ocl.h
-- Installing: /usr/local/include/dnnl_sycl.h
-- Installing: /usr/local/include/dnnl_sycl_types.h
-- Installing: /usr/local/include/dnnl_threadpool.h
-- Installing: /usr/local/include/dnnl_types.h
-- Installing: /usr/local/include/dnnl_version.h
-- Installing: /usr/local/include/mkldnn.h
-- Installing: /usr/local/include/mkldnn_config.h
-- Installing: /usr/local/include/mkldnn_debug.h
-- Installing: /usr/local/include/mkldnn_dnnl_mangling.h
-- Installing: /usr/local/include/mkldnn_types.h
-- Installing: /usr/local/include/mkldnn_version.h
-- Installing: /usr/local/include/dnnl.hpp
-- Installing: /usr/local/include/dnnl_ocl.hpp
-- Installing: /usr/local/include/dnnl_sycl.hpp
-- Installing: /usr/local/include/dnnl_threadpool.hpp
-- Installing: /usr/local/include/dnnl_threadpool_iface.hpp
-- Installing: /usr/local/include/mkldnn.hpp
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_config.h
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_version.h
-- Installing: /usr/local/include/oneapi/dnnl/dnnl.h
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_debug.h
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_ocl.h
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_ocl_types.h
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_sycl.h
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_sycl_types.h
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_threadpool.h
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_types.h
-- Installing: /usr/local/include/oneapi/dnnl/dnnl.hpp
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_ocl.hpp
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_sycl.hpp
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_threadpool.hpp
-- Installing: /usr/local/include/oneapi/dnnl/dnnl_threadpool_iface.hpp
-- Installing: /usr/local/lib/cmake/dnnl/dnnl-config.cmake
-- Installing: /usr/local/lib/cmake/dnnl/dnnl-config-version.cmake
-- Installing: /usr/local/lib/cmake/dnnl/dnnl-targets.cmake
-- Installing: /usr/local/lib/cmake/dnnl/dnnl-targets-release.cmake
-- Installing: /usr/local/lib/libmkldnn.so
-- Installing: /usr/local/lib/libmkldnn.so.2
-- Installing: /usr/local/lib/libmkldnn.so.2.3
Linking to the Library
- 去这里复制A.cc 的内容吧!
- g++ A.cc -std=c++11 -L /usr/local/lib -ldnnl
- export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
- 然后就他妈的可以执行./a.out啦!
CNN f32 inference example
- how to build an AlexNet neural network topology for forward-pass inference.
- Some key take-aways include:
- How tensors are implemented and submitted to primitives.
- How primitives are created.
- How primitives are sequentially submitted to the network,
- where the output from primitives is passed as input to the next primitive.
- The latter specifies a dependency between the primitive input and output data.
- Specific ‘inference-only’ configurations.
- Limiting the number of reorders performed that are detrimental to performance.
- The example implements the AlexNet layers as numbered primitives (for example, conv1, pool1, conv2).
- Initialize an engine and stream. The last parameter in the call represents the index of the engine.
engine eng(engine_kind, 0);
stream s(eng);
- Create a vector for the primitives and a vector to hold memory that will be used as arguments.
std::vector<primitive> net;
std::vector<std::unordered_map<int, memory>> net_args;
- Allocate buffers for input and output data, weights, and bias.
std::vector<float> user_src(batch * 3 * 227 * 227);
std::vector<float> user_dst(batch * 1000);
std::vector<float> conv1_weights(product(conv1_weights_tz));
std::vector<float> conv1_bias(product(conv1_bias_tz));
- Create memory that describes data layout in the buffers.
- This example uses
tag::nchwfor input data andtag::oihwfor weights.
auto user_src_memory = memory({{conv1_src_tz}, dt::f32, tag::nchw}, eng);
write_to_dnnl_memory(user_src.data(), user_src_memory);
auto user_weights_memory
= memory({{conv1_weights_tz}, dt::f32, tag::oihw}, eng);
write_to_dnnl_memory(conv1_weights.data(), user_weights_memory);
auto conv1_user_bias_memory
= memory({{conv1_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(conv1_bias.data(), conv1_user_bias_memory);
- Create memory descriptors with layout
tag::any. - The any format enables the convolution primitive to choose the data format that will result in best performance based on its input parameters (convolution kernel sizes, strides, padding, and so on).
- If the resulting format is different from nchw, the user data must be transformed to the format required for the convolution (as explained below).
auto conv1_src_md = memory::desc({conv1_src_tz}, dt::f32, tag::any);
auto conv1_bias_md = memory::desc({conv1_bias_tz}, dt::f32, tag::any);
auto conv1_weights_md = memory::desc({conv1_weights_tz}, dt::f32, tag::any);
auto conv1_dst_md = memory::desc({conv1_dst_tz}, dt::f32, tag::any);
- Create a convolution descriptor by specifying
propagation kind,convolution algorithm,shapes of input,weights,bias,output,convolution strides,padding,and kind of padding. - Propagation kind is set to
prop_kind::forward_inferenceto optimize for inference execution and omit computations that are necessary only for backward propagation.
auto conv1_desc = convolution_forward::desc(prop_kind::forward_inference,
algorithm::convolution_direct, conv1_src_md, conv1_weights_md,
conv1_bias_md, conv1_dst_md, conv1_strides, conv1_padding,
conv1_padding);
- Create a convolution primitive descriptor.
- Once created, this descriptor has specific formats instead of the any format specified in the convolution descriptor.
auto conv1_prim_desc = convolution_forward::primitive_desc(conv1_desc, eng);
单个卷积和例子
#include <assert.h>
#include <chrono>
#include <vector>
#include <unordered_map>
#include "oneapi/dnnl/dnnl.hpp"
#include "../examples/example_utils.hpp"
using namespace dnnl;
void simple_net(engine::kind engine_kind, int times = 100) {
using tag = memory::format_tag;
using dt = memory::data_type;
//[Initialize engine and stream]
engine eng(engine_kind, 0);
stream s(eng);
//[Initialize engine and stream]
//[Create network]
std::vector<primitive> net;
std::vector<std::unordered_map<int, memory>> net_args;
//[Create network]
const memory::dim batch = 1;
// {batch, 3, 224, 224} (x) {32, 3, 3, 3} -> {batch, 32, 112, 112}
// strides: {2, 2}
memory::dims conv1_src_tz = {batch, 3, 224, 224};
memory::dims conv1_weights_tz = {32, 3, 3, 3};
memory::dims conv1_bias_tz = {32};
memory::dims conv1_dst_tz = {batch, 32, 112, 112};
memory::dims conv1_strides = {2, 2};
memory::dims conv1_padding = {1, 1};
//[Allocate buffers]
std::vector<float> user_src(batch * 3 * 224 * 224);
std::vector<float> conv1_weights(product(conv1_weights_tz));
std::vector<float> conv1_bias(product(conv1_bias_tz));
//[Allocate buffers]
//[Create user memory]
auto user_src_memory = memory({{conv1_src_tz}, dt::f32, tag::nchw}, eng);
write_to_dnnl_memory(user_src.data(), user_src_memory);
auto user_weights_memory
= memory({{conv1_weights_tz}, dt::f32, tag::oihw}, eng);
write_to_dnnl_memory(conv1_weights.data(), user_weights_memory);
auto conv1_user_bias_memory
= memory({{conv1_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(conv1_bias.data(), conv1_user_bias_memory);
//[Create user memory]
//[Create convolution memory descriptors]
auto conv1_src_md = memory::desc({conv1_src_tz}, dt::f32, tag::any);
auto conv1_bias_md = memory::desc({conv1_bias_tz}, dt::f32, tag::any);
auto conv1_weights_md = memory::desc({conv1_weights_tz}, dt::f32, tag::any);
auto conv1_dst_md = memory::desc({conv1_dst_tz}, dt::f32, tag::any);
//[Create convolution memory descriptors]
//[Create convolution descriptor]
auto conv1_desc = convolution_forward::desc(prop_kind::forward_inference,
algorithm::convolution_auto, conv1_src_md, conv1_weights_md,
conv1_bias_md, conv1_dst_md, conv1_strides, conv1_padding,
conv1_padding);
//[Create convolution descriptor]
//[Create convolution primitive descriptor]
auto conv1_prim_desc = convolution_forward::primitive_desc(conv1_desc, eng);
//[Create convolution primitive descriptor]
//[Reorder data and weights]
auto conv1_src_memory = user_src_memory;
if (conv1_prim_desc.src_desc() != user_src_memory.get_desc()) {
conv1_src_memory = memory(conv1_prim_desc.src_desc(), eng);
net.push_back(reorder(user_src_memory, conv1_src_memory));
net_args.push_back({{DNNL_ARG_FROM, user_src_memory},
{DNNL_ARG_TO, conv1_src_memory}});
}
auto conv1_weights_memory = user_weights_memory;
if (conv1_prim_desc.weights_desc() != user_weights_memory.get_desc()) {
conv1_weights_memory = memory(conv1_prim_desc.weights_desc(), eng);
reorder(user_weights_memory, conv1_weights_memory)
.execute(s, user_weights_memory, conv1_weights_memory);
}
//[Reorder data and weights]
//[Create memory for output]
auto conv1_dst_memory = memory(conv1_prim_desc.dst_desc(), eng);
//[Create memory for output]
//[Create convolution primitive]
net.push_back(convolution_forward(conv1_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv1_src_memory},
{DNNL_ARG_WEIGHTS, conv1_weights_memory},
{DNNL_ARG_BIAS, conv1_user_bias_memory},
{DNNL_ARG_DST, conv1_dst_memory}});
//[Create convolution primitive]
//[Execute model]
for (int j = 0; j < times; ++j) {
assert(net.size() == net_args.size() && "something is missing");
for (size_t i = 0; i < net.size(); ++i)
net.at(i).execute(s, net_args.at(i));
}
//[Execute model]
s.wait();
std::vector<float> output(batch * 32 * 112 * 112);
read_from_dnnl_memory(output.data(), conv1_dst_memory);
}
void cnn_inference_f32(engine::kind engine_kind) {
auto begin = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::steady_clock::now().time_since_epoch())
.count();
int times = 1000;
simple_net(engine_kind, times);
auto end = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::steady_clock::now().time_since_epoch())
.count();
std::cout << "Use time: " << (end - begin) / (times + 0.0)
<< " ms per iteration." << std::endl;
}
int main(int argc, char **argv) {
return handle_example_errors(
cnn_inference_f32, parse_engine_kind(argc, argv));
}
Alex 大例子
- 文档中给了一个CNN f32 inference example
- 下文搭建了一个AlexNet网络。
#include <assert.h>
#include <chrono>
#include <vector>
#include <unordered_map>
#include "oneapi/dnnl/dnnl.hpp"
#include "../examples/example_utils.hpp"
using namespace dnnl;
void simple_net(engine::kind engine_kind, int times = 100) {
using tag = memory::format_tag;
using dt = memory::data_type;
//[Initialize engine and stream]
engine eng(engine_kind, 0);
stream s(eng);
//[Initialize engine and stream]
//[Create network]
std::vector<primitive> net;
std::vector<std::unordered_map<int, memory>> net_args;
//[Create network]
const memory::dim batch = 1;
// AlexNet: conv1
// {batch, 3, 227, 227} (x) {96, 3, 11, 11} -> {batch, 96, 55, 55}
// strides: {4, 4}
memory::dims conv1_src_tz = {batch, 3, 227, 227};
memory::dims conv1_weights_tz = {96, 3, 11, 11};
memory::dims conv1_bias_tz = {96};
memory::dims conv1_dst_tz = {batch, 96, 55, 55};
memory::dims conv1_strides = {4, 4};
memory::dims conv1_padding = {0, 0};
//[Allocate buffers]
std::vector<float> user_src(batch * 3 * 227 * 227);
std::vector<float> user_dst(batch * 1000);
std::vector<float> conv1_weights(product(conv1_weights_tz));
std::vector<float> conv1_bias(product(conv1_bias_tz));
//[Allocate buffers]
//[Create user memory]
auto user_src_memory = memory({{conv1_src_tz}, dt::f32, tag::nchw}, eng);
write_to_dnnl_memory(user_src.data(), user_src_memory);
auto user_weights_memory
= memory({{conv1_weights_tz}, dt::f32, tag::oihw}, eng);
write_to_dnnl_memory(conv1_weights.data(), user_weights_memory);
auto conv1_user_bias_memory
= memory({{conv1_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(conv1_bias.data(), conv1_user_bias_memory);
//[Create user memory]
//[Create convolution memory descriptors]
auto conv1_src_md = memory::desc({conv1_src_tz}, dt::f32, tag::any);
auto conv1_bias_md = memory::desc({conv1_bias_tz}, dt::f32, tag::any);
auto conv1_weights_md = memory::desc({conv1_weights_tz}, dt::f32, tag::any);
auto conv1_dst_md = memory::desc({conv1_dst_tz}, dt::f32, tag::any);
//[Create convolution memory descriptors]
//[Create convolution descriptor]
auto conv1_desc = convolution_forward::desc(prop_kind::forward_inference,
algorithm::convolution_direct, conv1_src_md, conv1_weights_md,
conv1_bias_md, conv1_dst_md, conv1_strides, conv1_padding,
conv1_padding);
//[Create convolution descriptor]
//[Create convolution primitive descriptor]
auto conv1_prim_desc = convolution_forward::primitive_desc(conv1_desc, eng);
//[Create convolution primitive descriptor]
//[Reorder data and weights]
auto conv1_src_memory = user_src_memory;
if (conv1_prim_desc.src_desc() != user_src_memory.get_desc()) {
conv1_src_memory = memory(conv1_prim_desc.src_desc(), eng);
net.push_back(reorder(user_src_memory, conv1_src_memory));
net_args.push_back({{DNNL_ARG_FROM, user_src_memory},
{DNNL_ARG_TO, conv1_src_memory}});
}
auto conv1_weights_memory = user_weights_memory;
if (conv1_prim_desc.weights_desc() != user_weights_memory.get_desc()) {
conv1_weights_memory = memory(conv1_prim_desc.weights_desc(), eng);
reorder(user_weights_memory, conv1_weights_memory)
.execute(s, user_weights_memory, conv1_weights_memory);
}
//[Reorder data and weights]
//[Create memory for output]
auto conv1_dst_memory = memory(conv1_prim_desc.dst_desc(), eng);
//[Create memory for output]
//[Create convolution primitive]
net.push_back(convolution_forward(conv1_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv1_src_memory},
{DNNL_ARG_WEIGHTS, conv1_weights_memory},
{DNNL_ARG_BIAS, conv1_user_bias_memory},
{DNNL_ARG_DST, conv1_dst_memory}});
//[Create convolution primitive]
// AlexNet: relu1
// {batch, 96, 55, 55} -> {batch, 96, 55, 55}
const float negative1_slope = 0.0f;
//[Create relu primitive]
auto relu1_desc = eltwise_forward::desc(prop_kind::forward_inference,
algorithm::eltwise_relu, conv1_dst_memory.get_desc(),
negative1_slope);
auto relu1_prim_desc = eltwise_forward::primitive_desc(relu1_desc, eng);
net.push_back(eltwise_forward(relu1_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv1_dst_memory},
{DNNL_ARG_DST, conv1_dst_memory}});
//[Create relu primitive]
// AlexNet: lrn1
// {batch, 96, 55, 55} -> {batch, 96, 55, 55}
// local size: 5
// alpha1: 0.0001
// beta1: 0.75
const memory::dim local1_size = 5;
const float alpha1 = 0.0001f;
const float beta1 = 0.75f;
const float k1 = 1.0f;
// create lrn primitive and add it to net
auto lrn1_desc = lrn_forward::desc(prop_kind::forward_inference,
algorithm::lrn_across_channels, conv1_dst_memory.get_desc(),
local1_size, alpha1, beta1, k1);
auto lrn1_prim_desc = lrn_forward::primitive_desc(lrn1_desc, eng);
auto lrn1_dst_memory = memory(lrn1_prim_desc.dst_desc(), eng);
net.push_back(lrn_forward(lrn1_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv1_dst_memory},
{DNNL_ARG_DST, lrn1_dst_memory}});
// AlexNet: pool1
// {batch, 96, 55, 55} -> {batch, 96, 27, 27}
// kernel: {3, 3}
// strides: {2, 2}
memory::dims pool1_dst_tz = {batch, 96, 27, 27};
memory::dims pool1_kernel = {3, 3};
memory::dims pool1_strides = {2, 2};
memory::dims pool_padding = {0, 0};
auto pool1_dst_md = memory::desc({pool1_dst_tz}, dt::f32, tag::any);
//[Create pooling primitive]
auto pool1_desc = pooling_forward::desc(prop_kind::forward_inference,
algorithm::pooling_max, lrn1_dst_memory.get_desc(), pool1_dst_md,
pool1_strides, pool1_kernel, pool_padding, pool_padding);
auto pool1_pd = pooling_forward::primitive_desc(pool1_desc, eng);
auto pool1_dst_memory = memory(pool1_pd.dst_desc(), eng);
net.push_back(pooling_forward(pool1_pd));
net_args.push_back({{DNNL_ARG_SRC, lrn1_dst_memory},
{DNNL_ARG_DST, pool1_dst_memory}});
//[Create pooling primitive]
// AlexNet: conv2
// {batch, 96, 27, 27} (x) {2, 128, 48, 5, 5} -> {batch, 256, 27, 27}
// strides: {1, 1}
memory::dims conv2_src_tz = {batch, 96, 27, 27};
memory::dims conv2_weights_tz = {2, 128, 48, 5, 5};
memory::dims conv2_bias_tz = {256};
memory::dims conv2_dst_tz = {batch, 256, 27, 27};
memory::dims conv2_strides = {1, 1};
memory::dims conv2_padding = {2, 2};
std::vector<float> conv2_weights(product(conv2_weights_tz));
std::vector<float> conv2_bias(product(conv2_bias_tz));
// create memory for user data
auto conv2_user_weights_memory
= memory({{conv2_weights_tz}, dt::f32, tag::goihw}, eng);
write_to_dnnl_memory(conv2_weights.data(), conv2_user_weights_memory);
auto conv2_user_bias_memory
= memory({{conv2_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(conv2_bias.data(), conv2_user_bias_memory);
// create memory descriptors for convolution data w/ no specified format
auto conv2_src_md = memory::desc({conv2_src_tz}, dt::f32, tag::any);
auto conv2_bias_md = memory::desc({conv2_bias_tz}, dt::f32, tag::any);
auto conv2_weights_md = memory::desc({conv2_weights_tz}, dt::f32, tag::any);
auto conv2_dst_md = memory::desc({conv2_dst_tz}, dt::f32, tag::any);
// create a convolution
auto conv2_desc = convolution_forward::desc(prop_kind::forward_inference,
algorithm::convolution_direct, conv2_src_md, conv2_weights_md,
conv2_bias_md, conv2_dst_md, conv2_strides, conv2_padding,
conv2_padding);
auto conv2_prim_desc = convolution_forward::primitive_desc(conv2_desc, eng);
auto conv2_src_memory = pool1_dst_memory;
if (conv2_prim_desc.src_desc() != conv2_src_memory.get_desc()) {
conv2_src_memory = memory(conv2_prim_desc.src_desc(), eng);
net.push_back(reorder(pool1_dst_memory, conv2_src_memory));
net_args.push_back({{DNNL_ARG_FROM, pool1_dst_memory},
{DNNL_ARG_TO, conv2_src_memory}});
}
auto conv2_weights_memory = conv2_user_weights_memory;
if (conv2_prim_desc.weights_desc()
!= conv2_user_weights_memory.get_desc()) {
conv2_weights_memory = memory(conv2_prim_desc.weights_desc(), eng);
reorder(conv2_user_weights_memory, conv2_weights_memory)
.execute(s, conv2_user_weights_memory, conv2_weights_memory);
}
auto conv2_dst_memory = memory(conv2_prim_desc.dst_desc(), eng);
// create convolution primitive and add it to net
net.push_back(convolution_forward(conv2_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv2_src_memory},
{DNNL_ARG_WEIGHTS, conv2_weights_memory},
{DNNL_ARG_BIAS, conv2_user_bias_memory},
{DNNL_ARG_DST, conv2_dst_memory}});
// AlexNet: relu2
// {batch, 256, 27, 27} -> {batch, 256, 27, 27}
const float negative2_slope = 0.0f;
// create relu primitive and add it to net
auto relu2_desc = eltwise_forward::desc(prop_kind::forward_inference,
algorithm::eltwise_relu, conv2_dst_memory.get_desc(),
negative2_slope);
auto relu2_prim_desc = eltwise_forward::primitive_desc(relu2_desc, eng);
net.push_back(eltwise_forward(relu2_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv2_dst_memory},
{DNNL_ARG_DST, conv2_dst_memory}});
// AlexNet: lrn2
// {batch, 256, 27, 27} -> {batch, 256, 27, 27}
// local size: 5
// alpha2: 0.0001
// beta2: 0.75
const memory::dim local2_size = 5;
const float alpha2 = 0.0001f;
const float beta2 = 0.75f;
const float k2 = 1.0f;
// create lrn primitive and add it to net
auto lrn2_desc = lrn_forward::desc(prop_kind::forward_inference,
algorithm::lrn_across_channels, conv2_prim_desc.dst_desc(),
local2_size, alpha2, beta2, k2);
auto lrn2_prim_desc = lrn_forward::primitive_desc(lrn2_desc, eng);
auto lrn2_dst_memory = memory(lrn2_prim_desc.dst_desc(), eng);
net.push_back(lrn_forward(lrn2_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv2_dst_memory},
{DNNL_ARG_DST, lrn2_dst_memory}});
// AlexNet: pool2
// {batch, 256, 27, 27} -> {batch, 256, 13, 13}
// kernel: {3, 3}
// strides: {2, 2}
memory::dims pool2_dst_tz = {batch, 256, 13, 13};
memory::dims pool2_kernel = {3, 3};
memory::dims pool2_strides = {2, 2};
memory::dims pool2_padding = {0, 0};
auto pool2_dst_md = memory::desc({pool2_dst_tz}, dt::f32, tag::any);
// create a pooling
auto pool2_desc = pooling_forward::desc(prop_kind::forward_inference,
algorithm::pooling_max, lrn2_dst_memory.get_desc(), pool2_dst_md,
pool2_strides, pool2_kernel, pool2_padding, pool2_padding);
auto pool2_pd = pooling_forward::primitive_desc(pool2_desc, eng);
auto pool2_dst_memory = memory(pool2_pd.dst_desc(), eng);
// create pooling primitive an add it to net
net.push_back(pooling_forward(pool2_pd));
net_args.push_back({{DNNL_ARG_SRC, lrn2_dst_memory},
{DNNL_ARG_DST, pool2_dst_memory}});
// AlexNet: conv3
// {batch, 256, 13, 13} (x) {384, 256, 3, 3}; -> {batch, 384, 13, 13};
// strides: {1, 1}
memory::dims conv3_src_tz = {batch, 256, 13, 13};
memory::dims conv3_weights_tz = {384, 256, 3, 3};
memory::dims conv3_bias_tz = {384};
memory::dims conv3_dst_tz = {batch, 384, 13, 13};
memory::dims conv3_strides = {1, 1};
memory::dims conv3_padding = {1, 1};
std::vector<float> conv3_weights(product(conv3_weights_tz));
std::vector<float> conv3_bias(product(conv3_bias_tz));
// create memory for user data
auto conv3_user_weights_memory
= memory({{conv3_weights_tz}, dt::f32, tag::oihw}, eng);
write_to_dnnl_memory(conv3_weights.data(), conv3_user_weights_memory);
auto conv3_user_bias_memory
= memory({{conv3_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(conv3_bias.data(), conv3_user_bias_memory);
// create memory descriptors for convolution data w/ no specified format
auto conv3_src_md = memory::desc({conv3_src_tz}, dt::f32, tag::any);
auto conv3_bias_md = memory::desc({conv3_bias_tz}, dt::f32, tag::any);
auto conv3_weights_md = memory::desc({conv3_weights_tz}, dt::f32, tag::any);
auto conv3_dst_md = memory::desc({conv3_dst_tz}, dt::f32, tag::any);
// create a convolution
auto conv3_desc = convolution_forward::desc(prop_kind::forward_inference,
algorithm::convolution_direct, conv3_src_md, conv3_weights_md,
conv3_bias_md, conv3_dst_md, conv3_strides, conv3_padding,
conv3_padding);
auto conv3_prim_desc = convolution_forward::primitive_desc(conv3_desc, eng);
auto conv3_src_memory = pool2_dst_memory;
if (conv3_prim_desc.src_desc() != conv3_src_memory.get_desc()) {
conv3_src_memory = memory(conv3_prim_desc.src_desc(), eng);
net.push_back(reorder(pool2_dst_memory, conv3_src_memory));
net_args.push_back({{DNNL_ARG_FROM, pool2_dst_memory},
{DNNL_ARG_TO, conv3_src_memory}});
}
auto conv3_weights_memory = conv3_user_weights_memory;
if (conv3_prim_desc.weights_desc()
!= conv3_user_weights_memory.get_desc()) {
conv3_weights_memory = memory(conv3_prim_desc.weights_desc(), eng);
reorder(conv3_user_weights_memory, conv3_weights_memory)
.execute(s, conv3_user_weights_memory, conv3_weights_memory);
}
auto conv3_dst_memory = memory(conv3_prim_desc.dst_desc(), eng);
// create convolution primitive and add it to net
net.push_back(convolution_forward(conv3_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv3_src_memory},
{DNNL_ARG_WEIGHTS, conv3_weights_memory},
{DNNL_ARG_BIAS, conv3_user_bias_memory},
{DNNL_ARG_DST, conv3_dst_memory}});
// AlexNet: relu3
// {batch, 384, 13, 13} -> {batch, 384, 13, 13}
const float negative3_slope = 0.0f;
// create relu primitive and add it to net
auto relu3_desc = eltwise_forward::desc(prop_kind::forward_inference,
algorithm::eltwise_relu, conv3_dst_memory.get_desc(),
negative3_slope);
auto relu3_prim_desc = eltwise_forward::primitive_desc(relu3_desc, eng);
net.push_back(eltwise_forward(relu3_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv3_dst_memory},
{DNNL_ARG_DST, conv3_dst_memory}});
// AlexNet: conv4
// {batch, 384, 13, 13} (x) {2, 192, 192, 3, 3}; ->
// {batch, 384, 13, 13};
// strides: {1, 1}
memory::dims conv4_src_tz = {batch, 384, 13, 13};
memory::dims conv4_weights_tz = {2, 192, 192, 3, 3};
memory::dims conv4_bias_tz = {384};
memory::dims conv4_dst_tz = {batch, 384, 13, 13};
memory::dims conv4_strides = {1, 1};
memory::dims conv4_padding = {1, 1};
std::vector<float> conv4_weights(product(conv4_weights_tz));
std::vector<float> conv4_bias(product(conv4_bias_tz));
// create memory for user data
auto conv4_user_weights_memory
= memory({{conv4_weights_tz}, dt::f32, tag::goihw}, eng);
write_to_dnnl_memory(conv4_weights.data(), conv4_user_weights_memory);
auto conv4_user_bias_memory
= memory({{conv4_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(conv4_bias.data(), conv4_user_bias_memory);
// create memory descriptors for convolution data w/ no specified format
auto conv4_src_md = memory::desc({conv4_src_tz}, dt::f32, tag::any);
auto conv4_bias_md = memory::desc({conv4_bias_tz}, dt::f32, tag::any);
auto conv4_weights_md = memory::desc({conv4_weights_tz}, dt::f32, tag::any);
auto conv4_dst_md = memory::desc({conv4_dst_tz}, dt::f32, tag::any);
// create a convolution
auto conv4_desc = convolution_forward::desc(prop_kind::forward_inference,
algorithm::convolution_direct, conv4_src_md, conv4_weights_md,
conv4_bias_md, conv4_dst_md, conv4_strides, conv4_padding,
conv4_padding);
auto conv4_prim_desc = convolution_forward::primitive_desc(conv4_desc, eng);
auto conv4_src_memory = conv3_dst_memory;
if (conv4_prim_desc.src_desc() != conv4_src_memory.get_desc()) {
conv4_src_memory = memory(conv4_prim_desc.src_desc(), eng);
net.push_back(reorder(conv3_dst_memory, conv4_src_memory));
net_args.push_back({{DNNL_ARG_FROM, conv3_dst_memory},
{DNNL_ARG_TO, conv4_src_memory}});
}
auto conv4_weights_memory = conv4_user_weights_memory;
if (conv4_prim_desc.weights_desc()
!= conv4_user_weights_memory.get_desc()) {
conv4_weights_memory = memory(conv4_prim_desc.weights_desc(), eng);
reorder(conv4_user_weights_memory, conv4_weights_memory)
.execute(s, conv4_user_weights_memory, conv4_weights_memory);
}
auto conv4_dst_memory = memory(conv4_prim_desc.dst_desc(), eng);
// create convolution primitive and add it to net
net.push_back(convolution_forward(conv4_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv4_src_memory},
{DNNL_ARG_WEIGHTS, conv4_weights_memory},
{DNNL_ARG_BIAS, conv4_user_bias_memory},
{DNNL_ARG_DST, conv4_dst_memory}});
// AlexNet: relu4
// {batch, 384, 13, 13} -> {batch, 384, 13, 13}
const float negative4_slope = 0.0f;
// create relu primitive and add it to net
auto relu4_desc = eltwise_forward::desc(prop_kind::forward_inference,
algorithm::eltwise_relu, conv4_dst_memory.get_desc(),
negative4_slope);
auto relu4_prim_desc = eltwise_forward::primitive_desc(relu4_desc, eng);
net.push_back(eltwise_forward(relu4_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv4_dst_memory},
{DNNL_ARG_DST, conv4_dst_memory}});
// AlexNet: conv5
// {batch, 384, 13, 13} (x) {2, 128, 192, 3, 3}; -> {batch, 256, 13, 13};
// strides: {1, 1}
memory::dims conv5_src_tz = {batch, 384, 13, 13};
memory::dims conv5_weights_tz = {2, 128, 192, 3, 3};
memory::dims conv5_bias_tz = {256};
memory::dims conv5_dst_tz = {batch, 256, 13, 13};
memory::dims conv5_strides = {1, 1};
memory::dims conv5_padding = {1, 1};
std::vector<float> conv5_weights(product(conv5_weights_tz));
std::vector<float> conv5_bias(product(conv5_bias_tz));
// create memory for user data
auto conv5_user_weights_memory
= memory({{conv5_weights_tz}, dt::f32, tag::goihw}, eng);
write_to_dnnl_memory(conv5_weights.data(), conv5_user_weights_memory);
auto conv5_user_bias_memory
= memory({{conv5_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(conv5_bias.data(), conv5_user_bias_memory);
// create memory descriptors for convolution data w/ no specified format
auto conv5_src_md = memory::desc({conv5_src_tz}, dt::f32, tag::any);
auto conv5_weights_md = memory::desc({conv5_weights_tz}, dt::f32, tag::any);
auto conv5_bias_md = memory::desc({conv5_bias_tz}, dt::f32, tag::any);
auto conv5_dst_md = memory::desc({conv5_dst_tz}, dt::f32, tag::any);
// create a convolution
auto conv5_desc = convolution_forward::desc(prop_kind::forward_inference,
algorithm::convolution_direct, conv5_src_md, conv5_weights_md,
conv5_bias_md, conv5_dst_md, conv5_strides, conv5_padding,
conv5_padding);
auto conv5_prim_desc = convolution_forward::primitive_desc(conv5_desc, eng);
auto conv5_src_memory = conv4_dst_memory;
if (conv5_prim_desc.src_desc() != conv5_src_memory.get_desc()) {
conv5_src_memory = memory(conv5_prim_desc.src_desc(), eng);
net.push_back(reorder(conv4_dst_memory, conv5_src_memory));
net_args.push_back({{DNNL_ARG_FROM, conv4_dst_memory},
{DNNL_ARG_TO, conv5_src_memory}});
}
auto conv5_weights_memory = conv5_user_weights_memory;
if (conv5_prim_desc.weights_desc()
!= conv5_user_weights_memory.get_desc()) {
conv5_weights_memory = memory(conv5_prim_desc.weights_desc(), eng);
reorder(conv5_user_weights_memory, conv5_weights_memory)
.execute(s, conv5_user_weights_memory, conv5_weights_memory);
}
auto conv5_dst_memory = memory(conv5_prim_desc.dst_desc(), eng);
// create convolution primitive and add it to net
net.push_back(convolution_forward(conv5_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv5_src_memory},
{DNNL_ARG_WEIGHTS, conv5_weights_memory},
{DNNL_ARG_BIAS, conv5_user_bias_memory},
{DNNL_ARG_DST, conv5_dst_memory}});
// AlexNet: relu5
// {batch, 256, 13, 13} -> {batch, 256, 13, 13}
const float negative5_slope = 0.0f;
// create relu primitive and add it to net
auto relu5_desc = eltwise_forward::desc(prop_kind::forward_inference,
algorithm::eltwise_relu, conv5_dst_memory.get_desc(),
negative5_slope);
auto relu5_prim_desc = eltwise_forward::primitive_desc(relu5_desc, eng);
net.push_back(eltwise_forward(relu5_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, conv5_dst_memory},
{DNNL_ARG_DST, conv5_dst_memory}});
// AlexNet: pool5
// {batch, 256, 13, 13} -> {batch, 256, 6, 6}
// kernel: {3, 3}
// strides: {2, 2}
memory::dims pool5_dst_tz = {batch, 256, 6, 6};
memory::dims pool5_kernel = {3, 3};
memory::dims pool5_strides = {2, 2};
memory::dims pool5_padding = {0, 0};
std::vector<float> pool5_dst(product(pool5_dst_tz));
auto pool5_dst_md = memory::desc({pool5_dst_tz}, dt::f32, tag::any);
// create a pooling
auto pool5_desc = pooling_forward::desc(prop_kind::forward_inference,
algorithm::pooling_max, conv5_dst_memory.get_desc(), pool5_dst_md,
pool5_strides, pool5_kernel, pool5_padding, pool5_padding);
auto pool5_pd = pooling_forward::primitive_desc(pool5_desc, eng);
auto pool5_dst_memory = memory(pool5_pd.dst_desc(), eng);
// create pooling primitive an add it to net
net.push_back(pooling_forward(pool5_pd));
net_args.push_back({{DNNL_ARG_SRC, conv5_dst_memory},
{DNNL_ARG_DST, pool5_dst_memory}});
// fc6 inner product {batch, 256, 6, 6} (x) {4096, 256, 6, 6}-> {batch,
// 4096}
memory::dims fc6_src_tz = {batch, 256, 6, 6};
memory::dims fc6_weights_tz = {4096, 256, 6, 6};
memory::dims fc6_bias_tz = {4096};
memory::dims fc6_dst_tz = {batch, 4096};
std::vector<float> fc6_weights(product(fc6_weights_tz));
std::vector<float> fc6_bias(product(fc6_bias_tz));
// create memory for user data
auto fc6_user_weights_memory
= memory({{fc6_weights_tz}, dt::f32, tag::oihw}, eng);
write_to_dnnl_memory(fc6_weights.data(), fc6_user_weights_memory);
auto fc6_user_bias_memory = memory({{fc6_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(fc6_bias.data(), fc6_user_bias_memory);
// create memory descriptors for convolution data w/ no specified format
auto fc6_src_md = memory::desc({fc6_src_tz}, dt::f32, tag::any);
auto fc6_bias_md = memory::desc({fc6_bias_tz}, dt::f32, tag::any);
auto fc6_weights_md = memory::desc({fc6_weights_tz}, dt::f32, tag::any);
auto fc6_dst_md = memory::desc({fc6_dst_tz}, dt::f32, tag::any);
// create a inner_product
auto fc6_desc = inner_product_forward::desc(prop_kind::forward_inference,
fc6_src_md, fc6_weights_md, fc6_bias_md, fc6_dst_md);
auto fc6_prim_desc = inner_product_forward::primitive_desc(fc6_desc, eng);
auto fc6_src_memory = pool5_dst_memory;
if (fc6_prim_desc.src_desc() != fc6_src_memory.get_desc()) {
fc6_src_memory = memory(fc6_prim_desc.src_desc(), eng);
net.push_back(reorder(pool5_dst_memory, fc6_src_memory));
net_args.push_back({{DNNL_ARG_FROM, pool5_dst_memory},
{DNNL_ARG_TO, fc6_src_memory}});
}
auto fc6_weights_memory = fc6_user_weights_memory;
if (fc6_prim_desc.weights_desc() != fc6_user_weights_memory.get_desc()) {
fc6_weights_memory = memory(fc6_prim_desc.weights_desc(), eng);
reorder(fc6_user_weights_memory, fc6_weights_memory)
.execute(s, fc6_user_weights_memory, fc6_weights_memory);
}
auto fc6_dst_memory = memory(fc6_prim_desc.dst_desc(), eng);
// create convolution primitive and add it to net
net.push_back(inner_product_forward(fc6_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, fc6_src_memory},
{DNNL_ARG_WEIGHTS, fc6_weights_memory},
{DNNL_ARG_BIAS, fc6_user_bias_memory},
{DNNL_ARG_DST, fc6_dst_memory}});
// fc7 inner product {batch, 4096} (x) {4096, 4096}-> {batch, 4096}
memory::dims fc7_weights_tz = {4096, 4096};
memory::dims fc7_bias_tz = {4096};
memory::dims fc7_dst_tz = {batch, 4096};
std::vector<float> fc7_weights(product(fc7_weights_tz));
std::vector<float> fc7_bias(product(fc7_bias_tz));
// create memory for user data
auto fc7_user_weights_memory
= memory({{fc7_weights_tz}, dt::f32, tag::nc}, eng);
write_to_dnnl_memory(fc7_weights.data(), fc7_user_weights_memory);
auto fc7_user_bias_memory = memory({{fc7_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(fc7_bias.data(), fc7_user_bias_memory);
// create memory descriptors for convolution data w/ no specified format
auto fc7_bias_md = memory::desc({fc7_bias_tz}, dt::f32, tag::any);
auto fc7_weights_md = memory::desc({fc7_weights_tz}, dt::f32, tag::any);
auto fc7_dst_md = memory::desc({fc7_dst_tz}, dt::f32, tag::any);
// create a inner_product
auto fc7_desc = inner_product_forward::desc(prop_kind::forward_inference,
fc6_dst_memory.get_desc(), fc7_weights_md, fc7_bias_md, fc7_dst_md);
auto fc7_prim_desc = inner_product_forward::primitive_desc(fc7_desc, eng);
auto fc7_weights_memory = fc7_user_weights_memory;
if (fc7_prim_desc.weights_desc() != fc7_user_weights_memory.get_desc()) {
fc7_weights_memory = memory(fc7_prim_desc.weights_desc(), eng);
reorder(fc7_user_weights_memory, fc7_weights_memory)
.execute(s, fc7_user_weights_memory, fc7_weights_memory);
}
auto fc7_dst_memory = memory(fc7_prim_desc.dst_desc(), eng);
// create convolution primitive and add it to net
net.push_back(inner_product_forward(fc7_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, fc6_dst_memory},
{DNNL_ARG_WEIGHTS, fc7_weights_memory},
{DNNL_ARG_BIAS, fc7_user_bias_memory},
{DNNL_ARG_DST, fc7_dst_memory}});
// fc8 inner product {batch, 4096} (x) {1000, 4096}-> {batch, 1000}
memory::dims fc8_weights_tz = {1000, 4096};
memory::dims fc8_bias_tz = {1000};
memory::dims fc8_dst_tz = {batch, 1000};
std::vector<float> fc8_weights(product(fc8_weights_tz));
std::vector<float> fc8_bias(product(fc8_bias_tz));
// create memory for user data
auto fc8_user_weights_memory
= memory({{fc8_weights_tz}, dt::f32, tag::nc}, eng);
write_to_dnnl_memory(fc8_weights.data(), fc8_user_weights_memory);
auto fc8_user_bias_memory = memory({{fc8_bias_tz}, dt::f32, tag::x}, eng);
write_to_dnnl_memory(fc8_bias.data(), fc8_user_bias_memory);
auto user_dst_memory = memory({{fc8_dst_tz}, dt::f32, tag::nc}, eng);
write_to_dnnl_memory(user_dst.data(), user_dst_memory);
// create memory descriptors for convolution data w/ no specified format
auto fc8_bias_md = memory::desc({fc8_bias_tz}, dt::f32, tag::any);
auto fc8_weights_md = memory::desc({fc8_weights_tz}, dt::f32, tag::any);
auto fc8_dst_md = memory::desc({fc8_dst_tz}, dt::f32, tag::any);
// create a inner_product
auto fc8_desc = inner_product_forward::desc(prop_kind::forward_inference,
fc7_dst_memory.get_desc(), fc8_weights_md, fc8_bias_md, fc8_dst_md);
auto fc8_prim_desc = inner_product_forward::primitive_desc(fc8_desc, eng);
auto fc8_weights_memory = fc8_user_weights_memory;
if (fc8_prim_desc.weights_desc() != fc8_user_weights_memory.get_desc()) {
fc8_weights_memory = memory(fc8_prim_desc.weights_desc(), eng);
reorder(fc8_user_weights_memory, fc8_weights_memory)
.execute(s, fc8_user_weights_memory, fc8_weights_memory);
}
auto fc8_dst_memory = memory(fc8_prim_desc.dst_desc(), eng);
// create convolution primitive and add it to net
net.push_back(inner_product_forward(fc8_prim_desc));
net_args.push_back({{DNNL_ARG_SRC, fc7_dst_memory},
{DNNL_ARG_WEIGHTS, fc8_weights_memory},
{DNNL_ARG_BIAS, fc8_user_bias_memory},
{DNNL_ARG_DST, fc8_dst_memory}});
// create reorder between internal and user data if it is needed and
// add it to net after pooling
if (fc8_dst_memory != user_dst_memory) {
net.push_back(reorder(fc8_dst_memory, user_dst_memory));
net_args.push_back({{DNNL_ARG_FROM, fc8_dst_memory},
{DNNL_ARG_TO, user_dst_memory}});
}
//[Execute model]
for (int j = 0; j < times; ++j) {
assert(net.size() == net_args.size() && "something is missing");
for (size_t i = 0; i < net.size(); ++i)
net.at(i).execute(s, net_args.at(i));
}
//[Execute model]
s.wait();
}
void cnn_inference_f32(engine::kind engine_kind) {
auto begin = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::steady_clock::now().time_since_epoch())
.count();
int times = 100;
simple_net(engine_kind, times);
auto end = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::steady_clock::now().time_since_epoch())
.count();
std::cout << "Use time: " << (end - begin) / (times + 0.0)
<< " ms per iteration." << std::endl;
}
int main(int argc, char **argv) {
return handle_example_errors(
cnn_inference_f32, parse_engine_kind(argc, argv));
}
oneDNN/src/cpu/x64/jit_generator.hpp
- 原来这个类
jit_generator是继承自Xbyak::CodeGenerator啊!- 那他必然要调经典的函数喽getCode喽!
class jit_generator : public Xbyak::CodeGenerator, public c_compatible {
public:
using c_compatible::operator new;
using c_compatible::operator new[];
using c_compatible::operator delete;
using c_compatible::operator delete[];
private:
const size_t xmm_len = 16;
#ifdef _WIN32
const size_t xmm_to_preserve_start = 6;
const size_t xmm_to_preserve = 10;
#else
const size_t xmm_to_preserve_start = 0;
const size_t xmm_to_preserve = 0;
#endif
const size_t num_abi_save_gpr_regs
= sizeof(abi_save_gpr_regs) / sizeof(abi_save_gpr_regs[0]);
const size_t size_of_abi_save_regs
= num_abi_save_gpr_regs * rax.getBit() / 8
+ xmm_to_preserve * xmm_len;
public:
enum {
_cmp_eq_oq = 0u,
_cmp_lt_os = 1u,
_cmp_le_os = 2u,
_cmp_neq_uq = 4u,
_cmp_nlt_us = 5u,
_cmp_nle_us = 6u,
_op_floor = 1u,
_op_mxcsr = 4u,
};
Xbyak::Reg64 param1 = abi_param1;
const int EVEX_max_8b_offt = 0x200;
const Xbyak::Reg64 reg_EVEX_max_8b_offt = rbp;
oneDNN/src/cpu/x64/jit_generator.hpp里面的register_jit_code函数
void register_jit_code(const Xbyak::uint8 *code, size_t code_size) const {
std::cout << source_file() << std::endl;
jit_utils::register_jit_code(code, code_size, name(), source_file());
}
- 上面这个函数我觉得是所有
primitive都要执行的函数,而且这个source_file()就是你要编译的文件。
src/cpu/jit_utils/jit_utils.cpp
- 对于下面这样的输入
memory::dims conv1_src_tz = {batch, 8, 224, 224};
memory::dims conv1_weights_tz = {32, 8, 3, 3};
memory::dims conv1_bias_tz = {32};
memory::dims conv1_dst_tz = {batch, 32, 112, 112};
memory::dims conv1_strides = {2, 2};
memory::dims conv1_padding = {1, 1};
void register_jit_code(const void *code, size_t code_size,
const char *code_name, const char *source_file_name) {
// The #ifdef guards are required to avoid generating a function that only
// consists of lock and unlock code
#if DNNL_ENABLE_JIT_PROFILING || DNNL_ENABLE_JIT_DUMP
static std::mutex m;
std::lock_guard<std::mutex> guard(m);
dump_jit_code(code, code_size, code_name);
std::cout << source_file_name << std::endl;
register_jit_code_vtune(code, code_size, code_name, source_file_name);
register_jit_code_linux_perf(code, code_size, code_name, source_file_name);
- 输出为下面这样的东西
/zhoukangkang/oneDNN/oneDNN/src/cpu/x64/jit_uni_reorder.cpp
/zhoukangkang/oneDNN/oneDNN/src/cpu/x64/jit_uni_reorder.cpp
/zhoukangkang/oneDNN/oneDNN/src/cpu/x64/jit_avx2_conv_kernel_f32.hpp
Use time: 65 ms per iteration.
Example passed on CPU.
- 其实也就是这个模型只会调用三次
const Xbyak::uint8 *getCode() {- 转输入,转参数
- 然后是执行啊!
最新文章
- ThinkPHP实现支付宝接口功能
- java简单计算器
- NSDate NSString相互转化
- Belkasoft Evidence Center could handle Chinese characters well
- 【转】个人常用iOS第三方库以及XCode插件介绍 -- 不错
- A Knight's Journey(dfs)
- mysql 添加[取消]timestamp的自动更新
- ListView遍历每个Item出现NullPointerException的异常处理(转)
- redis的数据类型 (一) 字符串
- 通过url获取相应的location信息
- Metrics.net + influxdb + grafana 构建WebAPI的自动化监控和预警
- distinct的用法
- 开发人员必备工具 —— JMeter 压测
- Echarts地图使用经验-地图变形和添加数据
- 将jar包安装到本地repository中
- 使用webview几种常见的hybrid通信方式
- 关于图文转换的web工具
- wpf 自定义属性的默认值
- C# foreach 中获取索引index的方法[转]
- 切割数组 - 将一个数组拆分成多个长度为n的数组