HashMap扩容和ConcurrentHashMap
HashMap
存储结构
HashMap是数组+链表+红黑树(1.8)实现的。
(1)Node[] table,即哈希桶数组。Node是内部类,实现了Map.Entry接口,本质是键值对。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用来定位数组索引位置
final K key;
V value;
Node<K,V> next; //链表的下一个node
Node(int hash, K key, V value, Node<K,V> next) { ... }
public final K getKey(){ ... }
public final V getValue() { ... }
public final String toString() { ... }
public final int hashCode() { ... }
public final V setValue(V newValue) { ... }
public final boolean equals(Object o) { ... }
}
下图链表中的Node节点
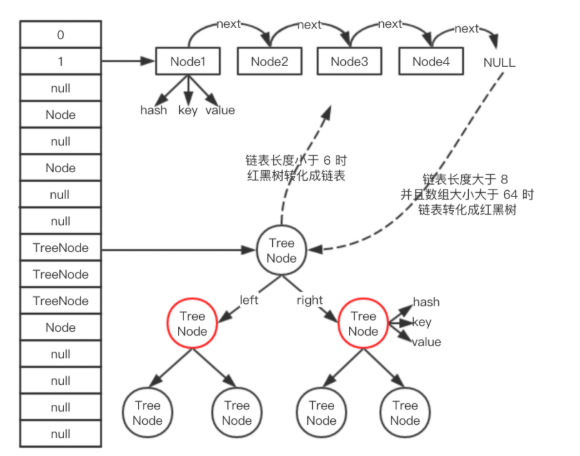
(2)Node[] table初始化长度为16,负载因子是0.75,threshold是HashMap容纳的最大Node个数,threshold = length * Load factor。
int threshold; // 所能容纳的key-value对极限
final float loadFactor; // 负载因子
int modCount;
int size;
功能实现-方法
扩容机制
1.7
1 void resize(int newCapacity) { //传入新的容量
2 Entry[] oldTable = table; //引用扩容前的Entry数组
3 int oldCapacity = oldTable.length;
4 if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
5 threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
6 return;
7 }
8
9 Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
10 transfer(newTable); //!!将数据转移到新的Entry数组里
11 table = newTable; //HashMap的table属性引用新的Entry数组
12 threshold = (int)(newCapacity * loadFactor);//修改阈值
13 }
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。
1 void transfer(Entry[] newTable) {
2 Entry[] src = table; //src引用了旧的Entry数组
3 int newCapacity = newTable.length;
4 for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
5 Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素
6 if (e != null) {
7 src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
8 do {
9 Entry<K,V> next = e.next;
10 int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
11 e.next = newTable[i]; //标记[1]
12 newTable[i] = e; //将元素放在数组上
13 e = next; //访问下一个Entry链上的元素
14 } while (e != null);
15 }
16 }
17 }
newTable[i]的引用赋给e.next,也就是头插法。
扩容过程:假设hash算法是简单的用key mod一下表的大小(数组长度)。数组长度为2,所以key=3、7、5,put顺序为5、7、3。在mod 2以后都冲突在table[1]这里了。这里假设负载因子 loadFactor=1,即当键值对的实际大小size 大于 table的实际大小时进行扩容。接下来的三个步骤是哈希桶数组 resize成4,然后所有的Node重新rehash的过程。

1.8
使用2次幂的扩展,所以,元素的位置要么是原位置,要么是在原位置再移动2次幂的位置。
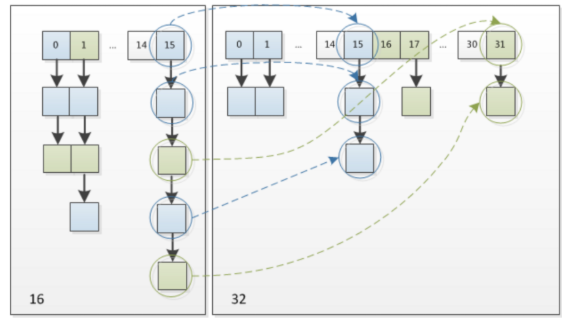
这个设计既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的
过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。
有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表
元素会倒置,但是从DK1.8不会倒置(尾插法)。
ConcurrentHashMap
1.put方法
1.1 数组初始化时的线程安全
数组初始化时,首先通过自旋保证一定可以初始化成功,然后通过CAS设置SIZECTL变量的值,保证同一时刻只能
有一个线程对数组进行初始化,CAS成功之后,会再次判断当前数组是够初始化完成。通过自旋 + CAS + 双重
check保证了数组初始化时的线程安全。
1.2 新增槽点值时的线程安全
通过自旋死循环保证一定可以新增成功。
当前槽点为空时,通过CAS新增。
当前槽点有值,锁住当前槽点。
put 时,如果当前槽点有值,就是 key 的 hash 冲突的情况,此时槽点上可能是链表或红黑树,我们通过锁住槽点,来保证同一时刻只会有一个线程能对槽点进行修改。
- 红黑树旋转时,锁住红黑树的根节点,保证同一时刻,当前红黑树只能被一个线程旋转。
以上4点保证在各种情况下,都是线程安全的,通过自旋 + CAS + 锁。
1.3 扩容时的线程安全
ConcurrentHashMap 扩容的方法交transfer,思路:
- 首先把老数组的值全部拷贝到扩容的新数组上,从数组的队尾开始拷贝;
- 拷贝数组的槽点时,先把原数组槽点锁住,保证原数组槽点不能操作,拷贝到新数组时,把原数组槽点复制为转移节点;
- 这时如果有新数据正好put到此槽点时,发现槽点为转移节点,就会一直等待,所以在扩容完成之前,槽点对应的数据不会变化;
- 从数组的尾部拷贝到头部,每拷贝成功一次,就把原数组中的节点设置为转移节点;
- 直到所有数组数据都拷贝到新数组时,直接把新数组整个复制给数组容器,拷贝完成。
资料
- 美团HashMap
- 慕课网专栏Java源码解析
最新文章
- 洛谷P1991无线通讯网[kruskal | 二分答案 并查集]
- C#自动生成漂亮的水晶效果头像
- js中的原形链问题
- re模块(正则表达式)
- IIS Express魔法堂:解除localhost域名的锁定
- libevent 定时器示例
- cocos3.10 使用cocostudio 回调特性 c++版本说明
- Python自动化运维之17、Python操作 Memcache、Redis、RabbitMQ
- bad interpreter: No such file or directory
- css display属性介绍
- Tracker-store
- 自动化运维:使用flask+mysql+highcharts搭建监控平台
- Django 系列博客(十二)
- tomcat7启动闪退
- java.lang.NumberFormatException: multiple points问题
- 前端之js-本地存储-localStorage && IndexedDB
- jsp/servlet/mysql/linux基本概念和操作
- Java数据类型和不同数据类型在JVM内存分配
- MySQL之长连接、短连接、连接池
- 【Python】常用内建模块(卒)