Tensorflow学习笔记No.8
使用VGG16网络进行迁移学习
使用在ImageNet数据上预训练的VGG16网络模型对猫狗数据集进行分类识别。
1.预训练网络
预训练网络是一个保存好的,已经在大型数据集上训练好的卷积神经网络。
如果这个数据集足够大且通用,那么预训练网络学习到的模型参数可以有效的对图片进行特征提取。即使新问题与原本的数据完全不同,但学习到的特征提取方法依然可以在不同的问题之间进行移植,进而可以在全新的数据集上提取到有效的特征。对这些有效的高级特征进行分类可以大大提高模型分类的准确率。
迁移学习主要适用于已有数据相对较少的情况,如果拥有的数据量足够大,即使不需要迁移学习也能够得到非常高的准确率。
2.如何使用与训练网络
2.1载入图像并创建数据集
首先,读入猫狗数据集中的图片。(实现过程的详细说明在Tensorflow学习笔记No.5中,这里不再赘述)
1 import tensorflow as tf
2 import numpy as np
3 import pandas as pd
4 import matplotlib.pyplot as plt
5 %matplotlib inline
6 import pathlib
7 import random
8
9 data_root = pathlib.Path('../input/cat-and-dog/training_set/training_set')
10
11 all_image_path = list(data_root.glob('*/*.jpg'))
12 random.shuffle(all_image_path)
13 image_count = len(all_image_path)
14
15 label_name = sorted([item.name for item in data_root.glob('*')])
16 name_to_indx = dict((name, indx) for indx, name in enumerate(label_name))
17
18 all_image_path = [str(path) for path in all_image_path]
19 all_image_label = [name_to_indx[pathlib.Path(p).parent.name] for p in all_image_path]
20
21 def load_pregrosess_image(path, label):
22 image = tf.io.read_file(path)
23 image = tf.image.decode_jpeg(image, channels = 3)
24 image = tf.image.resize(image, [256, 256])
25 image = tf.cast(image, tf.float32)
26 image = image / 255
27 return image, label
28
29 train_image_ds = tf.data.Dataset.from_tensor_slices((all_image_path, all_image_label))
30
31 AUTOTUNE = tf.data.experimental.AUTOTUNE
32 dataset = train_image_ds.map(load_pregrosess_image, num_parallel_calls = AUTOTUNE)
33
34 BATCHSIZE = 16
35 train_count = int(image_count * 0.8)
36 test_count = image_count - train_count
37
38 train_dataset = dataset.take(train_count)
39 test_dataset = dataset.skip(train_count)
40
41 train_dataset = train_dataset.shuffle(train_count).repeat().batch(BATCHSIZE)
42 test_dataset = test_dataset.repeat().batch(BATCHSIZE)
2.2加载与训练网络并构建网络模型
与训练的网络由两个部分构成,训练好的卷积基和训练好的分类器。我们需要使用训练好的卷积基来提取特征,并使用自定义的分类器对自己的数据集进行分类识别。
如下图所示:
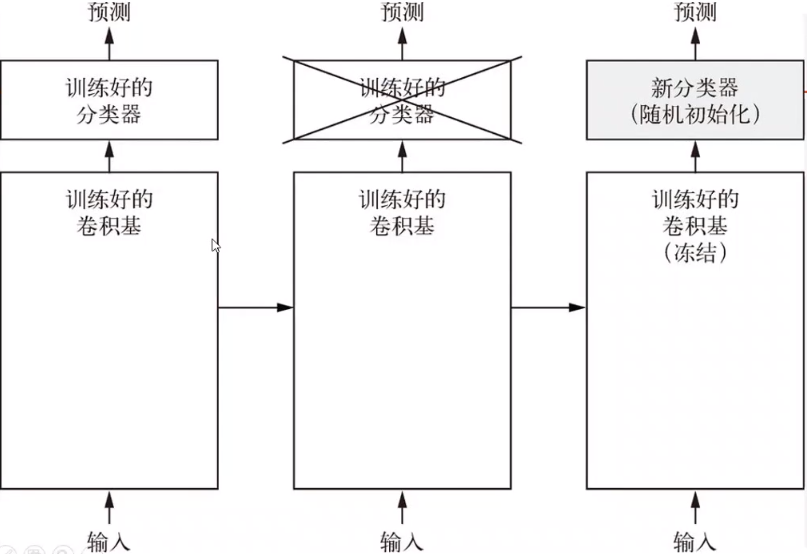
训练过程中,我们仅仅对自定义的分类器进行训练,而不训练预训练好的卷积基部分。
预训练的卷积基可以非常好的提取图像的某些特征,在训练过程中,由于分类器是一个全新的没有训练过的分类器,在训练初期会产生很大的loss值,由于数据量较少,如果不对预训练的卷积基进行冻结(不更新参数)处理,产生的loss值经梯度传递会对预训练的卷积基造成非常大的影响,且由于可训练数据较少儿难以恢复,所以只对自定义的分类器进行训练,而不训练卷积基。
首先从tf.keras.applications中创建一个预训练VGG16的卷积基。
1 cov_base = tf.keras.applications.VGG16(weights = 'imagenet', include_top = False)
weight是我们要使用的模型权重,我们使用经imagenet训练过的模型的权重信息进行迁移学习。
include_top是指,是否使用预训练的分类器。在迁移学习过程中我们使用自定义的分类器,所以参数为False。
然后我们对创建好的卷积基进行冻结处理,冻结所有的可训练参数。
1 cov_base.trainable = False
使用keras.Sequential()创建网络模型。
1 model = tf.keras.Sequential()
2 model.add(cov_base)
3 model.add(tf.keras.layers.GlobalAveragePooling2D())
4 model.add(tf.keras.layers.Dense(512, activation = 'relu'))
5 model.add(tf.keras.layers.Dense(1, activation = 'sigmoid'))
在模型中加入卷积基和自定义的分类器。
模型结构如下图所示:
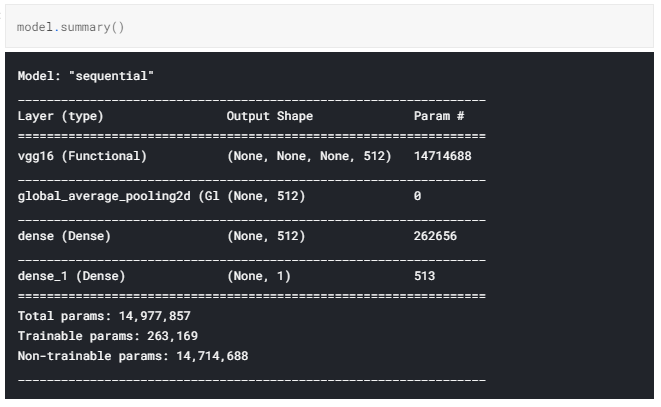
我们得到了一个可训练参数仅为263,169的预训练VGG16网络模型。
2.3使用自定义数据训练分类器
此时模型已经搭建完毕,我们使用之前处理好的数据对它进行训练。
1 model.compile(optimizer = 'adam',
2 loss = 'binary_crossentropy',
3 metrics = ['acc']
4 )
5
6 history = model.fit(train_dataset,
7 steps_per_epoch = train_count // BATCHSIZE,
8 epochs = 10,
9 validation_data = test_dataset,
10 validation_steps = test_count // BATCHSIZE
11 )
12
13 plt.plot(history.epoch, history.history.get('acc'), label = 'acc')
14 plt.plot(history.epoch, history.history.get('val_acc'), label = 'acc')
训练结果如下图所示:

模型在训练集和测试机上的正确率均达到了94%左右,而且仅仅经过了10个epoch就达到了这样的效果,足以看出迁移学习在小规模数据上的优势。
3.微调
虽然使用预训练网络可以轻易的达到94%左右的正确率,但是,如果我们还想继续提高这个正确率该怎样进行调整呢?
所谓微调,是冻结卷积基底部的卷积层,共同训练新添加的分类器和卷积基顶部的部分卷积层。
根据卷积神经网络提取特征的原理我们不难发现,越底层的卷积层提取到的图像特征越抽象越细小,而顶层的卷积层提取到的特征更大,更加的接近我们能直接观察到的数据特征,由于我们需要训练的数据和预训练时使用的数据不尽相同,所以越顶层的卷积层提取到的特征与我们所需要的特征差别越大。所以,我们只冻结底部的卷积层,将顶部的卷积层与训练好的分类器共同训练,会得到更好的拟合效果。
只有分类器以及训练好了,才能微调卷积基的顶部卷积层,否则由于训练初期的误差很大,会将卷积层之前学习到的参数破坏掉。
所以我们对卷积基进行解冻,并只对底部的卷积进行冻结。
1 cov_base.trainable = True
2 for layers in cov_base.layers[:-3]:
3 layers.trainable = False
然后将模型继续进行训练。
1 model.compile(optimizer = tf.keras.optimizers.Adam(lr = 0.0001),
2 loss = 'binary_crossentropy',
3 metrics = ['acc']
4 )
5
6 history = model.fit(train_dataset,
7 steps_per_epoch = train_count // BATCHSIZE,
8 epochs = 20,
9 initial_epoch = 10,
10 validation_data = test_dataset,
11 validation_steps = test_count // BATCHSIZE
12 )
13
14 plt.plot(history.epoch, history.history.get('acc'), label = 'acc')
15 plt.plot(history.epoch, history.history.get('val_acc'), label = 'acc')
注意将学习率调小,以便尽可能的达到loss的极小值点。
得到的结果如下图所示:

模型再训练集上达到了近乎100%的准确率,在测试集上也达到了96%左右准确率,微调的效果还是较为明显的。
那么关于迁移学习的介绍到这里就结束了o(* ̄▽ ̄*)o,后续会更新更多内容。
最新文章
- 使用HttpClient连接池进行https单双向验证
- easyui的window插件再次封装
- ORACLE 表函数实现
- JAVA 数组排序
- malloc calloc realloc,new区别联系以及什么时候用
- JSF 2 dropdown box example
- Qt播放mp3
- SVN的配置与调试
- Oracle检查锁及其等待的行ROWID
- ionic3.0--angular4.0 引入第三方插件库的方法
- 备忘录模式(Memento)
- IPFS: BitSwap协议(数据块交换)
- 删除zabbix数据库日志
- 《http权威指南》读书笔记4
- codeforces#1090 D. New Year and the Permutation Concatenation(打表找规律)
- Linux显示su:认证失败
- 使用block的时候,导致的内存泄漏
- 三种方式监听NGUI的事件方法
- Redhat系统部署安装Splunk
- 好用的vim插件