10: java数据结构和算法: 构建哈夫曼树, 获取哈夫曼编码, 使用哈夫曼编码原理对文件压缩和解压
2024-10-19 20:29:10
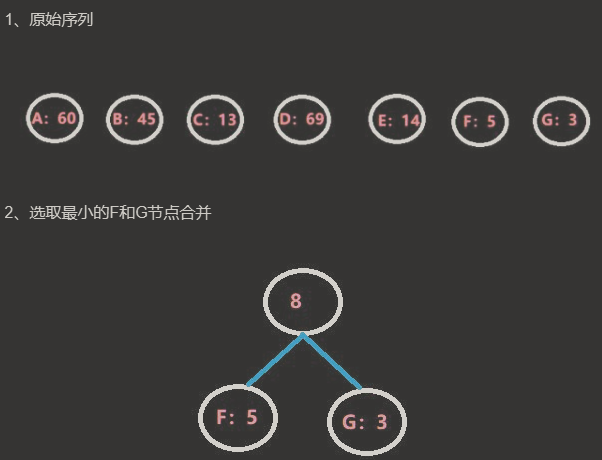

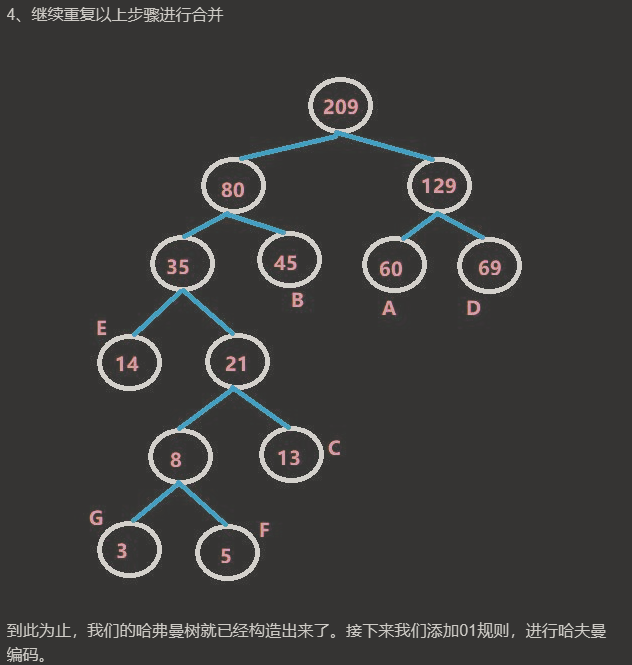
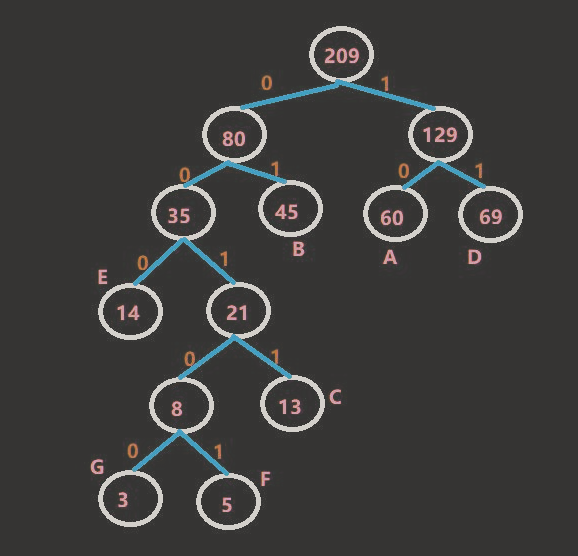
最终结果哈夫曼树,如图所示:
直接上代码:
public class HuffmanCode {
public static void main(String[] args) {
//获取哈夫曼树并显示
Hnode root = createHuffmanTree(createNodes());
root.beforePrint();
System.out.println("====================");
//从哈夫曼树中读取 哈夫曼编码
getHuffmanCode(root);
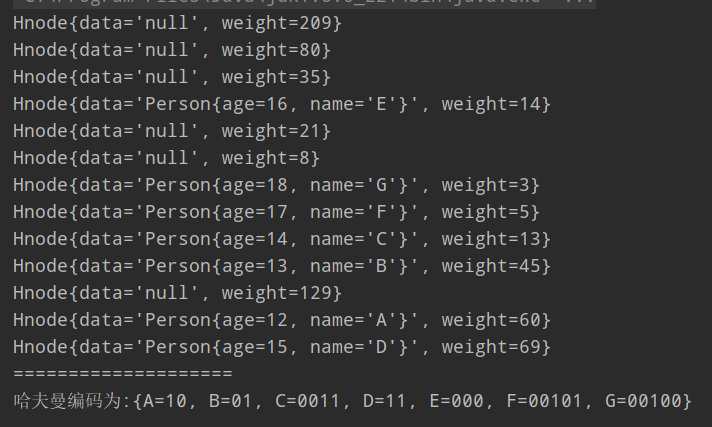
//从huffmanCodes 中读取哈夫曼编码:A:10, B:01, C:0011,D:11,E:000,F:00100,G:00101
System.out.println("哈夫曼编码为:"+huffmanCodes);
}
//创建一个 Hnode节点的集合
public static List<Hnode> createNodes(){
List<Hnode> nodes = new ArrayList<Hnode>();
nodes.add(new Hnode(new Person(12,"A"),60));
nodes.add(new Hnode(new Person(13,"B"),45));
nodes.add(new Hnode(new Person(14,"C"),13));
nodes.add(new Hnode(new Person(15,"D"),69));
nodes.add(new Hnode(new Person(16,"E"),14));
nodes.add(new Hnode(new Person(17,"F"),5));
nodes.add(new Hnode(new Person(18,"G"),3));
return nodes;
}
//根据list 创建哈夫曼树
public static Hnode createHuffmanTree(List<Hnode> nodes){
while(nodes.size() > 1){
//先对 nodes进行从小到大排序, 根据权重值进行从小到大排序
Collections.sort(nodes, new Comparator<Hnode>() {
public int compare(Hnode o1, Hnode o2) {
return o1.weight - o2.weight;
}
});
//取出前二个最小的元素,构建一个父节点只有权重 没有数据的二叉树
Hnode leftNode = nodes.get(0);
Hnode rightNode = nodes.get(1);
Hnode parent = new Hnode(null, leftNode.weight + rightNode.weight);
parent.leftNode = leftNode;
parent.rightNode = rightNode;
//将原来nodes中已经处理的前二个最小元素删除调,并将parent节点存入nodes中
nodes.remove(leftNode);
nodes.remove(rightNode);
nodes.add(parent);
}
//循环结束时候,nodes中只有一个节点了,且该节点就是哈夫曼树的根节点
return nodes.get(0);
}
static StringBuilder stringBuilder = new StringBuilder();
static Map<String,String> huffmanCodes = new HashMap<String, String>();
//从哈夫曼树中读取 哈夫曼编码: A:10, B:01, C:0011,D:11,E:000,F:00100,G:00101
public static void getHuffmanCode(Hnode root){
if (root == null) {
return ;
}
getCode(root.leftNode,"0",stringBuilder);
getCode(root.rightNode,"1",stringBuilder);
}
private static void getCode(Hnode node, String code, StringBuilder builder) {
StringBuilder builder1 = new StringBuilder(builder);
builder1.append(code);
if (node != null) {
if (node.person == null) {
//如果数据为不null,说明是子节点
//左递归处理
getCode(node.leftNode,"0",builder1);
//右递归处理
getCode(node.rightNode,"1",builder1);
}else{
//如果数据为null,说明是叶子节点
huffmanCodes.put(node.person.name,builder1.toString());
}
}
}
}
//先建节点
class Hnode{
Person person;//数据
int weight;//权重
Hnode leftNode;
Hnode rightNode;
public Hnode(Person person, int weight) {
this.person = person;
this.weight = weight;
}
@Override
public String toString() {
return "Hnode{" +
"data='" + person + '\'' +
", weight=" + weight +
'}';
}
//前序遍历
public void beforePrint(){
System.out.println(this);
if (this.leftNode != null) {
this.leftNode.beforePrint();
}
if (this.rightNode != null) {
this.rightNode.beforePrint();
}
}
}
class Person {
int age;
String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
结果如下:
压缩原理:
1: 被压缩文件通过输入流,转化为原始字节数组, 遍历统计每个字节出现的次数,并转化为map, key:字节,value:该字节的次数
2: map 转化为list,根据list创建 哈夫曼树,并获取到对应的哈夫曼编码
3: 将哈夫曼编码转化字节数组,通过输出流,写入到目标文件中,同时将哈夫曼编码也写入到目标文件中(目的:是为了解码使用)
解压缩原理:
1: 通过输入流从被解压缩文件中,读取到哈夫曼编码,和 哈夫曼编码转化字节数组,
2: 解码 得到原始字节数组, 并将数组写出到目标文件中
最新文章
- 福利到~分享一个基于jquery的智能提示控件intellSeach.js
- IOS学习笔记之关键词@dynamic
- ubuntu 12 JDK 编译
- Java 关键字 native
- oracle的簇的创建
- Hadoop实战3:MapReduce编程-WordCount统计单词个数-eclipse-java-ubuntu环境
- ubuntu 错误 & 解决
- 8个web前端的精美HTML5 & CSS3效果及源码下载
- 一个例子简要说明include和require的区别
- windows平台python 2.7环境编译安装zbar
- webpack打包编译时,不识别src目录以外的js或css
- Js中for循环的阻塞机制
- Mysql -- 数据类型(2)
- [转]OpenShift 集群搭建指南
- Linux命令:pushd
- 关于bug的一些思考
- 为数据库重新生成log文件
- 将眼底图片生成的txt文件进行格式化处理
- 129. Sum Root to Leaf Numbers pathsum路径求和
- RESTful规范(二)