【collection】1.java容器之HashMap&LinkedHashMap&Hashtable
Map源码剖析
HashMap&LinkedHashMap&Hashtable
hashMap默认的阈值是0.75
HashMap put操作
put操作涉及3种结构,普通node节点,链表节点,红黑树节点,针对第三种,红黑树节点,我们后续单独去学习,这里不多做扩散
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) {
// 初始化哈希数组,或者对哈希数组扩容,返回新的哈希数组
tab = resize();
n = tab.length;
}
// 相当于取余
i = (n - 1) & hash;
p = tab[i];
if (p == null) {
// 直接放普通元素
tab[i] = newNode(hash, key, value, null);
} else {
Node<K,V> e; K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) {
// 存在同位元素,也就是出现了hash碰撞
e = p;
} else if (p instanceof TreeNode) {
// 如果当前位置已经是红黑树节点,那么就put红黑色
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
} else {
// 遍历哈希槽后面链接的其他元素(binCount统计的是插入新元素之前遍历过的元素数量)
// 这里就是链表类型
for (int binCount = 0; ; ++binCount) {
// 后继节点为空
if ((e = p.next) == null) {
// 拼接到后继节点上
p.next = newNode(hash, key, value, null);
/**
* 哈希槽(链)上的元素数量增加到TREEIFY_THRESHOLD后,这些元素进入波动期,即将从链表转换为红黑树
* 注意这个TREEIFY_THRESHOLD 是8,为什么是8??
* 每次遍历一个链表,平均查找的时间复杂度是 O(n),n 是链表的长度。由于红黑树有自平衡的特点,可以防止不平衡情况的发生,
* 所以可以始终将查找的时间复杂度控制在 O(log(n))。
* 最初链表还不是很长,所以可能 O(n) 和 O(log(n)) 的区别不大,但是如果链表越来越长,那么这种区别便会有所体现。所以为了提升查找性能,需要把链表转化为红黑树的形式。
* 链表查询的时候使用二分查询,平均查找长度为n/2,长度为8的时候,为4,而6/2 = 3
* 而如果是红黑树,那么就是log(n) ,长度为8时候,log(8) = 3, log(6) =
* 这个时候我们发现超过8这个阈值之后,链表的查询效率会越来越不如红黑树
*/
if (binCount >= TREEIFY_THRESHOLD - 1) {
// -1 for 1st
treeifyBin(tab, hash);
}
break;
}
// 判断链表中的后继原始是否hash碰撞,如果发生了hash碰撞break
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 如果存在同位元素(在HashMap中占据相同位置的元素)
if (e != null) { // existing mapping for key
V oldValue = e.value;
// 判断是否需要进行覆盖取值,因为key相同,那么直接取代,否则什么也不操作
if (!onlyIfAbsent || oldValue == null) {
e.value = value;
}
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
总结关键信息:
哈希槽(链)上的元素数量增加到TREEIFY_THRESHOLD后,这些元素进入波动期,即将从链表转换为红黑树
注意这个TREEIFY_THRESHOLD 是8,为什么是8??
每次遍历一个链表,平均查找的时间复杂度是 O(n),n 是链表的长度。由于红黑树有自平衡的特点,可以防止不平衡情况的发生,
所以可以始终将查找的时间复杂度控制在 O(log(n))。
最初链表还不是很长,所以可能 O(n) 和 O(log(n)) 的区别不大,但是如果链表越来越长,那么这种区别便会有所体现。所以为了提升查找性能,需要把链表转化为红黑树的形式。
链表查询的时候使用二分查询,平均查找长度为n/2,长度为8的时候,为4,而6/2 = 3
而如果是红黑树,那么就是log(n) ,长度为8时候,log(8) = 3, log(6) =
这个时候我们发现超过8这个阈值之后,链表的查询效率会越来越不如红黑树
HashMap get,remove操作
除了红黑树的查找比较特殊,其余的链表查找就是暴力搜索,只是平均下来找到一个元素的话是n/2
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab = table;
Node<K,V> p;
int n, index;
if (tab != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) {
// 找到节点,并且是首节点
node = p;
} else if ((e = p.next) != null) {
if (p instanceof TreeNode) {
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
} else {
// 链表查询,暴力搜索
do {
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// 移除节点,可能只需要匹配hash和key就行,也可能还要匹配value,这取决于matchValue参数
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) {
// 移除红黑树节点
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
} else if (node == p) {
// 移除首节点为后继节点
tab[index] = node.next;
} else {
// 链表断开
p.next = node.next;
}
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
HashMap扩容
链表拆分,进入新的容器
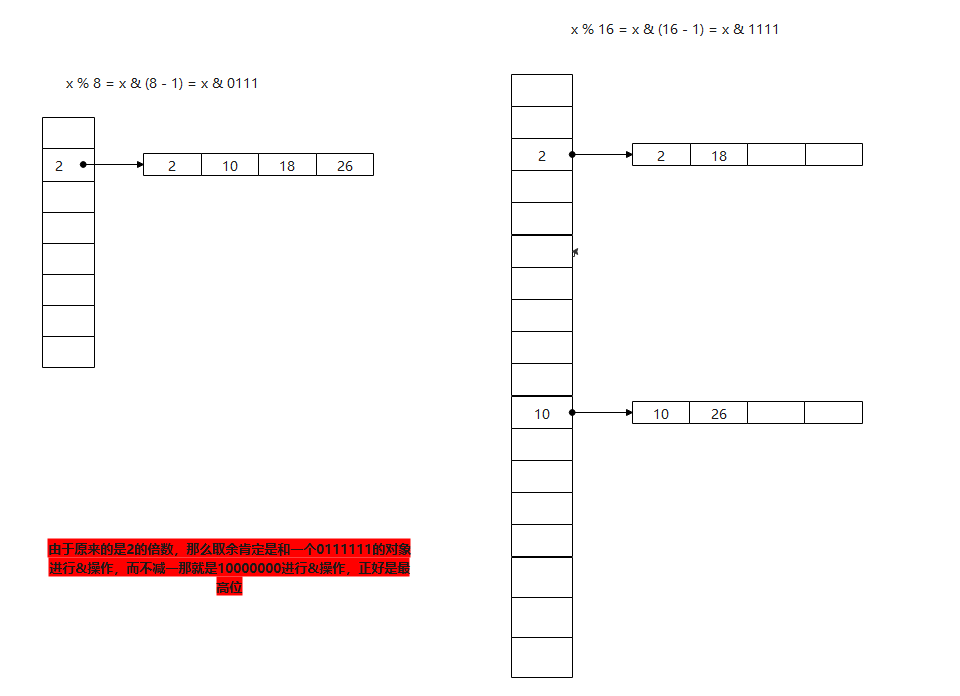
这里有个知识点:如何使用位运算进行取模
a % b == a & (b - 1)
我们拆分链表的思路也是这样:比如原来长度为8的链表,也就是 x % 8 = x & (8 - 1) = x & 0111 也就是取后三位,那么扩容之后重新排序的话,容量扩大一倍,也就是16,那么这个时候就是 x % 16 = x & (16 - 1) = x & 1111 这个时候我们发现和之前的区别就是最高位由原来的0变为1,如果还在后三位范围内,那么新容量中的位置是不会变的
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 旧阈值
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 判断旧容量是否已经超过最大值
if (oldCap >= MAXIMUM_CAPACITY) {
// 如果已经达到1 << 30;,那么直接设置为Integer.MAX_VALUE; 0x7fffffff
threshold = Integer.MAX_VALUE;
return oldTab;
} else {
// mod by xiaof 尝试将哈希表数组容量加倍,注意这里是左移,也就是说*2
newCap = oldCap << 1;
// 如果容量成功加倍(没有达到上限),则将阈值也加倍
if (newCap < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) {
newThr = oldThr << 1;
}
}
// else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
// oldCap >= DEFAULT_INITIAL_CAPACITY) {
// newThr = oldThr << 1; // double threshold
// }
} else if (oldThr > 0) {
// initial capacity was placed in threshold
newCap = oldThr;
} else { // zero initial threshold signifies using defaults
// 如果实例化HashMap时没有指定初始容量,则使用默认的容量与阈值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
/*
* 至此,如果newThr==0,则可能有以下两种情形:
* 1.哈希数组已经初始化,且哈希数组的容量还未超出最大容量,
* 但是,在执行了加倍操作后,哈希数组的容量达到了上限
* 2.哈希数组还未初始化,但在实例化HashMap时指定了初始容量
*/
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
// 如果新容量小于最大允许容量,并且新容量*装载因子之后还是小于最大容量,那么说明不需要扩容,那么直接使用ft作为新的阈值容量
// 如果新容量已经超过最大容量了,那么就直接返回最大允许的容量
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 更新阈值
threshold = newThr;
// 新的容器对象,创建容量为新的newCap
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 遍历原来的数据,准备转移到新的容器上
for (int j = 0; j < oldCap; ++j) {
// 获取旧容器对象
Node<K,V> e = oldTab[j];
if (e != null) {
// 把原来的数组中的指针设置为空
oldTab[j] = null;
if (e.next == null) {
// 重新计算hash索引位置,计算hash位置的方式防止数组越界的话,那么就设置hashcode & 长度 - 1
newTab[e.hash & (newCap - 1)] = e;
} else if (e instanceof TreeNode) {
// 红黑树,这里是对红黑树进行拆分
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
} else { // preserve order
// lo对应的链表是数据不会动的
Node<K,V> loHead = null, loTail = null;
// hi对应的链表标识是需要去新容器新的位置的
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// 这个是链表的情况下进行拆分
// 因为num % 2^n == num & (2^n - 1),容量大小一定是2的N次方
do {
next = e.next;
// 注意:e.hash & oldCap,注意这里是对老的容量oldCap进行计算这一步就是前面说的判断多出的这一位是否为1
// 因为新的是老的2倍,新节点位置是否需要发生改变,取决于最高位是否为0
// 若与原容量做与运算,结果为0,表示将这个节点放入到新数组中,下标不变
// 由于原来的是2的倍数,那么取余肯定是和一个0111111的对象进行&操作,而不减一那就是10000000进行&操作,正好是最高位
if ((e.hash & oldCap) == 0) {
// 最高位为0,那么位置不需要改变,本身就在原来容量范围内的数据
// 直接加入lotail,并判断是否需要初始化lotail
if (loTail == null) {
loHead = e;
} else {
loTail.next = e;
}
loTail = e;
} else {
// 最高位是1,那么就需要进行切换位置
if (hiTail == null) {
hiHead = e;
} else {
hiTail.next = e;
}
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// 最后返回最新的容器对象
return newTab;
}
LinkedHashMap
基本和hashmap差不多,唯一需要注意下的是
还有一个核心点就是linkedHashMap覆盖了newNode方法
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
// 这里创建了linkedhashmap对象
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 创建完成之后,就添加到链表中连接起来
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
插入覆盖afterNodeAccess
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
// 获取节点 b -> p -> a
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 断开尾部连接
p.after = null;
// 如果前置节点是空的,那么就吧A作为head节点
if (b == null) {
head = a;
} else {
// 如果前置节点不为空,那么就吧前置节点连接到后置节点,吧中间节点断开
b.after = a;
}
// 后置节点不为空,那么就吧后置节点连接到前置节点上
if (a != null) {
a.before = b;
} else {
// 如果后置节点为空,那么重新设置tail指向before节点
last = b;
}
// 重新连接当前这个节点到末尾
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
afterNodeInsertion在linkedhashmap中作用不大
/**
*
* +----+ +----+ +----+
* | b | ---> | p | ---> | a |
* +----+ +----+ +----+
* @param e
*/
void afterNodeRemoval(Node<K,V> e) { // unlink
// 移除节点
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null) {
head = a;
} else {
b.after = a;
}
if (a == null) {
tail = b;
} else {
a.before = b;
}
}
综上:linkedhashmap相对hashmap其实就是多加了一个链表把所有的数据关联起来,只有在遍历的时候才能体现出来有序,其他的操作是没有差别的
关于hashtable
首先hashtable是线程安全的,因为它所有的函数都加上了synchronized
链表头插法,没有红黑树的转换
初始化容量的时候默认是11,是奇数,而hashmap全都是2的幂次方
hashtable允许key为null
rehash函数
常用的hash函数是选一个数m取模(余数),这个数在课本中推荐m是素数,但是经常见到选择m=2n,因为对2n求余数更快,并认为在key分布均匀的情况下,key%m也是在[0,m-1]区间均匀分布的。但实际上,key%m的分布同m是有关的。
证明如下: key%m = key - xm,即key减掉m的某个倍数x,剩下比m小的部分就是key除以m的余数。显然,x等于key/m的整数部分,以floor(key/m)表示。假设key和m有公约数g,即key=ag, m=bg, 则 key - xm = key - floor(key/m)m = key - floor(a/b)m。由于0 <= a/b <= a,所以floor(a/b)只有a+1中取值可能,从而推导出key%m也只有a+1中取值可能。a+1个球放在m个盒子里面,显然不可能做到均匀。
由此可知,一组均匀分布的key,其中同m公约数为1的那部分,余数后在[0,m-1]上还是均匀分布的,但同m公约数不为1的那部分,余数在[0, m-1]上就不是均匀分布的了。把m选为素数,正是为了让所有key同m的公约数都为1,从而保证余数的均匀分布,降低冲突率。
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
// 这里重新计算容量的办法是容量扩大一倍,然后+1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE) {
// Keep running with MAX_ARRAY_SIZE buckets
return;
}
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
// 重新把旧的原始转移到新数组上
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
// 这里因为容量是奇数,那么就需要使用%取余,而不是位运算 -》 a & (b - 1)
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
参考
https://www.cnblogs.com/tuyang1129/p/12368842.html -- 链表拆分
https://www.cnblogs.com/lyhc/p/10743550.html - linkedhashmap
最新文章
- 异步编程系列第04章 编写Async方法
- 线上mongodb数据库mLab使用总结
- Sqlserver 函数
- 【原】iOS学习之SQLite和CoreData数据库的比较
- [转载]【基础篇】不为人知的Maya移动坐标轴
- 收集的maven 仓库地址(maven repository)
- Oracle迁移MySQL笔记
- 机器学习之单变量线性回归(Linear Regression with One Variable)
- Linux系统swap已分区但无法挂载与cryptswap1问题
- web项目环境搭建(1):建立一个maven项目
- Android分屏显示LogCat
- 网络最大流最短增广路Dinic算法模板
- 超高速指数模糊算法的实现和优化(10000*10000在100ms左右实现)。
- POJ 3190 Stall Reservations贪心
- CSS后代选择器“空格”和“>”的使用辨析
- 微信小程序wx.showLoading
- easyUI添加修改tab页(toolbar)
- 【译】7. Java反射——私有字段和私有方法
- Vue(八):监听属性watch
- [T-ARA][O My God]
热门文章
- Java SE 4、继承
- Git将本地仓库上传到github
- Stream流式计算
- 重要参考文档---MySQL 8.0.29 使用yum方式安装,开启navicat远程连接,搭建主从,读写分离(需要使用到ProxySQL,此文不讲述这个)
- Kibana可视化数据(Visualize)详解
- 解决centos系统突然间网络不通的问题:Global IPv6 forwarding is disabled in configuration, but not currently disabled in kernel
- loam详细代码解析与公式推导
- 微软出品自动化神器【Playwright+Java】系列(五) 之 常见点击事件操作
- 故障复盘究竟怎么做?美图SRE结合10年经验做了三大总结(附模板)
- Vue学习之--------深入理解Vuex之模块化编码(2022/9/4)