【Java】【数据库】索引为何使查询变得更快?--B+树
排序数据的二分查找
二分查找的时间复杂度是\(O(log_2n)\),明显快于暴力搜索。
索引
建立索引的数据,就是通过事先排好顺序,在查找时可以应用二分查找来提高查询效率。
所以索引应该尽可能建立在主键这样的字段上,因为主键必须唯一,所以这样生成的二叉查找树的效率是最高的。
数据库索引的原理-- B+ 树
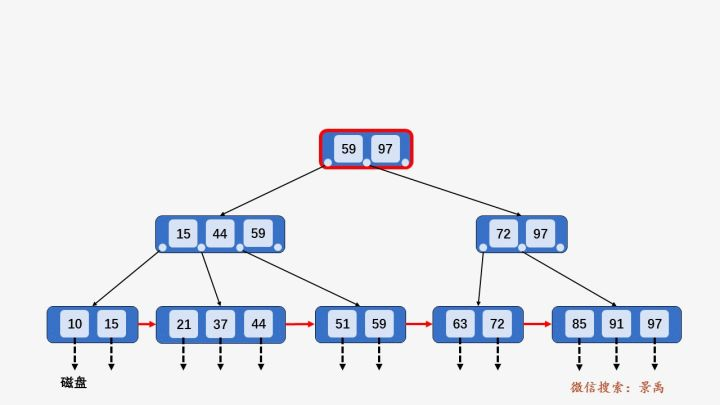
数据库用 B+ 树来实现索引
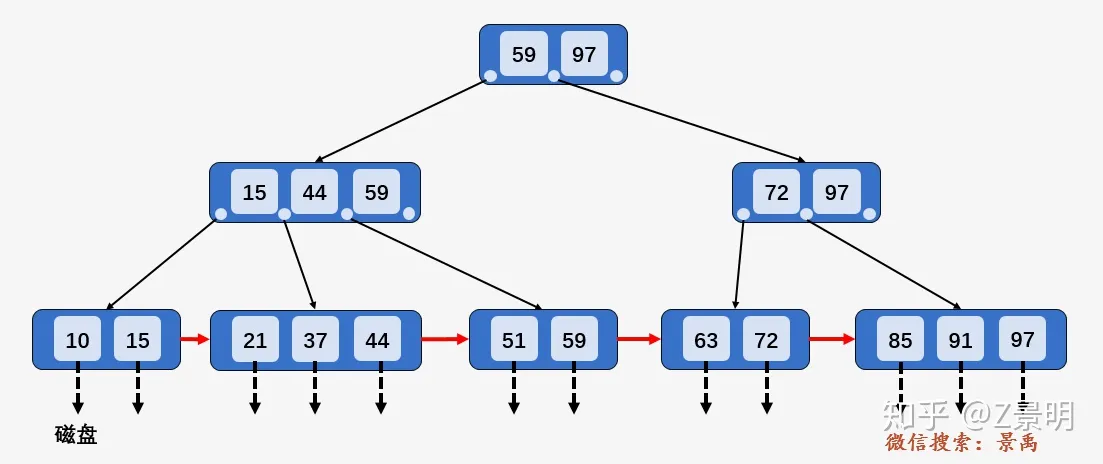
其中, 非叶子节点形如
\(<P_1,K_1,P_2,K_2,...,P_{c-1},K_{c-1},P_c>\)
以第一层为例,\(<P_1,59,P_2,97,P_3>\).满足数据部分(\(K_i\))从小到大有序排列,且指针\(P_i\)指向的下一个节点\(X\)满足\(K_{i-1}<X<=K_i\) , 例如图中的树,59在它左边节点指向的树里,44在它左边结点指向的树里,15在它左边结点指向的树里,且都是在最右边的位置。
B+树延伸
查找操作
以上图查找\(key=59\)为例,
先访问根节点\([59,97]\), 发现\(key\)小于等于根节点中的第一个数\(59\), 于是继续访问\(59\)左边的指针指向的节点\([15,44,59]\), 发现\(key\)小于等于第三个树\(59\), 于是访问\(59\)左边的指针指向的叶子节点\([51,59]\), 遍历找到要查找的元素\(59\).
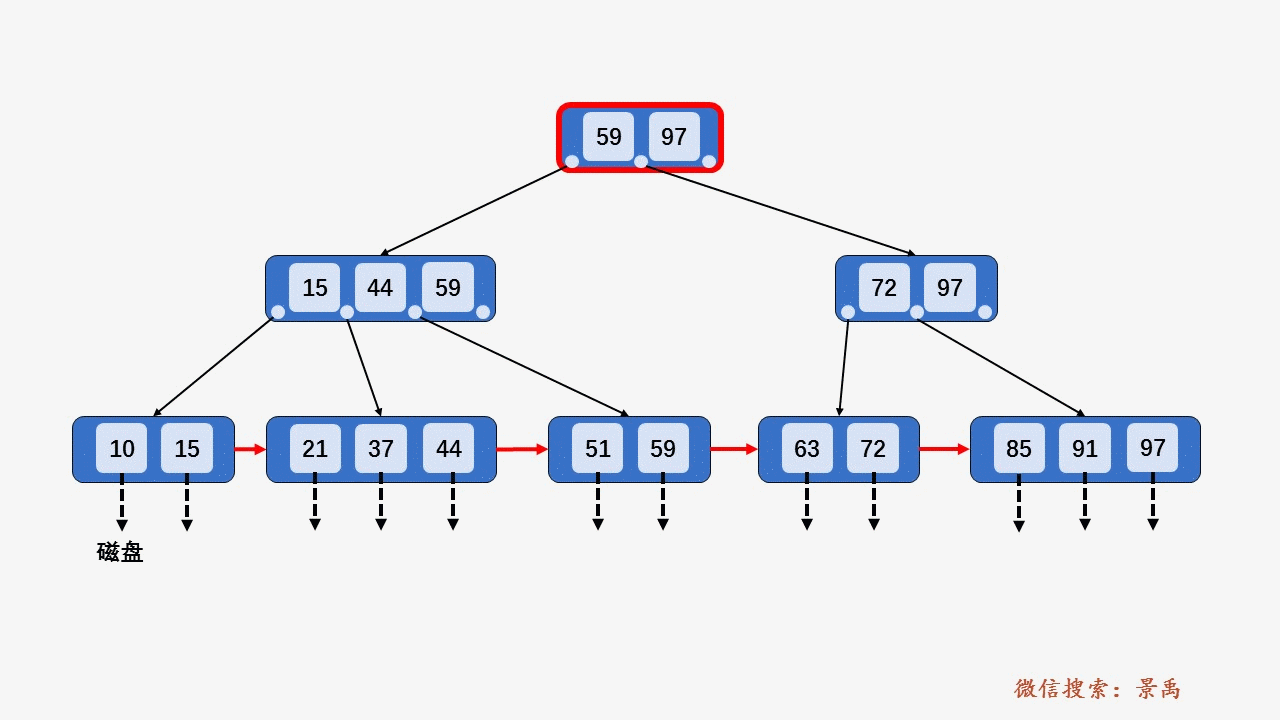
叶子节点的详细结构如下图
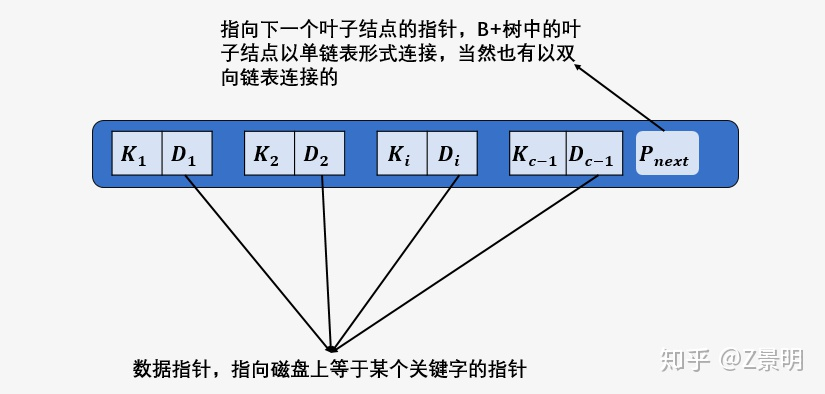
由于数据指针只在叶子节点上,所以 B+ 树所有查询所有关键字的磁盘 \(I/O\) 的次数都是树的高度。
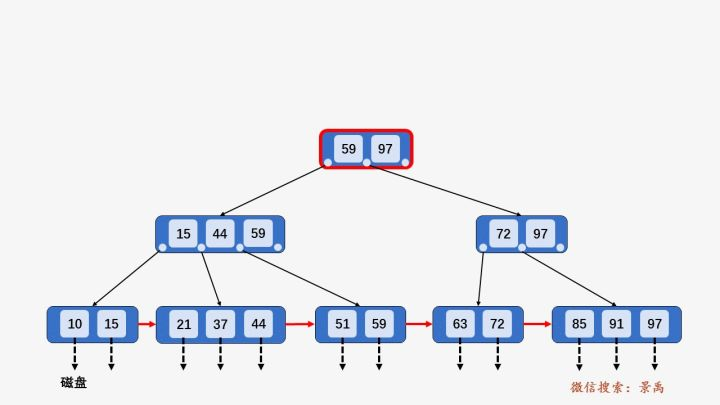
区间查找
在上面的叶子节点图中,我们可以看到每个叶子节点有一个指针\(P_{next}\), 它的作用体现在区间查找的时候。
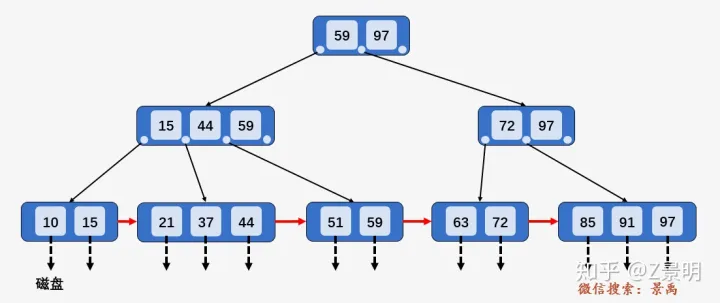
例如,需要查询\([21,63]\)之间的关键字。
- \(21<59\),访问\(59\)左边指针指向的节点\([15,44,59]\).
- \(15<21<44\), 访问\(44\)左边指针指向的叶子节点\([21,37,44]\).
- 遍历这个叶子节点找到\(21\),下面的操作就如同单链表的遍历,一直遍历到\(63\)即可.
插入操作
不细说了,这篇文章的动图能说明一切知乎文章
只把动图贴到这里
没有超出叶子结点的最大容量m
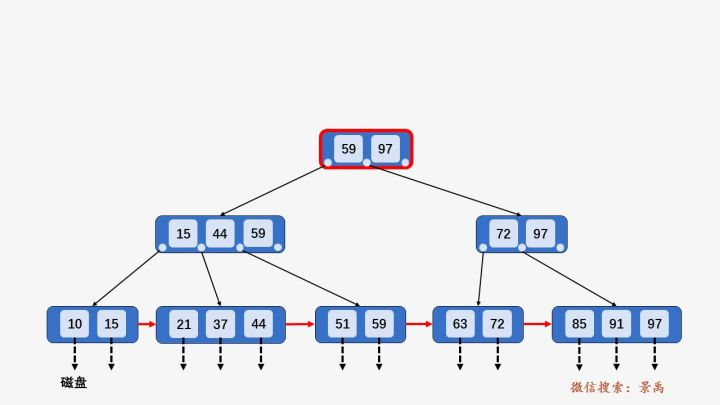
超出m,要分裂叶子节点
分裂叶子节点导致上层的节点也超出m,要分裂上层的节点
插入数值比当前最大值还大,要保证新的最大值在根节点中,需要重新调整 B+ 树
B+ 树的复杂度
查找、插入和删除等操作的时间复杂度都是\(O(logn)\)
至于这个结论怎么得出的,还是看那篇知乎文章吧,写得太好了。
最新文章
- jquery 中的框架
- Jsoup开发网站客户端第二篇,图片轮播,ScrollView兼容ListView
- java综合实训第二次
- 24章 创建TPL自定义模板(1)
- Azure Backup (1) 将SQL Server 2012虚拟机中数据库备份到Azure Storage
- 第 26 章 CSS3 动画效果
- ScrollView内部元素如何做到fill_parent 或者 match_parent?
- excel中 lookup的使用
- 9张思维导图学习Javascript(转)
- Velocity
- Docker几个基本常识
- mysql catalog的名字
- Prefix tree
- PowerDesigner导出SQL,注释为空时以name代替
- LimeSDR 上手指南
- AVL树,红黑树
- arch Linux 安装完,无法通过 SSH 远程连接 root 用户问题
- SqlServer字符串拼接
- java指针与引用(转载)
- 20155205 《Java程序设计》0510课上实践博客
热门文章
- 在 K8S 上部署以 mysql 数据库作为后端存储的单机版 nacos
- InetAddress.getLocalHost() 执行很慢?
- Netty 学习(八):新连接接入源码说明
- 第一个Spring Boot的MVC程序
- 空 Maven项目转成 Web项目 & SpringMVC调用其他 Module中的方法可能会遇到的小问题
- 代码随想录第四天| 24. 两两交换链表中的节点 、19.删除链表的倒数第N个节点 、160.链表相交、142.环形链表II
- 记一次 .NET 某电子病历 CPU 爆高分析
- import cv2报错
- RabbitMQ安装说明文档(超详细版本)
- nrf9160做主控连接阿里云——(mqtt_simple例程)