论文笔记 - Active Learning by Acquiring Contrastive Examples
2024-10-08 17:18:32
Motivation
最常用来在 Active Learning 中作为样本检索的两个指标分别是:
- 基于不确定性(给模型上难度);
- 基于多样性(扩大模型的推理空间)。
指标一可能会导致总是选到不提供有效信息的重复数据(例如模棱两可的、毫无价值的样本);而指标二会导致选择到的样本虽然具有多样性,但是太过于简单(你以为是选择个对于模型来说很陌生的样本,但模型说这种难度早就掌握了),不能有效增强模型能力。
Analysis
某些样本在模型特征空间中距离很近,但是模型推理的似然概率却差异很大,称为对比样本(样本距离很近,但分类的结果却不同,那么决策边界就在其中!作者认为这种样本很重要)。
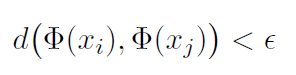
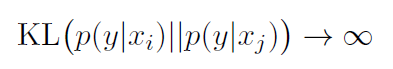
在特征空间中的 Embedding 很相近,但是推理的结果差异老大了。
Algorithm

对于每个样本点,利用 KNN 选择 它的最临近的 k 个样本,计算被选择的 k 个样本的似然概率,与最开始的样本求 KL 散度后平均,作为 这个样本点的 CAL 得分,CAL 越高,证明自己越特殊(身边的邻居跟自己的分类结果都不一样)。
最新文章
- Android 自定义View及其在布局文件中的使用示例
- oracle遍历表更新另一个表(一对多)
- PhpStorm破解教程
- Big Event in HDU
- git流程及操作
- linux之pid文件
- pd虚拟机死机怎么解决
- 添加Appicon的方法
- 执行SQL查询脚本
- BNU 沙漠之旅
- 运动框架实现思路(js)
- Spring集成RabbitMQ-连接和消息模板
- Spring使用@Scheduled定时调度
- Codeforces484 A. Bits
- Apple ID双重认证验证码无法输入问题
- 深度学习原理与框架-Tensorflow基本操作-mnist数据集的逻辑回归 1.tf.matmul(点乘操作) 2.tf.equal(对应位置是否相等) 3.tf.cast(将布尔类型转换为数值类型) 4.tf.argmax(返回最大值的索引) 5.tf.nn.softmax(计算softmax概率值) 6.tf.train.GradientDescentOptimizer(损失值梯度下降器)
- chrome浏览器表单自动填充默认样式(背景变黄)-autofill
- USACO 1.2.3 Name That Number 命名那个数字(打开文件)
- Qt基础——让使用Designer创建的UI也能自动适应窗口大小
- Mysql文章笔记