[平台建设] Spark任务的诊断调优
背景
平台目前大多数任务都是Spark任务,用户在提交Spark作业的时候都要进行的一步动作就是配置spark executor 个数、每个executor 的core 个数以及 executor 的内存大小等,这项配置目前基本靠用户个人经验,在这个过程中,有的用户就会设置非常不合理,比如配置的内存非常大,实际上任务运行时所占用的内存极少. 基于此,希望能有工具来针对任务进行分析,帮助用户来监控和调优任务,并给出一些建议,使任务更加有效率,同时减少乱配资源影响其他用户任务运行的情况。
Dr. Elephant介绍
通过调研,发现一个开源项目 Dr. Elephant 基本与想要达成目标一致。
DR.Elephant 介绍:
Dr. Elephant is a job and flow-level performance monitoring and tuning tool for Apache Hadoop and Apache Spark
Dr功能介绍:
https://github.com/linkedin/dr-elephant/wiki/User-Guide
接下来就是需要了解下Dr的架构, 因为我们有些定制化的需求,所以需要了解下架构,以及阅读源码进行相关改造适配。
Dr. Elephant 的系统架构如下图。主要包括三个部分:
数据采集:数据源为 Job History
诊断和建议:内置诊断系统
存储和展示:MySQL 和 WebUI
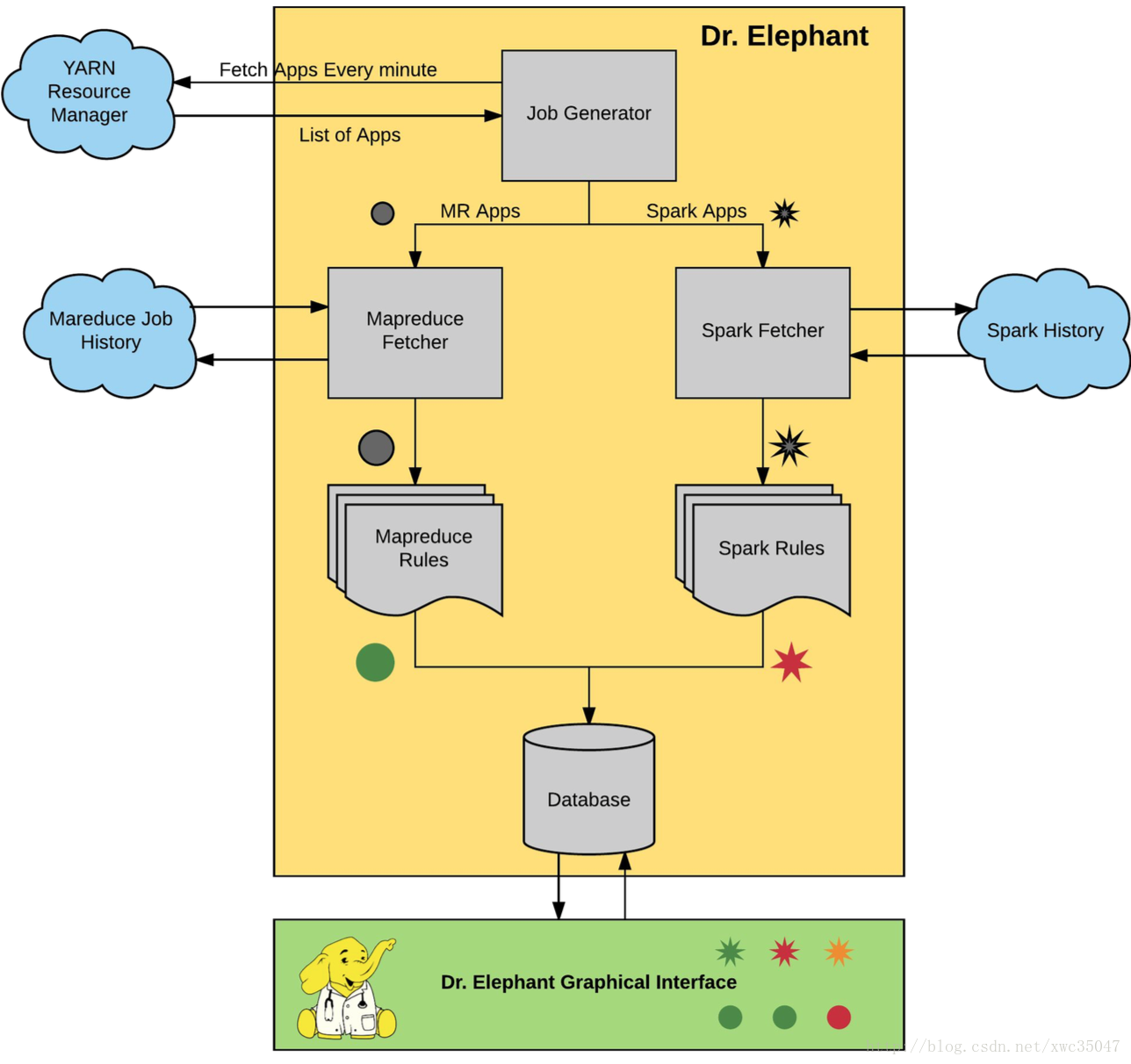
Dr.Elephant定期从Hadoop平台的YARN资源管理中心获取近期所有的任务,这些任务既包含成功的任务,也包含那些失败的任务。每个任务的元数据,例如任务计数器、配置信息以及运行信息都可以从Hadoop平台的历史任务服务端获取到。一旦获取到了任务的元数据,Dr.Elephant就基于这些元数据运行启发式算法,然后会产生一份该启发式算法对该任务性能的诊断报告。根据每个任务的执行情况,这份报告会为该任务标记一个待优化的严重性级别。严重性级别一共分为五级,报告会对该任务产生一个级别的定位,并通过级别来表明该任务中存在的性能问题的严重程度。
启发式算法具体要做的事情就是:
- 获取数据
- 量化计算打分
- 将分值与不同诊断等级阈值进行比较
- 给出诊断等级
源码解析与改造
首先我们要知道Dr整体的运行流程是怎么样的?
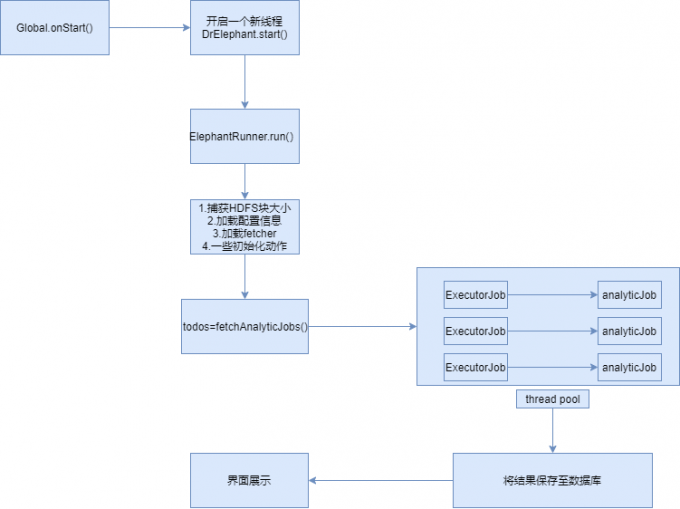
因为我们只需要关注Spark任务,下面主要介绍下Spark指标如何采集?
上面我们已经知道Dr执行的大致流程, 我们只采集spark任务, 所以不用太多额外的代码和抽象.
只需要关键的几个步骤改造即可:
1.首先还是通过yarn api 获取执行的job, 我们只需要对ExecutorJob直接使用org.apache.spark.deploy.history.SparkFSFetcher#fetchData方法, 获取eventlog, 并对eventlog进行重放解析
将解析后的数据,获取相关需要的信息,直接写入mysql库
因为涉及连接hdfs,yarn 等服务,将hdfs-site.xml,core-site.xml等文件放置配置目录下
最终将程序改造成一个main方法直接运行的常驻进程运行
采集后的主要信息:
- 采集stage相关指标信息
- 采集app任务配置、executor个数、核数等,执行开始时间、结束时间、耗时等
改造后整体流程如下:
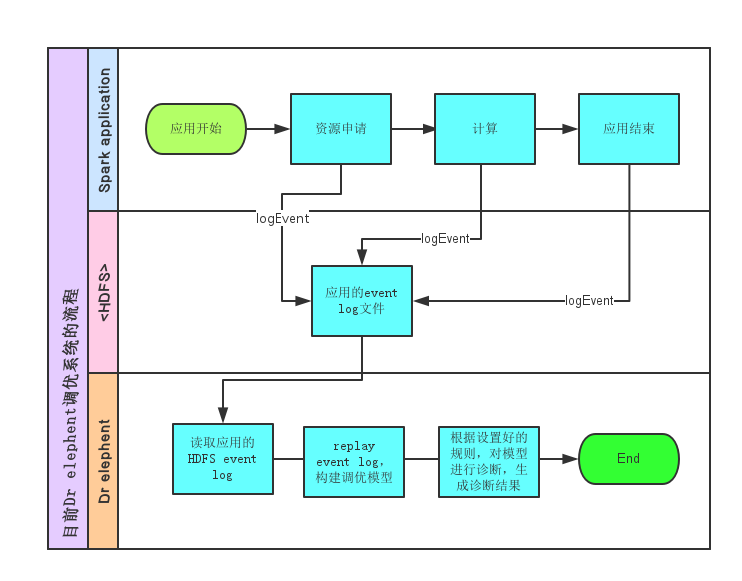
规则平台进行配置, 有了采集数据, 根据规则对相关指标定级, 并以不同颜色区分展示,并给出相关诊断意见.
总结
本文主要根据平台用户平常提交的spark任务思考,调研引入Dr. Elephant, 通过阅读Dr 相关源码, 明白Dr 执行整体流程并对代码进行改造,适配我们的需求.最终转变为平台产品来对用户的Spark任务进行诊断并给出相关调优建议.
参考
https://github.com/linkedin/dr-elephant
https://blog.csdn.net/qq475781638/article/details/90247623
最新文章
- iOS - 类扩展与分类的区别
- 运维自动化轻量级工具pssh
- Centos搭建Python+Nginx+Tornado+Mysql环境[转载]
- JavaScript 回忆录
- Golang tool:include spider library,image library and some other db library such as mysql,redis,mogodb,hbase,cassandra
- 《C标准库》——之<stddef.h>
- EditText 属性
- python module的结构
- Delphi线程池
- grunt实用总结
- 修改NavigationBar样式
- CentOS6.7下使用非root用户(普通用户)编译安装与配置mysql数据库并使用shell脚本定时任务方式实现mysql数据库服务随机自动启动
- 解析:type t_string is table of varchar2(32767) index by binary_integer
- 生成透视列之COALESCE
- Angular2+实现右键菜单的重定义--contextmenu
- 最容易理解的对卷积(convolution)的解释
- 如何相互转换逗号分隔的字符串和List【转】
- redis、mysql、mongdb的比较
- Spring Aop: 关于继承和execution target this @annotation
- C# 给枚举类型增加一个备注特性
热门文章
- 大数据学习day22------spark05------1. 学科最受欢迎老师解法补充 2. 自定义排序 3. spark任务执行过程 4. SparkTask的分类 5. Task的序列化 6. Task的多线程问题
- 从面试官的角度,聊聊java面试流程
- Oracle中常用的系统表
- AOP中ProceedingJoinPoint获取目标方法,参数,注解
- SpringMVC(1):SpringMVC入门
- 【Java 8】Predicate详解
- Java Log4j 配置文件
- 接下来一段时间会对大家进行网络通信的魔鬼训练-理解socket
- java 多线程 :ThreadLocal 共享变量多线程不同值方案;InheritableThreadLocal变量子线程中自定义值,孙线程可继承
- 200行代码理解Asp.Net Core