[Spark] 01 - What is Spark
大数据
云计算概念
一、课程资源
厦大课程:Spark编程基础(Python版)
优秀博文:Spark源码分析系列(目录)
二、大数据特点
大数据4V特性
Volumn, Variety, Velocity, Value。
思维方式
通过数据发现问题,再解决问题。
全样分析,精确度的要求降低。
三、分布式方案
分布式存储
- 分布式文件系统:GFS/HDFS
- 分布式数据库:BigTable/HBase
- NoSql
分布式处理
- map/reduce【面向批处理】
- Spark【面向批处理】
- Flink
四、大数据计算模式
(1) 批处理计算
(2) 流计算
S4, Flume, Storm
(3) 图计算
GIS系统,Google Pregel, 有专门图计算的工具。
(4) 查询分析计算
Google Dremel, Hive, Cassandra, Impala等。
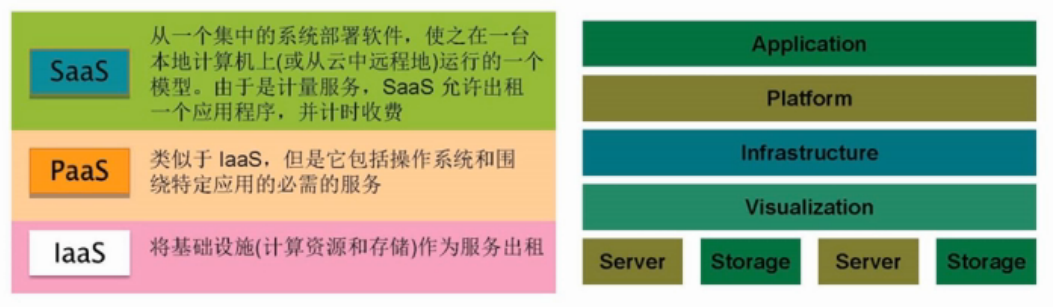
五、大数据服务
SaaS, PaaS, IaaS
六、大数据分析环境
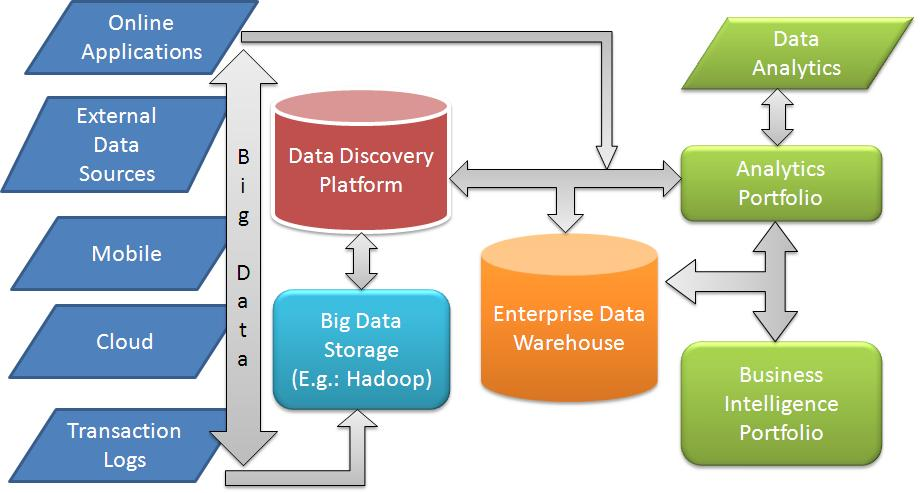
流程:ETL (Spark) --> Dataware house (HDFS, Cassandra, HBase) --> Data analysis (Spark) --> Reporting & visualization
Lambda 架构:同时处理“实时”和“离线”的部分。
生态系统
一、Hadoop 生态系统
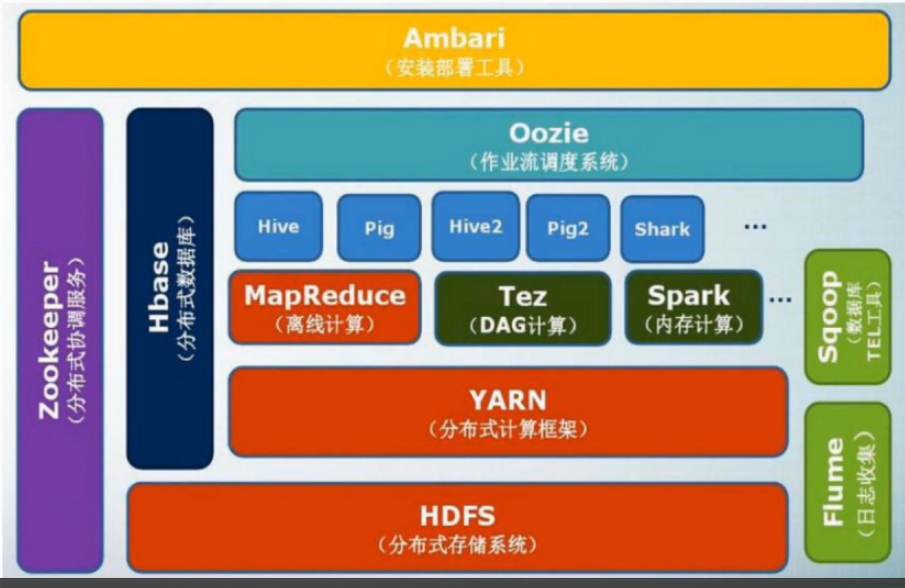
| Tez | 构建有向无环图。 |
| Hive | 数据仓库,用于企业决策,表面上写得是sql,实际转换为了mapReduce语句。 |
| Pig | 类似sql语句的脚本语言,可以嵌套在其他语言中。(提供轻量级sql接口) |
| Oozie | 先完成什么,再完成什么。 |
| Zookeeper | 集群管理,哪台机器是什么角色。 |
| Hbase | 面向列的存储,随机读写;HDFS是顺序读写。 |
| Flume | 日志收集。 |
| Sqoop | 关系型数据库导入Hadoop平台。主要用于在Hadoop(Hive)与传统的数据库间进行数据的传递 |
| Ambari | 部署和管理一整套的各个套件。 |
二、Spark 生态系统

三、Flink
Java派别的Spark竞争对手。
基于“流处理”模型,实时性比较好。
Goto: 第一次有人把Apache Flink说的这么明白!
四、Beam
翻译成Flink or Spark的形式,类似于 Keras,试图统一接口。
Goto: Apache Beam -- 简介
引入 Spark
一、年轻
二、代码简洁
// word count.
rdd = sc.textFile("input.csv") wordCounts = rdd.map(lambda line: line.split(",")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda x, y: x+y).collect()
Spark的设计与运行原理
原理分析
一、基本概念
(1) RDD 数据抽象
RDD: 弹性分布式数据集(内存中),存储资料的基本形式。
分区数量可以 动态变化。
(2) DAG 有向无环图
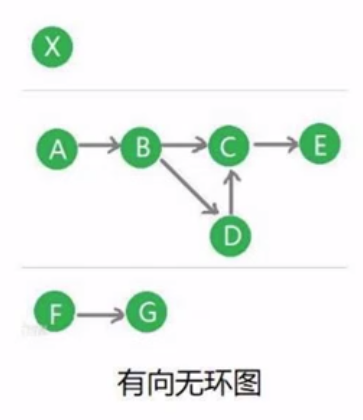
(3) 运行在Executor上的工作单元 - Task
“进程”派生出很多“线程”,然后完成每一个任务。
Executor进程,驻留在每一个work node上的。
(4) 作业 - Job
一个作业包含多个RDD。
一个作业分解为多组任务,每一组的集合就是 Stage。
(5) Applicaiton
用户编写的spark程序。
二、鸟瞰图
基本运行框架。其中,Cluster Manager: spark自带的、Yarn等等。
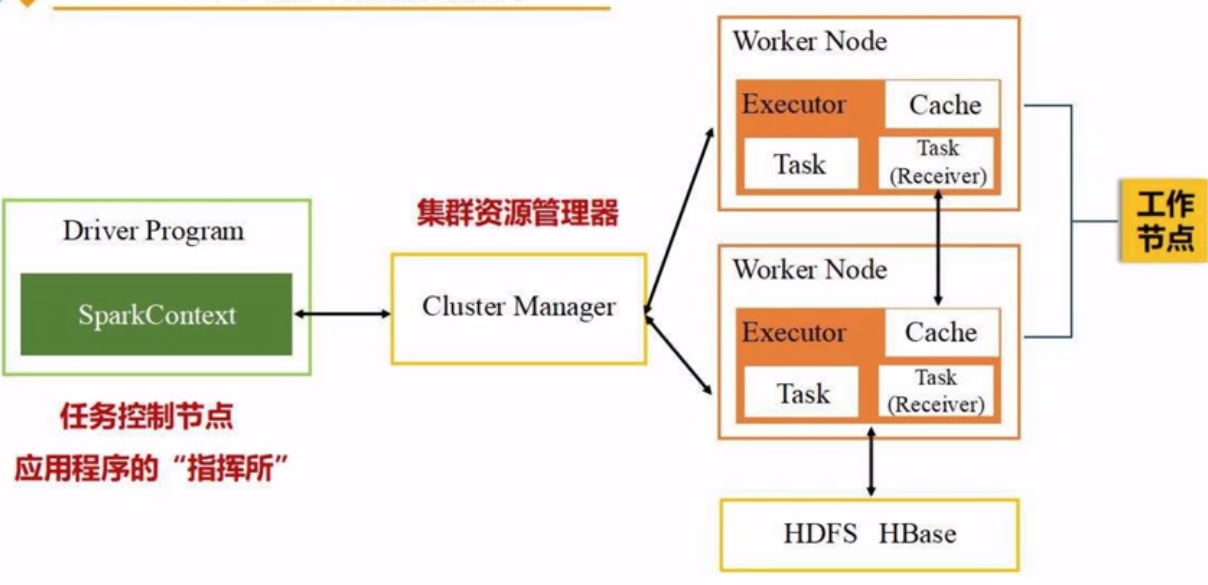
三、申请资源过程
- 主节点 Spark Driver (指挥所, 创建sc即指挥官) 向 Cluster Manager (Yarn) 申请资源。
- 启动 Executor进程,并且向它发送 code 和 files。
- 应用程序在 Executor进程 上派发出线程去执行任务。
- 最后把结果返回给 主节点 Spark Driver,写入HDFS or etc.
四、运行基本流程
SparkContext解析代码后,生成DAG图。
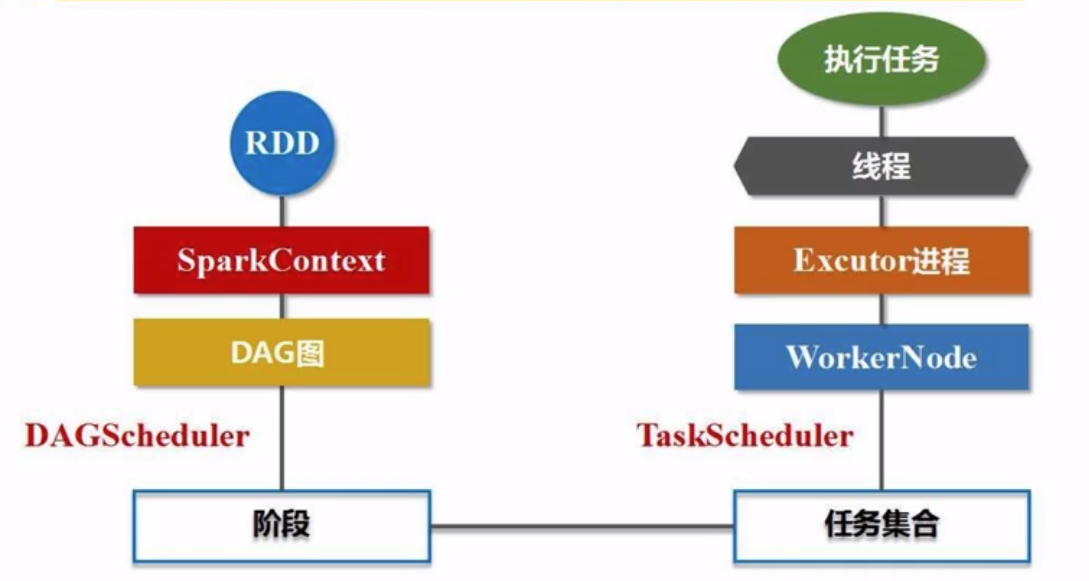
DAG Scheduler
一、 Resilient Distributed Dataset (RDD)
(1) 高度受限 - 只读
本质是:一个 "只读的" 分区记录集合。
Transformation 过程中,RDD --> RDD,期间允许“修改”。
(2) 两种“粗粒度”操作
* Action类型。(触发计算得到结果)
* Transformation类型。(只是做了个意向记录)
"细粒度" 怎么办?例如:网页爬虫,细粒度更新。
因为提供了更多的操作,这些 “操作的组合” 也可以做“相同的事情“。
(3) 更多的"操作"
比如:map, filter, groupBy, join
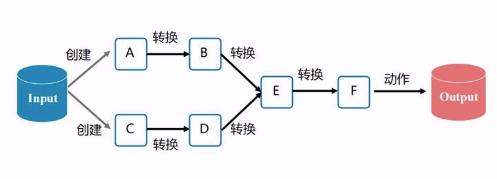
之所以”高效“,是因为管道化机制。所以不需要保存磁盘,输入直接对接上一次输出即可。
(4) 天然容错机制
数据复制,记录日志(关系数据库),但,这样开销太大了。
Spark是天然容错性:DAG,可以根据前后节点反推出错误的节点内容。
二、RDD优化
根据 “宽依赖” 划分 “阶段” 的过程。
“宽依赖” 是啥
一个父亲对多个儿子。
例如:groupByKey, join操作。
要点:若是宽依赖,则可划分为多个”阶段“。
“阶段” 如何划分
因为这样符合优化原理。

为何要划分 “阶段”
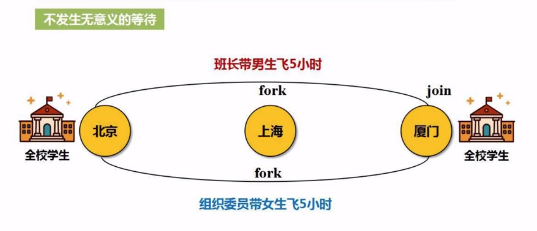
(a) 窄依赖:不要”落地“,好比不用”写磁盘“,形成管道化的操作。
原本的 "窄依赖" 操作流程。
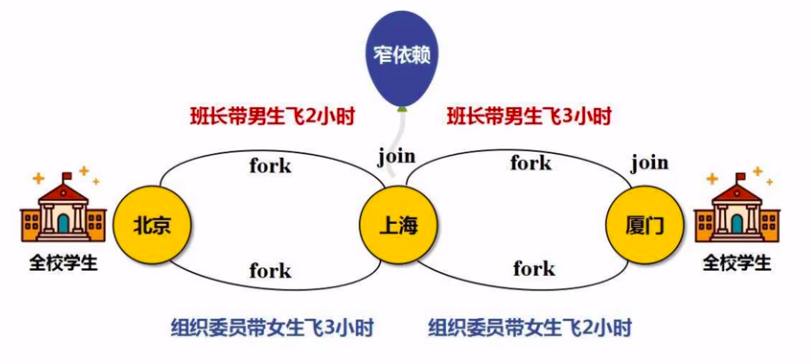
优化后的操作流程。
(b) 宽依赖:就会遇到shuffle操作,意味着“写磁盘”的一次操作。
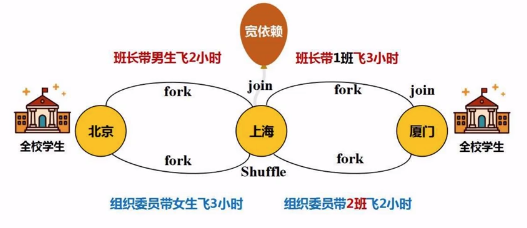
划分阶段实战
“窄依赖”:多个父亲对应一个儿子,不会阻碍效率。
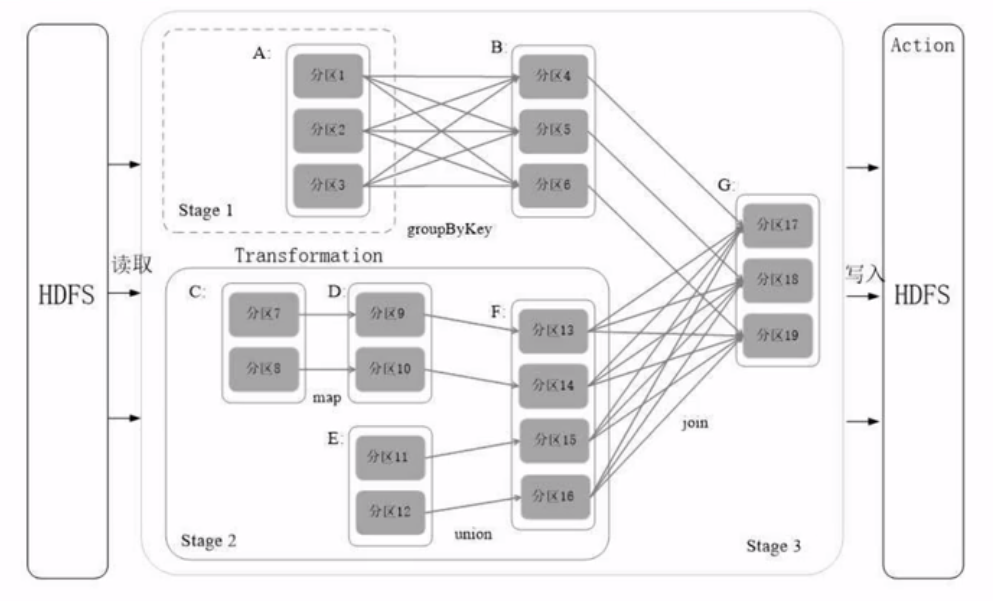
内存有限的情况下 Spark 如何处理 T 级别的数据?
Ref: https://www.zhihu.com/question/23079001
/* implement */
End.
最新文章
- COGS182 [USACO Jan07] 均衡队形[RMQ]
- Bootstrap Table使用分享
- SqlServer2008R2执行Sql语句,快捷键
- java 部署服务报:Bad version number in .class file
- Android禁止横屏竖屏切换
- malloc、calloc、realloc的区别
- Mysql用户密码设置修改和权限分配
- The method getContextPath() is undefined for the type ServletContext
- JSP小实例--计算器
- Guava API学习之Optional 判断对象是否为null
- 笔记--cocos2d-x 3.0 环境搭建
- Java-Math
- OpenSUSE 13.2安装Texlive2014+Texmaker+Lyx
- 记录一些日常windows命令或操作技巧
- npm 传入参数
- [PHP]算法-替换空格的PHP实现
- [No0000178]改善C#程序的建议1:非用ICloneable不可的理由
- cxf怎样提高webservice性能,及访问速度调优
- 用setup.py安装第三方包packages
- 20155209 2016-2017-2 《Java程序设计》第八周学习总结
热门文章
- 解决HTML5实现一键拨号、一键发短信及上传头像兼容性问题
- python学习笔记(2)--列表、元组、字符串、字典、集合、文件、字符编码
- 利用递归,反射,注解等,手写Spring Ioc和Di 底层(分分钟喷倒面试官)了解一下
- SpringBoot中关于Shiro权限管理的整合使用
- .Net使用HttpClient以multipart/form-data形式post上传文件及其相关参数
- 非域环境下SQL Server搭建Mirror(镜像)的详细步骤
- 从入门到实践:创作一个自己的 Helm Chart
- IDEA-Maven项目的jdk版本设置
- 手把手教你用深度学习做物体检测(七):YOLOv3介绍
- hdu-6681 Rikka with Cake