第四章 朴素贝叶斯法(naive_Bayes)
2024-08-29 21:42:20
总结
- 朴素贝叶斯法实质上是概率估计。
- 由于加上了输入变量的各个参量条件独立性的强假设,使得条件分布中的参数大大减少。同时准确率也降低。
- 概率论上比较反直觉的一个问题:三门问题:由于主持人已经限定了他打开的那扇门是山羊,即已经有前提条件了,相对应的概率也应该发生改变,具体公式啥的就不推导了。这个问题与朴素贝叶斯方法有关系,即都用到了先验概率。
- 其中有两种方法来计算其概率分布。
- 极大似然法估计:

- 贝叶斯估计:无法保证其中所有的情况都存在,故再求其条件概率的时候加上一个偏置项,使其所有情况的条件概率在所给的有限的训练集上都不为0。

- 极大似然法估计:
- 下面对极大似然法和贝叶斯估计进行推导。(习题内容)习题内容可能要拖一拖了,枯辽
- 下面是代码实现,代码注释还是挺清楚的
# encoding=utf-8 import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import time def binaryzation(array):
#二值化
# 大于50的为1,小于50的为0,二值化后,参数总量从255降到了2
array[array[:, :] <= 50] = 0
array[array[:, :] > 50] = 1
return array def read_data(path):
raw_data = pd.read_csv(path, header=0)
data = raw_data.values imgs = data[:, 1:]
labels = data[:, 0]
imgs = binaryzation(imgs) # 选2/3的数据作为数据集,1/3的数据作为测试集
tra_x, test_x, tra_y, test_y = train_test_split(imgs, labels, test_size=0.33, random_state=2019526)
return tra_x, test_x, tra_y, test_y def naive_Bayes(x, y, class_num=10, feature_len=784, point_len=2, lamba=1):
"""
:param x: 学习的数据集
:param y: 学习的标签
:param class_num: y的类别的数目
:param feature_len: 每个训练数据的特征向量有多少维
:param point_len: 每个训练集数据的特征向量有多少种取值情况
:return: 先验概率和条件概率
"""
# 这里我们使用贝叶斯估计法来做
prior_probability = np.zeros(class_num)
conditional_probability = np.zeros((class_num, feature_len, point_len))
# 先得到每个对应的数目,计算先验概率
for i in range(10):
prior_probability[i] += len(y[y[:] == i]) # 计算条件概率
for i in range(class_num):
# 取出x中label对应数据为i的点
data_ith = x[y == i]
for j in range(feature_len):
for k in range(point_len):
# 在之前的数据中取出第j列为1,或者为0的点
conditional_probability[i, j, k] += len(data_ith[data_ith[:, j] == k]) + lamba
conditional_probability[i, :, :] /= (prior_probability[i] + point_len * lamba) prior_probability += lamba
prior_probability /= (len(y) + class_num * lamba) return prior_probability, conditional_probability def predict(pp, cp, data, class_num=10,feature_len=784):
"""
预测
:param pp: prior_probability
:param cp: conditional_probability
:param data: 输入数据
:return: 预测结果
"""
pre_label = np.zeros(len(data)+1)
for i in range(len(data)):
max_possibility = 0
max_label = 0
for j in range(class_num):
tmp=pp[j]
for k in range(feature_len):
tmp*=cp[j,k,data[i,k]]
if tmp>max_possibility:
max_possibility=tmp
max_label=j
pre_label[i]=max_label
return pre_label if __name__ == '__main__':
time_1=time.time()
tra_x, test_x, tra_y, test_y = read_data('data/Mnist/mnist_train.csv')
time_2=time.time()
prior_probability, conditional_probability = naive_Bayes(tra_x, tra_y, 10, 784, 2, 1)
time_3=time.time()
pre_label = predict(prior_probability, conditional_probability, test_x, 10,784)
cous=0
for i in range(len(test_y)):
if pre_label[i]==test_y[i]:
cous+=1
print(cous/len(pre_label))
time_4=time.time()
print("time of reading data: ",int(time_2-time_1))
print("time of getting model: ",int(time_3-time_2))
print("time of predictting: ",int(time_4-time_3))
这个是他的准确率及所消耗的时间
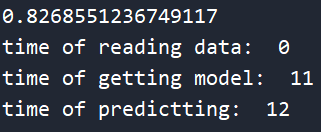
反思:
其实这个准确率低是可以修正的将point_len修改的大点应该就可以提升一点准确率了,因为在我的代码里对每个像素点的划分太过于大了,大于50就为1,小于50就为0,可以分成3段或者更多。
最新文章
- nginx 配置https upstream 跳转失败
- 区间dp
- AIX 环境下遇到Device Busy问题
- oracle 学习笔记
- 利用UIBezierPath实现一个带圆角的视图
- Spark源码学习1
- HTML禁止使用右键
- SSIS从理论到实战,再到应用(6)----SSIS的自带日志功能
- 猫学习IOS(十五)UI以前的热的打砖块游戏
- layer ifram 弹出框
- Android 控件布局常用属性
- 如何让Mac、Windows可以互相远程
- 剑指offer面试题6 重建二叉树(c)
- 如何自动增加和从代码读取Xcode项目的版本号
- Web Application Security(Web应用安全)
- 产品经理说| AIOps 让告警变得更智能 (下)
- 大杂烩 -- ArrayList的动态增长 源码分析
- Android---------------Handler的学习
- object Add(object Before, object After, object Count, object Type);
- 【二】调通单机版的thrift-C++版本