AppBoxFuture: 123挨个站-数据按序存储
2024-09-08 16:28:41
最近几天在优化存储的编码规则,顺带把之前设计了但未实现的倒排序一并实现了。由于所有数据(元数据、实体、索引等)都映射至RocksDB的Key-Value存储,所以必须扩展RocksDB的自定义比较器(Comparator)来实现自定义Key的排序规则。存储层涉及到需要自定义排序的主要是分区元数据、实体数据以及索引,下面分别说明:
一、分区排序
在大表分区设置分区键及其规则时,可以根据需要设置每个分区键的排序,如下图所示:

如果分区键规则是Hash,设置排序将被忽略
二、实体排序
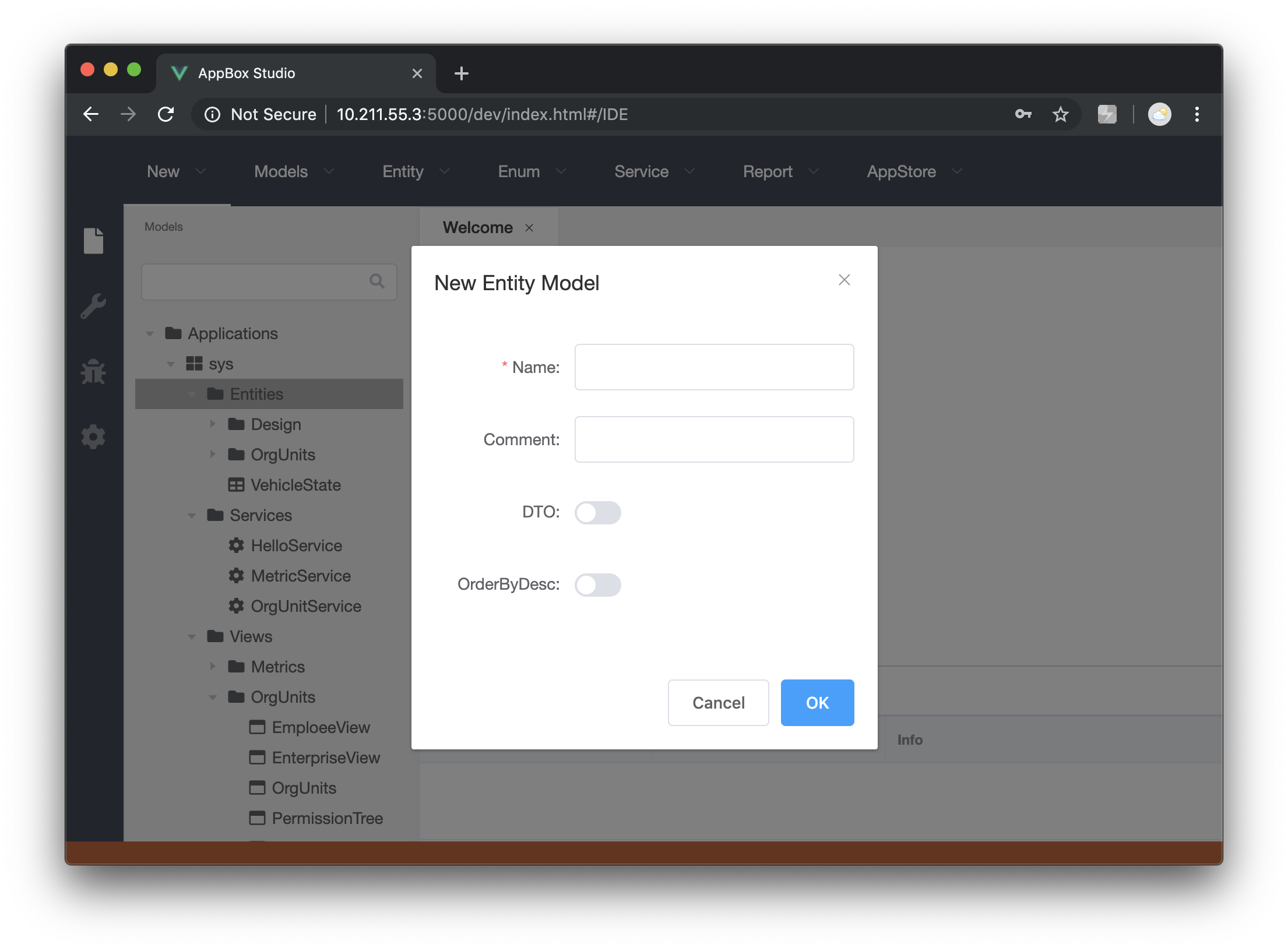
在新建实体模型时可以根据需要指定主键排序,这里需要注意的是不同于传统数据库可以指定任意字段作为主键,实体的主键是128位的顺序Guid,包括时间戳及集群节点等编码信息,所以这里的实体排序指的是按时间戳正倒排。如果实体是如订单等跟时间相关的数据类型,建议设置为倒排以方便扫描最近的实体数据。具体参考下图设置:
三、索引排序
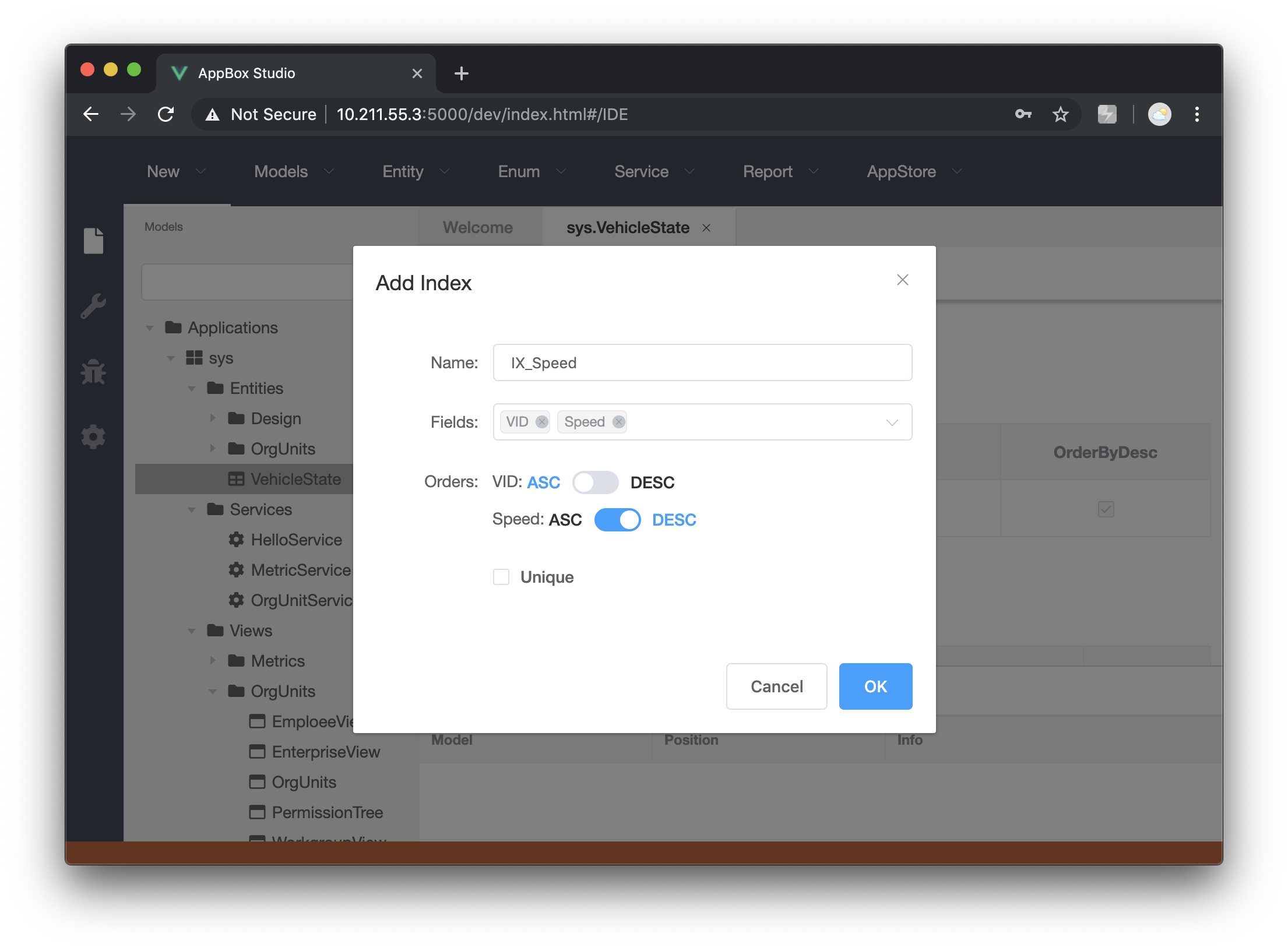
在添加索引时可以根据需要设置每个索引键的排序,如下图所示:
四、排序测试
我们来做个简单的测试:
新建一个分区表VehicleState按时间降序,加入字段VID Int32, Speed Int32,设置分区键为VID按降序;
新建一个服务填充3 * 3条数据,如下示例代码:
public async Task<object> Insert()
{
return await SimplePerfTest.Run(3, 3, async (i, j) =>
{
var obj = new Entities.VehicleState(i + 1);
obj.Speed = 10 + j;
await EntityStore.SaveAsync(obj);
});
}
通过dbscan工具验证分区元数据排列顺序,如下图所示红框内为3个分区的排列顺序:

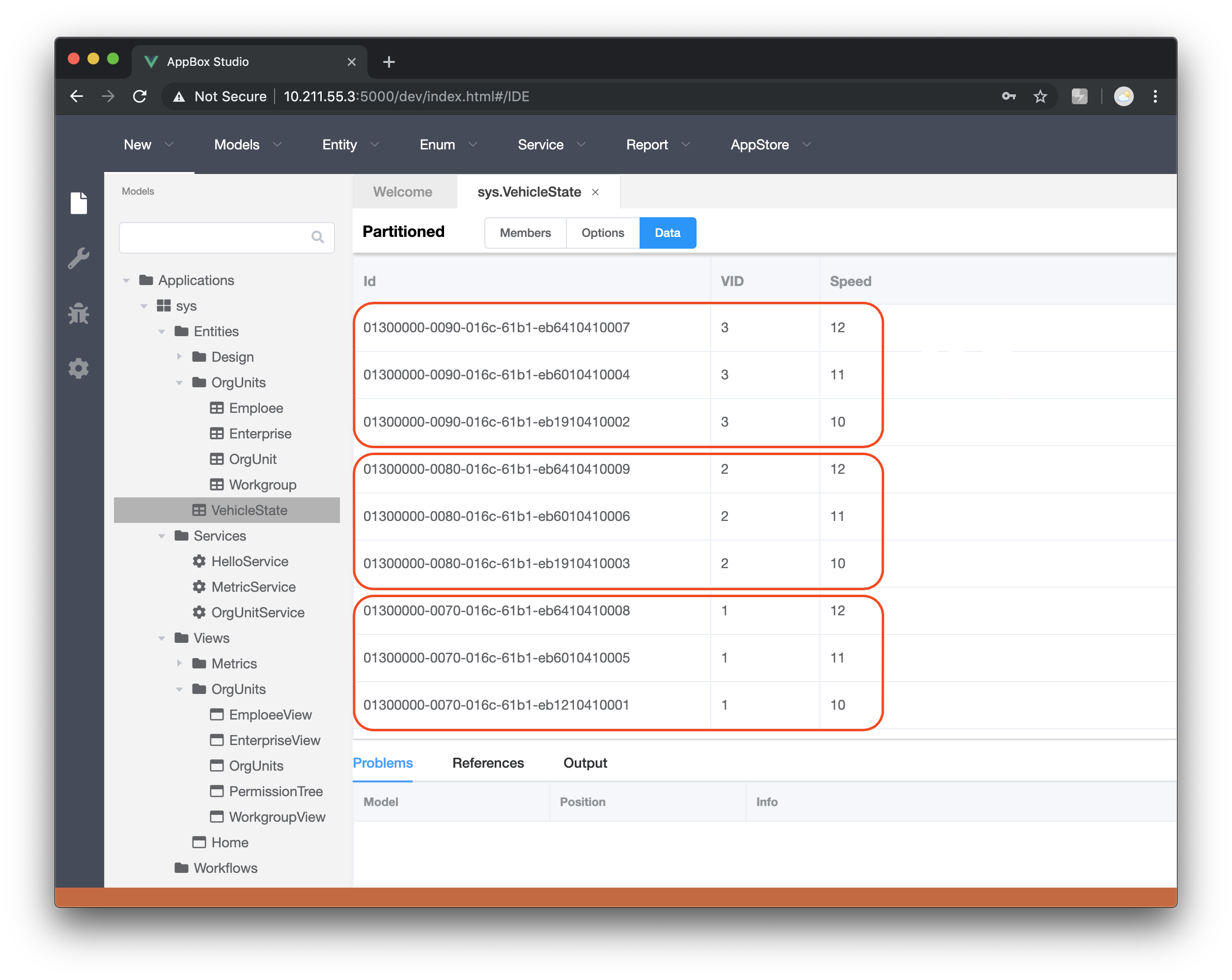
通过实体模型设计界面内的数据浏览验证排列顺序,如下图所示3个红框为3个分区的排列顺序:
五、本篇小结
经过这次编码规则优化,存储引擎的编码格式已基本定型,下一步按计划实现各项必须功能并加强存储引擎的测试,GitHub上的运行时也更新为新的编码格式,大家可安装测试。另码文不易,一边码代码一边码文更不易,作者需要您的支持请多多点赞推荐!
最新文章
- 安卓图标IconFont使用
- 第3章 Linux常用命令(2)_权限管理命令
- Hadoop学习笔记【Hadoop家族成员概述】
- Windows上python开发--2安装django框架
- CentOS 7下编译FreeSWITCH 1.6
- UVA 4080 Warfare And Logistics 战争与物流 (最短路树,变形)
- 对unsigned int和int进行移位操作的区别
- PHP中对mysql预编译查询语句的一个封装
- IE浏览器-在Win7系统的安装和卸载
- Divide Sum 比赛时竟然想不出。。。。。。。
- [HNOI2004]L语言
- MATLAB一元线性回归分析
- 使用h2数据库
- 架构师成长之路2.1-PXE+Kickstart原理
- 到底什么时候才需要在ObjC的Block中使用weakSelf/strongSelf
- Python拷贝文件脚本
- UI设计规范:单选按钮 vs 复选框,没那么简单
- hdu-1173(最短距离)
- bcdiv bcmul
- linux C API连接并查询mysql5.7.9