scrapy抓取斗鱼APP主播信息
如何进行APP抓包
首先确保手机和电脑连接的是同一个局域网(通过路由器转发的网络,校园网好像还有些问题)。
1.安装抓包工具Fiddler,并进行配置
Tools>>options>>connections>>勾选allow remote computers to connect
2.查看本机IP
在cmd窗口(win+R快捷键),输入ipconfig,查看(以太网)IP地址。
3.配置手机端。
手机连网后(和电脑端同一局域网),打开手机浏览器并访问:http://ip:8888(ip是你第二步查看到的IP地址, 8888端口是Fiddler默认端口),
有些浏览器打不开网页,换一下浏览器就行。
如果访问成功,会出现一个网页:
4.下载证书
点击FiddlerRoot certificate,下载证书。如果不下载证书的话,只能抓到http请求,抓不到https请求。
5.安装证书
部分手机可以直接点击安装
部分手机需要通过:
设置>>wifi(或WLAN)>>高级设置>>安装证书>>选中下载好的FiddlerRoot.cer>>确定
或:
设置>>更多设置>>系统安全>>从存储设备安装
安装后,可以按照自己的意愿,给证书起一个名字,例如Fiddler,确定后会显示安装完成!
6.设置手机代理

手机设置代理后,打开Fiddler,接下来在手机端打开app或者浏览器,所有通过手机发送的请求都会被Fiddler抓取。
scrapy框架下载图片
Scrapy用ImagesPipeline类提供一种方便的方式下载和存储图片(需要PIL库支持)。
主要特征:
- 将下载图片转化为通用的jpg和rgb格式
- 避免重复下载
- 缩略图生成
- 图片大小过滤
工作流程:
- 抓取一个item,将图片的urls放入image_urls字段
- 从Spider返回的item,传递到 Item Pipeline
- 当Item传递到ImagePipeline,将调用scrapy调度器和下载器完成image_urls中的url调度和下载。ImagePipeline会自动高优先级抓取这些url,同时,item会被锁定直到图片抓取完毕才解锁
- 图片下载成功后,图片下载路径,url和校验信息等会被填充到images字段中
scrapy抓取斗鱼主播图像
ImagePipeline简介
首先介绍一下图片下载中的ImagePipeline类中的两个重要方法。在自定义的ImagePipeline类中要重写:
get_media_requests(item, info)和item_completed(results, items, info);其中,正如工作流所述,Pipeline从item中获取图片的urls并下载,
所以必须重载get_media_requests,并返回一个Request对象,这些请求对象将被pipelines处理
下载完成后,结果发送发哦item_complete方法,下载结果为一个二元组的list, 每个元组包含:
(success, image_info_or_failure),其中:
success: bool值,true表示下载成功
image_info_or_error: 如果success为True,则该字典包含以下键值对:{path:本地存储路径, checksum:校验码}
分析及编码
通过Fiddler抓包工具分析,请求连接为:http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=0,其中
offset为变量,每次翻页增加20。
首先,使用命令创建项目
scrapy startproject Douyu
来到items.py文件,编写需要抓取的字段如下:
# -*- coding: utf-8 -*- import scrapy class DouyuItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() # 图片链接
image_link = scrapy.Field() # 图片保存路径
image_path = scrapy.Field() # 主播名
nick_name = scrapy.Field() # 房间号
room_id = scrapy.Field() # 所在城市
city = scrapy.Field() # 数据源
source = scrapy.Field()
明确抓取目标后,生成爬虫,开始编写爬虫逻辑
scrapy genspider douyu douyucdn.com # 生成爬虫
编写爬虫逻辑之前,在下载中间件中,给每个请求添加头部信息:
# -*- coding: utf-8 -*- # Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals
from Douyu.settings import USER_AGENTS as ua
import random class DouyuSpiderMiddleware(object):
def process_request(self, request, spider):
"""
给每一个请求随机分配一个代理
:param request:
:param spider:
:return:
"""
user_agent = random.choice(ua)
request.headers['User-Agent'] = user_agent
然后来到spiders文件夹下的爬虫文件,开始编写爬虫逻辑:
# -*- coding: utf-8 -*-
import json
import scrapy
from Douyu.items import DouyuItem class DouyuSpider(scrapy.Spider):
name = 'douyu'
allowed_domains = ['douyucdn.cn'] offset = 0 # 请求url
base_url = "http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset="
start_urls = [base_url + str(offset)] def parse(self, response): # 手机端斗鱼返回的是json格式的数据,所有数据都在data中
# 直接从请求响应体中获取数据
node_list = json.loads(response.body)['data'] # 如果拿不到数据,说明已经爬取完所有翻页
if not node_list:
return # 对具体数据进行解析
for node in node_list: # 数据保存
item = DouyuItem()
item['image_link'] = node['vertical_src']
item['nick_name'] = node['nickname']
item['room_id'] = node['room_id']
item['city'] = node['anchor_city'] yield item # 实现翻页
self.offset += 20
yield scrapy.Request(self.base_url + str(self.offset), callback=self.parse)
编写完爬虫逻辑后,可以开始编写图片下载逻辑了,来到pipelines文件:
# -*- coding: utf-8 -*-
import os
import scrapy # scrapy下载图片专用管道
from scrapy.pipelines.images import ImagesPipeline
# 在setting中指定图片存储路径
from Douyu.settings import IMAGES_STORE class ImageSourcePipeline(object): # 添加数据源
def process_item(self, item, spider):
item['source'] = spider.name
return item class DouyuImagePipeline(ImagesPipeline): # 发送图片链接请求
def get_media_requests(self, item, info):
# 获取item数据的图片链接
image_link = item['image_link'] # 发送图片请求,响应会保存在settings中指定的路径下(IMAGES_STORE)
try:
yield scrapy.Request(url=image_link)
except:
print(image_link) def item_completed(self, results, item, info):
"""
:param results: 下载图片结果,包含一个二元组(下载状态,图片路径)
:param item:
:param info:
:return:
"""
# 取出每个图片的原本路径
# path为设定的图片存储路径
image_path = [x['path'] for ok, x in results if ok] # 默认保存当前图片的路径
old_name = IMAGES_STORE + '\\' + image_path[0] # 新建当前图片路径,因为默认路径有一些不需要的东西
new_name = IMAGES_STORE + '\\'+item['nick_name'] + '.jpg' item['image_path'] = new_name
try:
# 将原本路径的图片名,修改为新建的图片名
os.rename(old_name, new_name)
except:
print("INFO:图片更名错误!") return item
整体逻辑编写完成,在settings文件中分别打开中间件、管道等的注释信息,即可运行爬虫!
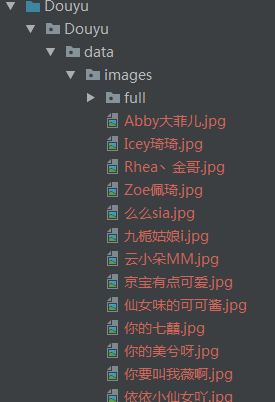
运行结果:
完整代码
参见:https://github.com/zInPython/Douyu
最新文章
- debain 8安装为知笔记(how to install wiznote in debain 8)
- RDIFramework.NET ━ 9.5 组织机构管理 ━ Web部分
- CGI、FastCGI 知识总结
- mysql数据库基础的简单操作指南
- Android混淆那些事儿
- nginx+tomcat安装配置
- 关于promise的详细讲解
- 清除Chrome浏览器的历史记录、缓存
- JDB与迭代
- css3 min-content,max-content,fit-content, fill属性
- day4-python基础-运算符
- Linux安装vsftpd组件
- Java-异常机制详解以及开发时异常设计的原则要求
- 【php写日志】php将日志写入文件
- python UI自动化实战记录四:测试页面1-pageobject
- Android之简易音乐播发器
- 【Android XML】Android XML 转 Java Code 系列之 Selector(2)
- (C#)Windows Shell 外壳编程系列3 - 上下文菜单(iContextMenu)(一)右键菜单
- 锚点自适应 map area coords
- Swift Perfect 基础项目
热门文章
- Java基础(十九)集合(1)集合中主要接口和实现类
- Java基础(十五)异常(Exception)
- vue-cli3没有config文件解决方案,在根目录加上vue.config.js文件
- hyper-v虚拟机上的centos多节点k8s集群实践
- 面向云原生的混沌工程工具-ChaosBlade
- Android自定义控件:自适应大小的文本控件
- spring session源码解析
- [AspNetCore 3.0 ] Blazor 服务端组件 Render, RenderFragment ,RenderTreeBuilder, CascadingValue/CascadingParameter 等等
- python学习之【第八篇】:Python中的函数基础
- 安全路径——最短路径树+dsu缩边