用Python写简单的爬虫
2024-08-29 01:48:13
准备:
1.扒网页,根据URL来获取网页信息
import urllib.parse
import urllib.request
response = urllib.request.urlopen("https://www.cnblogs.com")
print(response.read())
urlopen方法
urlopen(url, data, timeout)
url即为URL,data是访问URL时要传送的数据,timeout是设置超时时间
返回response对象
response对象的read方法,可以返回获取到的网页内容
POST方式
import urllib.parse
import urllib.request
values = {"username":"XXX","password":"XXX"}
data = urllib.parse.urlencode(values)
data = data.encode('utf-8')
url = "https://passport.cnblogs.com/user/signin?ReturnUrl=https://home.cnblogs.com/&AspxAutoDetectCookieSupport=1"
response = urllib.request.urlopen(url,data)
print(response.read())
GET方式
import urllib.parse
import urllib.request
values = {"itemCount":30}
data = urllib.parse.urlencode(values)
data = data.encode('utf-8')
url = "https://news.cnblogs.com/CommentAjax/GetSideComments"
data = urllib.parse.urlencode(values)
response = urllib.request.urlopen(url+'?'+data)
print(response.read())
2.正则表达式re模块
Python 自带了re模块,提供了对正则表达式的支持
#返回pattern对象
re.compile(string[,flag])
#以下为匹配所用函数
re.match(pattern, string[, flags]) #在字符串中查找,是否能匹配正则表达式
re.search(pattern, string[, flags]) #字符串的开头是否能匹配正则表达式
re.split(pattern, string[, maxsplit]) #通过正则表达式将字符串分离
re.findall(pattern, string[, flags]) #找到 RE 匹配的所有子串,并把它们作为一个列表返回
re.finditer(pattern, string[, flags]) #找到 RE 匹配的所有子串,并把它们作为一个迭代器返回
re.sub(pattern, repl, string[, count]) #找到 RE 匹配的所有子串,并将其用一个不同的字符串替换
re.subn(pattern, repl, string[, count])#返回 (sub(repl, string[, count]), 替换次数)
3.Beautiful Soup,是从网页抓取数据的库,使用时需要导入 bs4 库
4.MongoDB
使用的MongoEngine库
示例:
抓取博客园前20页数据,保存到MongoDB中
1.获取博客园的数据
request.py
import urllib.parse
import urllib.request
def getHtml(url,values):
data = urllib.parse.urlencode(values)
response_result = urllib.request.urlopen(url+'?'+data).read()
html = response_result.decode('utf-8')
return html def requestCnblogs(num):
print('请求数据page:',num)
url = 'https://www.cnblogs.com/mvc/AggSite/PostList.aspx'
values= {
'CategoryId':808,
'CategoryType' : 'SiteHome',
'ItemListActionName' :'PostList',
'PageIndex' : num,
'ParentCategoryId' : 0,
'TotalPostCount' : 4000
}
result = getHtml(url,values)
return result
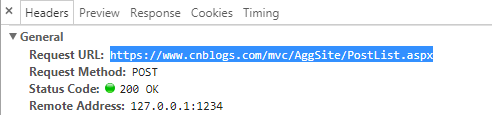
注:
打开第二页,f12,找到https://www.cnblogs.com/mvc/AggSite/PostList.aspx

2.解析获取来的数据
deal.py
from bs4 import BeautifulSoup
import request
import re
def blogParser(index):
cnblogs = request.requestCnblogs(index)
soup = BeautifulSoup(cnblogs, 'html.parser')
all_div = soup.find_all('div', attrs={'class': 'post_item_body'}, limit=20)
blogs = []
#循环div获取详细信息
for item in all_div:
blog = analyzeBlog(item)
blogs.append(blog)
return blogs def analyzeBlog(item):
result = {}
a_title = find_all(item,'a','titlelnk')
if a_title is not None:
result["title"] = a_title[0].string
result["link"] = a_title[0]['href']
p_summary = find_all(item,'p','post_item_summary')
if p_summary is not None:
result["summary"] = p_summary[0].text
footers = find_all(item,'div','post_item_foot')
footer = footers[0]
result["author"] = footer.a.string
str = footer.text
time = re.findall(r"发布于 .+? .+? ", str)
result["create_time"] = time[0].replace('发布于 ','')
return result def find_all(item,attr,c):
return item.find_all(attr,attrs={'class':c},limit=1)
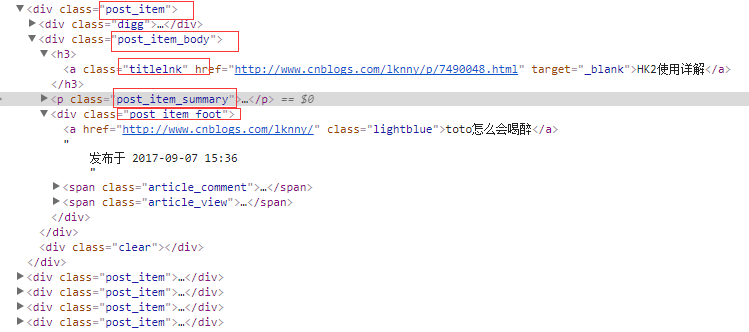
注:
分析html结构
3.将处理好的数据保存到MongoDB
db.py
from mongoengine import *
connect('test', host='localhost', port=27017)
import datetime
class Blogs(Document):
title = StringField(required=True, max_length=200)
link = StringField(required=True)
author = StringField(required=True)
summary = StringField(required=True)
create_time = StringField(required=True) def savetomongo(contents):
for content in contents:
blog = Blogs(
title=content['title'],
link= content['link'],
author=content['author'],
summary=content['summary'],
create_time=content['create_time']
)
blog.save()
return "ok" def haveBlogs():
blogs = Blogs.objects.all()
return len(blogs)
4.开始抓取数据
test.py
import db
import deal
print("start.......")
for i in range(1, 21):
contents = deal.blogParser(i)
db.savetomongo(contents)
print('page',i,' OK.')
counts = db.haveBlogs()
print("have ",counts," blogs")
print("end.......")

注:
当前使用的Python版本是3.6.1
可以在可视化工具中查看(可是化工具 介绍 )

最新文章
- 类Arrays
- 如何阻止h5body的滑动
- 解决:“java.lang.IllegalArgumentException: error at ::0 can't find referenced pointcut myMethod”问题!
- Mysql对用户操作加审计功能——初级版
- C#之Action
- 【转】WinForm不同版本覆盖安装
- springMVC中的Controller里面定义全局变量
- struts2 后台action向前端JSP传递参数的问题
- ios Swift 动手写
- WinEdt打开UTF-8文件乱码问题——ctex[转]
- Nginx 变量漫谈(八)
- eclipsecpp从可执行程序员中导入源代码并调试
- 走出MFC子类化的迷宫
- word2010无法打开文件时的一点对策
- 【好记性不如烂笔头】死锁之java代码
- ETL作业调度工具TASKCTL软件安装乱码问题解决
- win10系统搭建虚拟机:VMware Workstation Player 12环境+Ubuntu Kylin 16.04 LTS系统
- sublime 浏览器快捷键设置
- python笔记20-装饰器、作用域
- linux配置Anaconda python集成环境