ORACLE数据仓库学习记录
一、数据仓库安装
- 安装ORACLE DATABASE 10g Release 2
ORACLE数据库版本是:10.2.0.1.0(服务器)。执行基本安装(安装全部的组件)并创建示例数据库。
- 安装ORACLE Workflow Server 2.6.4
这个软件没有单独的下载,它位于ORACLE DATABASE 10g Release 2 Companion CD中,Companion CD需要到ORACLE网站下载对应的10g Release 2版本。ORACLE Workflow Server安装目录与ORACLE DATABASE 10g Release 2的安装目录相同。【备注:ORACLE DATABASE 10g Release 1(10.1.0.2.0)对应的WFS版本是2.6.3;ORACLE DATABASE 10g Release 2(10.2.0.1.0)对应的WFS版本是2.6.4,版本号不对应将无法安装!】
- 安装Oracle Warehouse Builder(OWB)10g Release 2
OWB版本是:10.2.0.1.0。
- 安装Analytic Workspace Manager(AWM 10203A)【可选安装】
这个也是需要到ORACLE网站下载。并且对版本有要求的。这个软件解压缩就可以了,没有安装程序。【备注:AWM 10203A需要ORACLE DATABASE 10.1.0.4.0及以上版本,10.1.0.2.0升级到10.1.0.4.0需要对应的升级包,这个升级包好像只有正版用户才能下载到。本文的AWM 10203A可以与ORACLE DATABASE 10g Release 2一起使用,但是不能与ORACLE DATABASE 10g Release 1一起使用!】
二、数据仓库配置
- 配置ORACLE数据库
- 执行数据库基本的配置操作。
- 配置Oracle Workflow Server2.6.4
- Windows平台下的配置如下:在DOS命令行窗口下,在Oracle DB 10G安装路径下,cd wf\install,运行"wfinstall"【JAVA环境变量必须配置正确】
- 在下图中输入以下几项:
- 工作流账户:owf_mgr(缺省值,如果从未配置过workflow,可以采用此缺省值,否则可以更改此名称,或者利用Enterprise Manager删除owf_mgr用户),建议使用默认值
- 工作流口令:上述用户的口令如"oracle"
- sys口令:在创建数据库时输入的数据库管理员口令如"oracle"
- TNS连接描述符:host_name:port_number:oracle_sid
- 提交
- 增加用户权限以及添加中文支持
- 在Enterprise Manager中,为Workflow管理员用户如OWF_MGR添加"Execute Any Procedure"权限,添加"Create any job"。
或者使用SQLPLUS完成:
sqlplus "/as sysdba"
sql>grant execute any procedure to owf_mgr
sql>grant create any job to owf_mgr
- 如果是中文,需要在Work Flow管理员下运行如下SQL:
OracleDB_Install_Path\wf\admin\sql\wfnlena.sql
输入以下参数:ZHS(Language_Code) Y(Y/N)
- 配置OWB,运行Repository Assistant
- Warehouse Builder->Administration->Repository Assistant
- 选择"基本安装"
- 输入SYSDBA权限的数据库用户的数据库连接信息
- 输入资料档案库用户信息(资料档案库用户设置为owb)
- 输入资料档案库所有者信息(资料档案库所有者设置为owb_owner)
- 创建目标用户
- 利用资料档案库所有者(owb_owner)登录Designer Center
- 选择"全局浏览器(global browser)"-〉"安全性(security)"-〉"用户(users)",右键"新建"
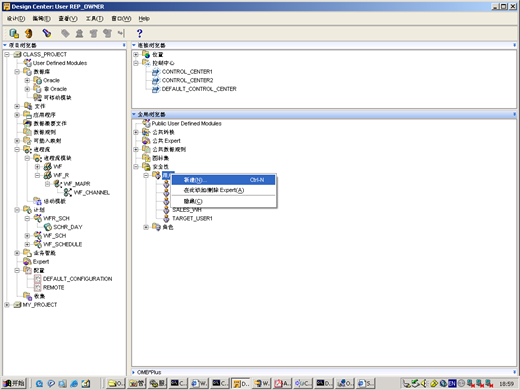
- 目标用户可以从现有数据库用户中选择,也可以重新创建(create db user)
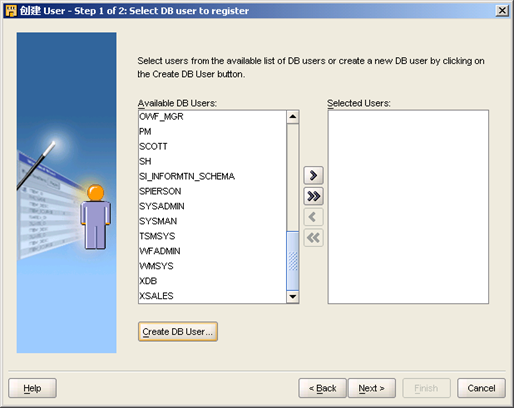
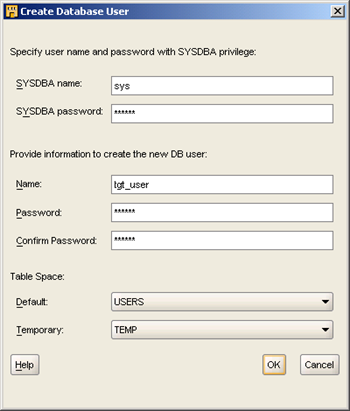
- 选择"Create DB User"。输入SYSDBA用户名和口令,以及目标用户的用户名和口令,选择使用的表空间,选择"OK"
- 新建用户出现在Selected Users中,"Next"
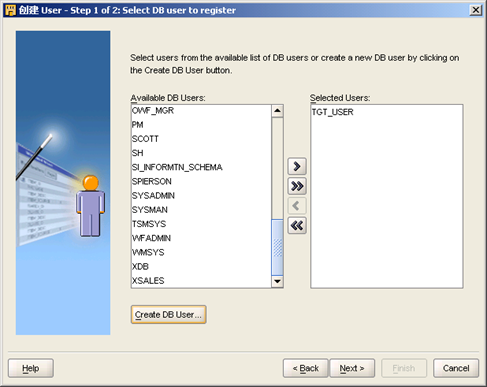
- 选择上"Used as target schema"
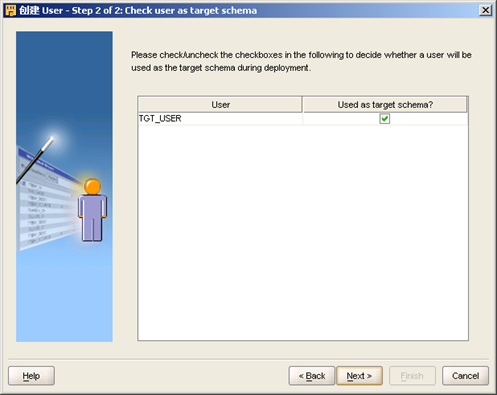
直至完成
- 权限分配
- 工作流用户(本例是owf_mgr)要分配数据仓库所有者角色,owb_o_owb_owner,否则工作流对象无法部署【ORACLE官方文档中并没有这个说明!但是这一步必不可少】
- 数据仓库目标用户(本例是tgt_user),需要分配select any table权限,否则映射对象无法部署【ORACLE官方文档中并没有这个说明!但是这一步必不可少】
三、数据仓库设计和ETL
- OWB简介
- OWB主要内容
OWB主要包含一个"设计中心"和一个"控制中心"。"设计中心"负责数据仓库的维、立方、映射、工作流等的设计。"控制中心"负责对"设计中心"中的对象进行部署,对工作流执行调度等。
- OWB设计流程
设计中心:
- 新建"项目(Project)"
- 定义"数据源模块(Module)"
- 定义"目标数据模块(Module)"
- 设计"事实表"的"映射(Mapping)"
- 设计"维(Dimension)"
- 设计"维(Dimension)"的"映射(Mapping)"
- 设计"立方(Cube)"
- 设计"立方(Cube)"的"映射(Mapping)"
- 设计"映射(Mapping)"时可能用到的"转换"
- 设计"进程流(Process Flow)"确定映射运行的先后顺序
- 设计"计划(Schedule)"
- "配置(Configure)"映射和工作流,添加不同映射和工作流的"计划",部署后会形成"工作(Job)"
控制中心管理器:
- 注册"位置(Location)"
- 部署对象
- 作业执行与调度
- 在"设计中心"(Design Center)中设计ETL
- 进入Design Center
- 开始-〉程序-〉Oracle – OWBHOME名称-〉Warehouse Builder-〉Design Center
- 新建"项目(Project)"
- "项目浏览器"空白处右键,选择"新建"
- 按照向导,输入项目名称如test_project,"确定"
- 定义"数据源模块(Module)"
- 建立一个Oracle表的数据源,在刚才建立的"项目名称-数据库-Oracle"上,右键"新建"
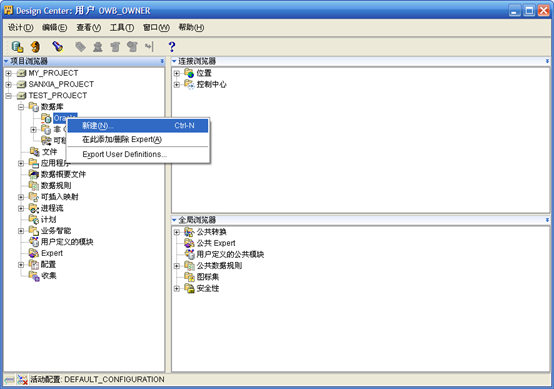
- 按照向导创建数据源Oracle模块
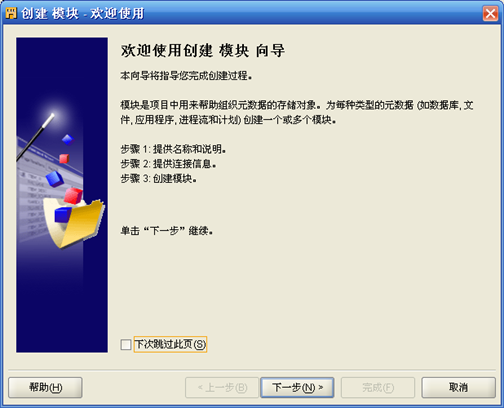
- 输入模块名称如HR,注意选择"数据源"
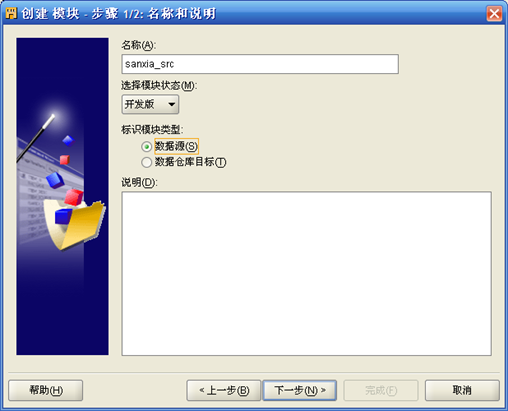
- 点击"位置"右侧"编辑",进入连接信息定义界面
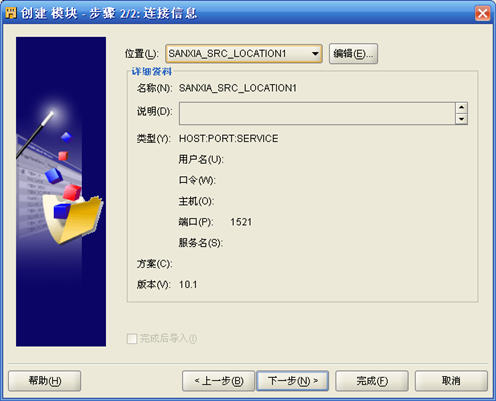
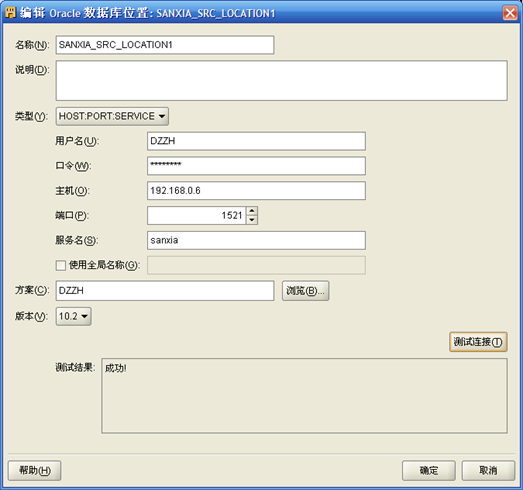
User Name:连接数据源的表的数据库用户名称
Password:连接数据源的表的数据库用户的口令
Host:作为数据源的表所在的数据库服务器机器的IP地址
Port:作为数据源的表所在的数据库服务器的端口
Service Name:作为数据源的表所在的数据库的Service Name
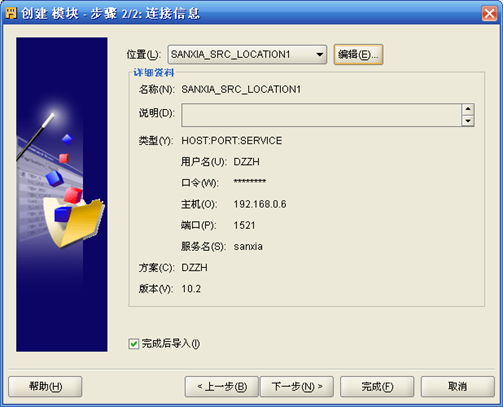
- 导入表结构
一种方式是"新建"模块后,自动进入"导入"向导;另外一种方法是选择刚才建立的数据源模块,单击右键"导入"
按照导入向导导入作为数据源的表以及其它需要用到的对象
- 定义"目标数据模块(Module)"
- 建立目标数据模块,"项目名称-数据库-Oracle"上,右键"新建"
- 按照向导输入模块名称如sanxia_tgt,注意选择"数据仓库目标"
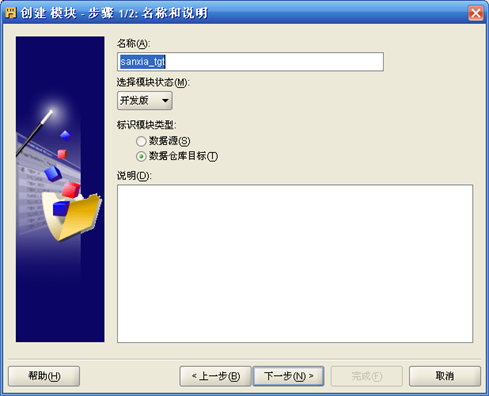
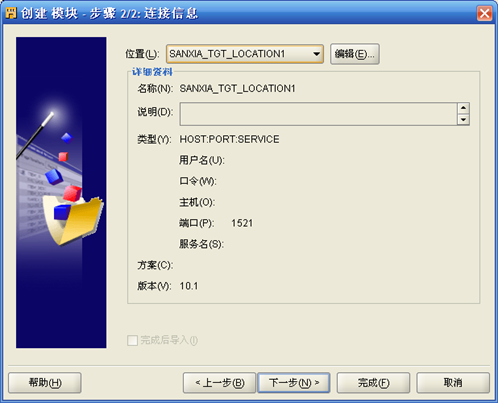
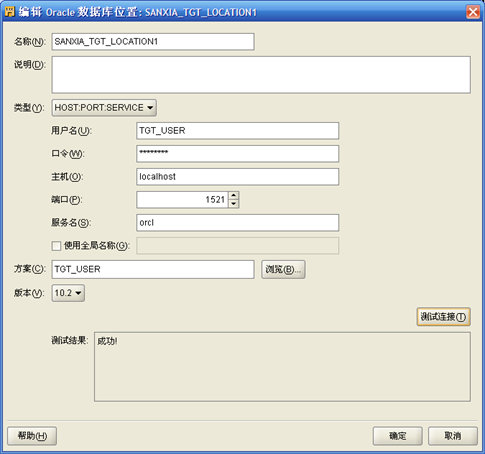
- 点击"位置"右侧"编辑",进入连接信息定义界面,输入目标表所在数据库服务器IP地址、端口号、用户名和口令,目标数据位置名称为SANXIA_TGT_LOCATION1
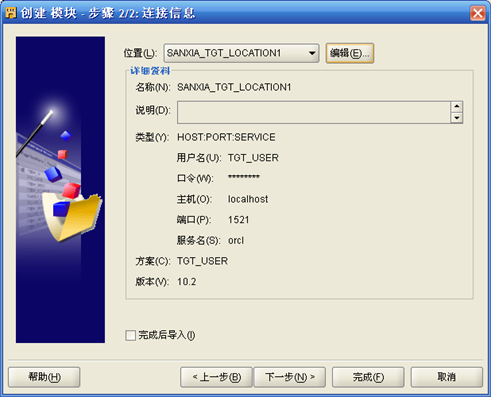
- 不需要勾选"完成后导入",点击"下一步"直到完成。
- 设计"事实表"的"映射(Mapping)"
- "项目-数据库-Oracle-目标数据模块名称-映射",右键"新建" ,输入映射名称如zhaa02a_load_map,"确定"后进入映射编辑框
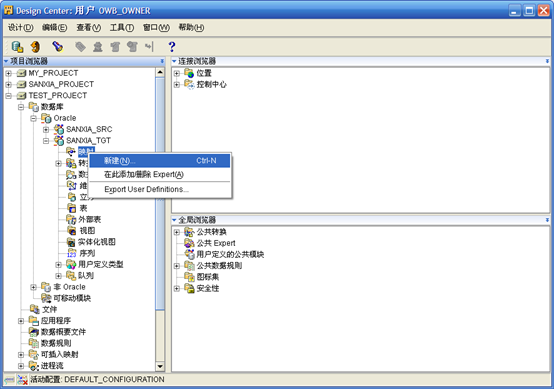
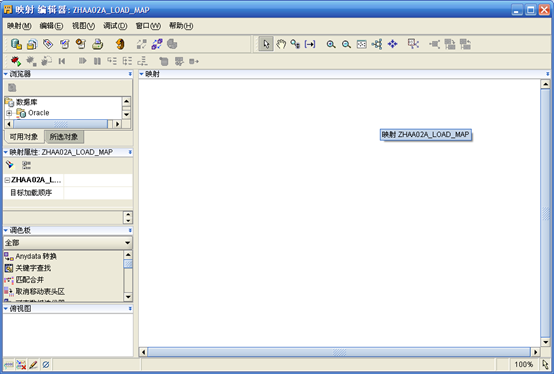
- 左上角的"浏览器"下点中"可用对象",找到数据源模块下的表zhaa02a,托拽到右边的"映射"框中
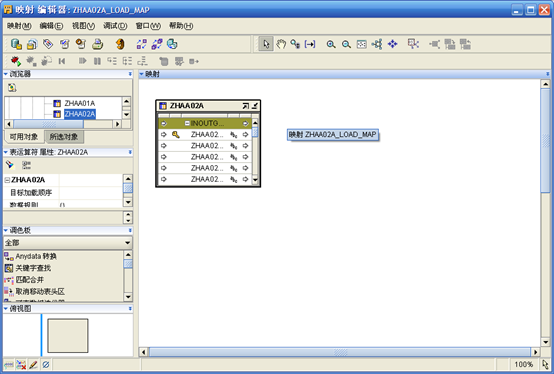
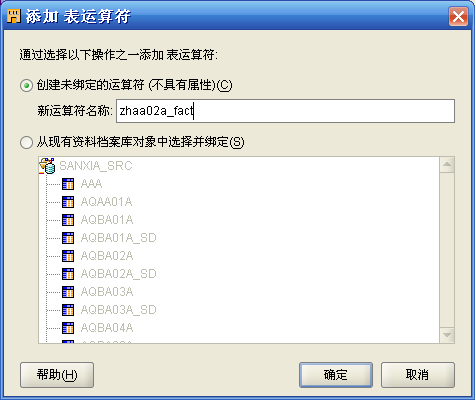
- 从左边的调色板"全部"中找到"表运算符",托拽到右边的"映射"框中,此时会弹出如下对话框,注意选择"创建未绑定的运算符(不具有属性)",含义是在OWB的资料库中还没有要用的表的结构定义,输入表的名称如zhaa02a_fact
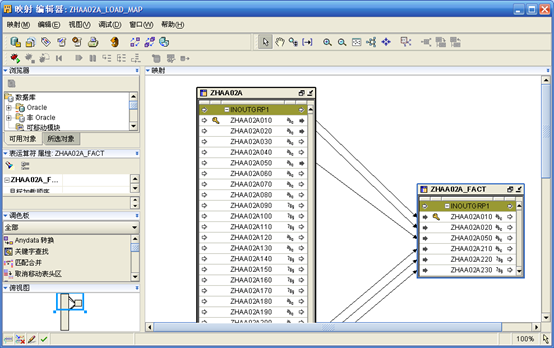
- "OK"后的Mapping编辑器的样子如下:
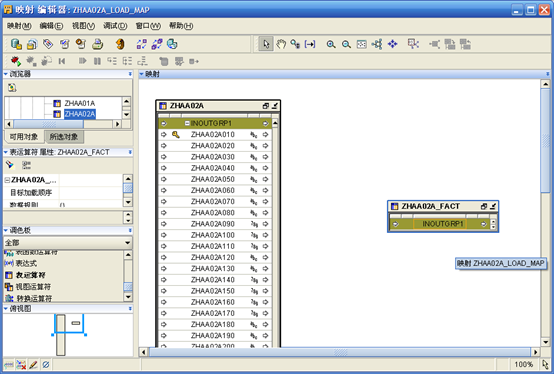
- 左边的是源表,右边是要映射的事实表。下面将需要的字段映射到zhaa02a_fact。
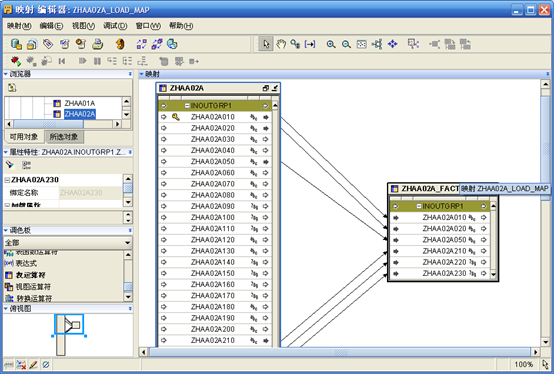
- 接下来需要"创建并绑定"zhaa02a_fact表到"目标数据模块",这一步的作用是在OWB资料库中"目标数据模块"的"表"中添加zhaa02a_fact,以便以后可以部署这个表,也就是在目标数据库的目标用户下生成此表。选中zhaa02a_fact,"右键"选择"创建并绑定"。
- 修改zhaa02a_fact的加载类型为"UPDATE/INSERT"。
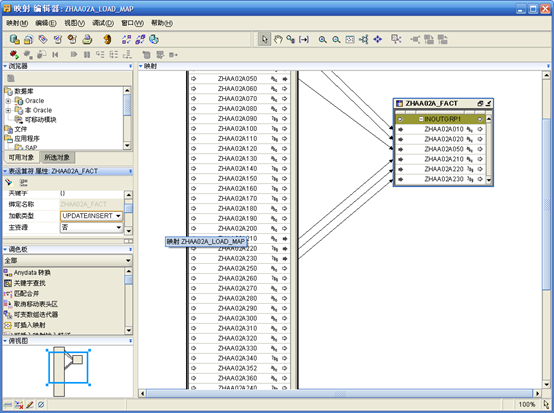
- "保存",关闭"Mapping编辑器"
- 在Designer Center的"项目浏览器"下,找到"项目-数据库-Oracle-目标数据模块名称-表",可以看到zhaa02a_fact,这就表示刚才的"创建并绑定"成功了。
- 打开表zhaa02a_fact,增加主键
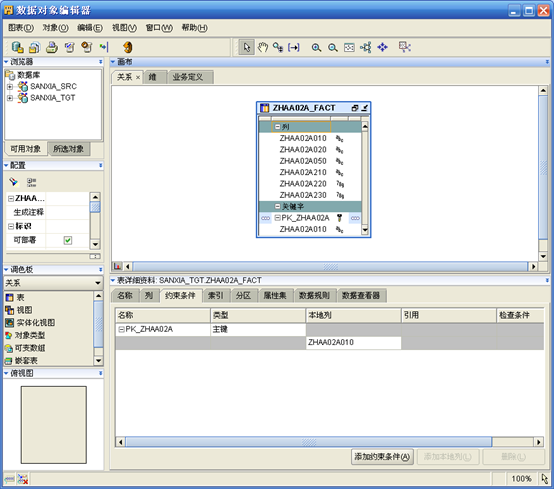
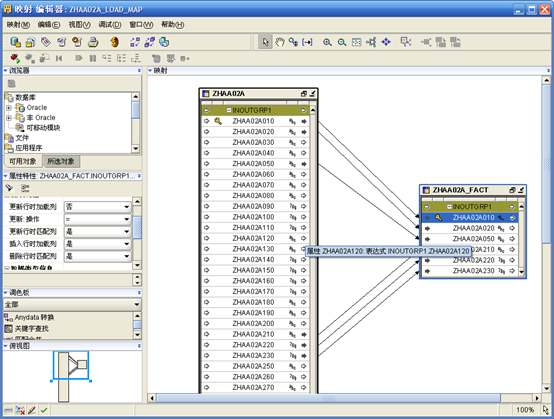
- 重新打开zhaa02a_load_map映射编辑器,点击工具栏上的"全部同步"按钮。
- 选择表zhaa02a_fact的zhaa02a010字段,在左边编辑"加载属性"
- 设计"维(Dimension)"
- 在目标模块下找到"维",右键"新建"-"使用向导"
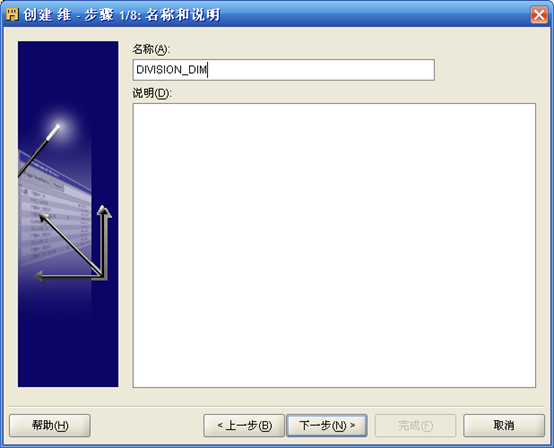
- 现在需要创建一个地区维,输入名称如DIVISION_DIM
- 选择"ROLAP"
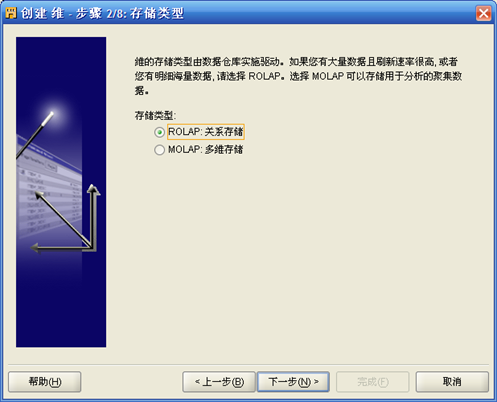
- 下一步出现维属性的定义
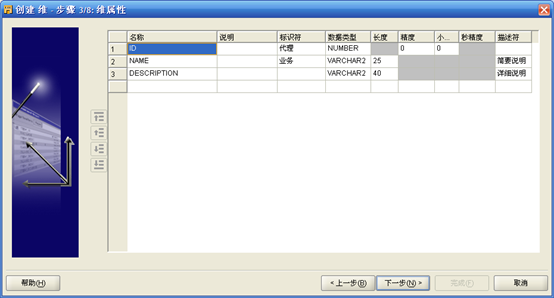
【注意:一个维必须有一个"代理标识符"和一个或多个"业务标识符","代理标识符"默认是number型的,不能修改,也不需要修改。】
- 经过定义的维属性如下:
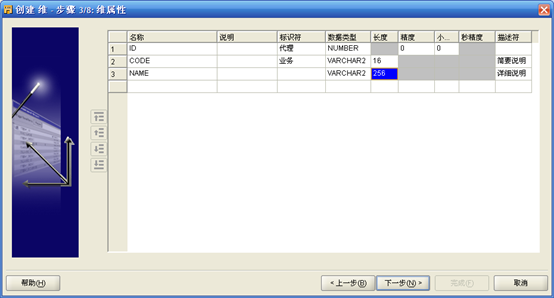
- 接下来定义级别:
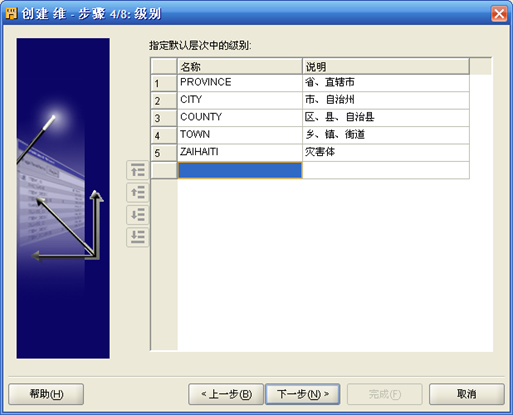
- 如上图定义了5个级别,下一步定义级别的属性:
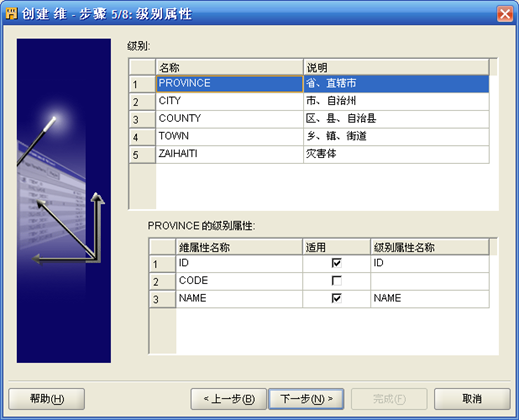
- 将上面的每个级别都使用下面的三个属性,依次选择上面的5个级别将下面的勾都勾上。
- 下一步,选择"类型1"
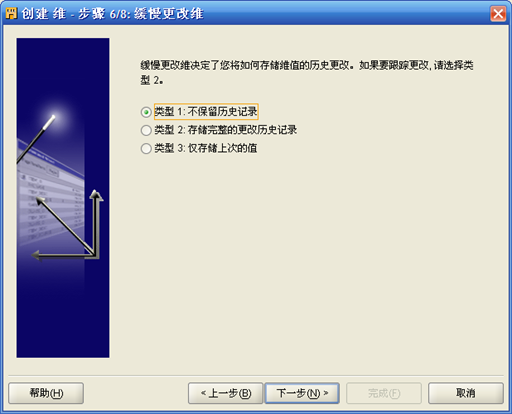
- 下一步,直到"维"成功创建。
- 在"设计中心"找到刚刚创建的维,双击打开
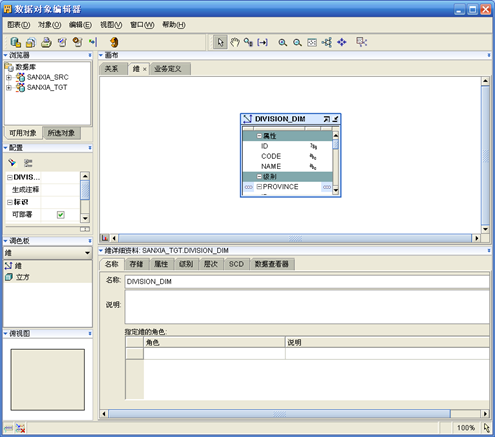
- 在"维"对象上右键,选择"自动绑定"
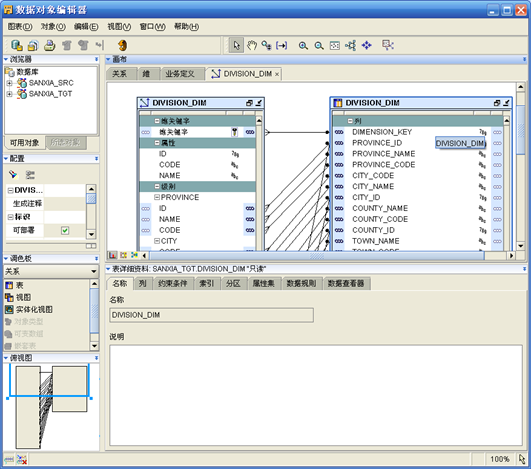
- 保存并关闭"数据对象编辑器"
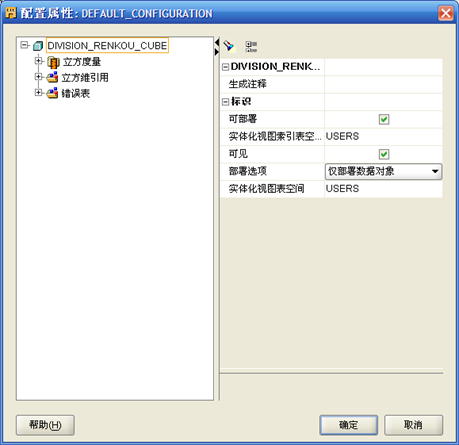
- 在"设计中心"找到刚刚创建的维,右键"配置"
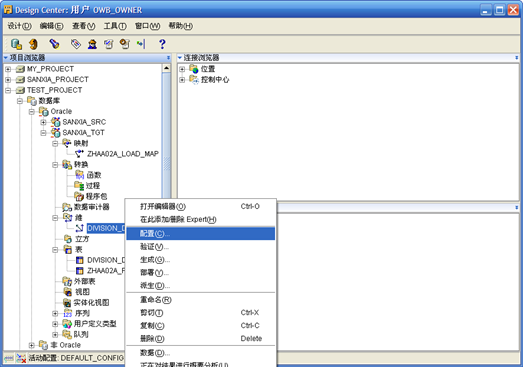
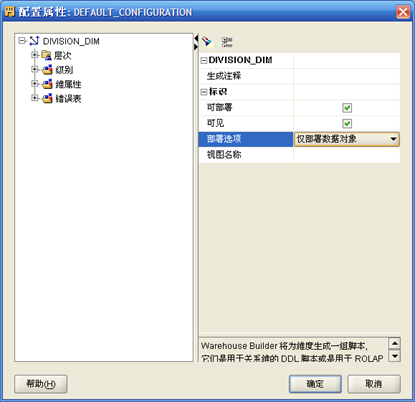
- 将"仅部署数据对象"改为"全部部署"
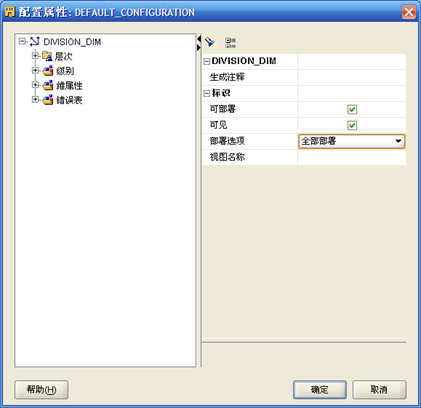
- "确定"完成"维"的设计
- 设计"维(Dimension)"的"映射(Mapping)"
- 在目标模块下找到"映射",右键"新建"
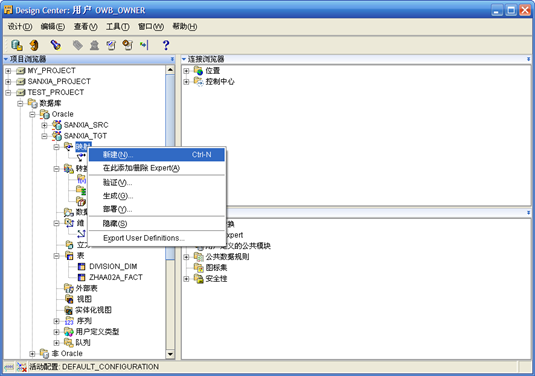
- 输入"division_dim_map"
- 确定后自动打开映射编辑器
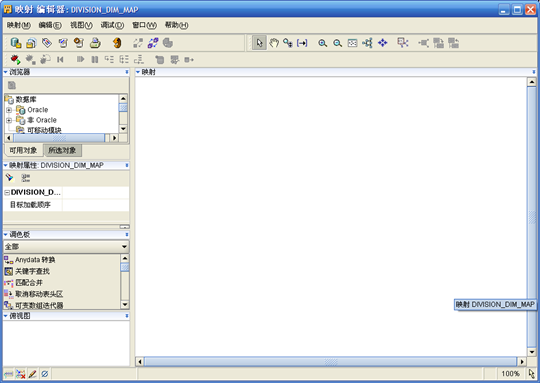
- 在源模块下找到用于抽取数据的表或视图,拖拽到编辑区。如果数据需要转换,则将"转换"节点下的对象拖拽到编辑区。将维对象"DIVISION_DIM"拖拽到编辑区。
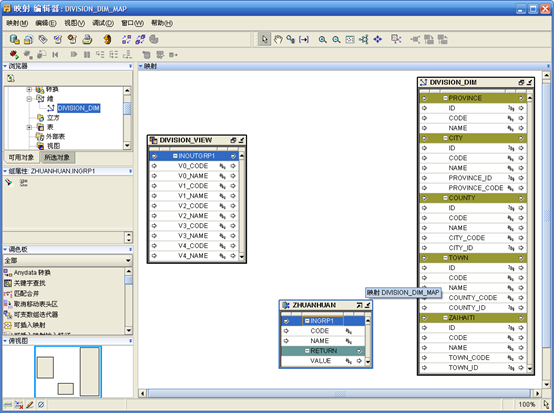
- 设计映射,最终设计好的如下图所示:
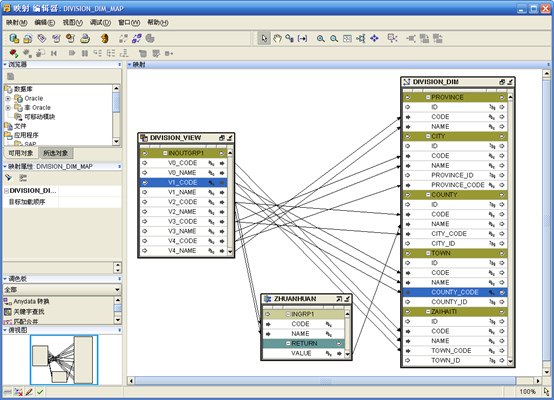
- 注意,维对象的代理标识符不需要映射,它是由创建维对象时生成的一个序列自动维护的,只需要映射业务标识符
- 映射完成后,保存退出。
- 设计"立方(Cube)"
- 在目标模块下找到"立方",右键"新建"-"使用向导"
- 输入立方名称"DIVISION_RENKOU_CUBE"
- 选择"ROLAP",下一步
- 指定立方的维,选择维"DIVISION_DIM"
- 指定度量
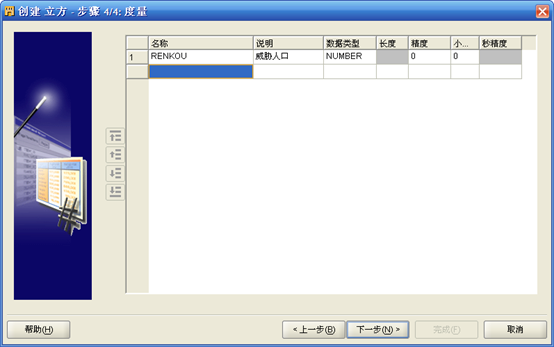
- 下一步直到完成。
- 在"设计中心"找到刚刚创建的立方,双击打开
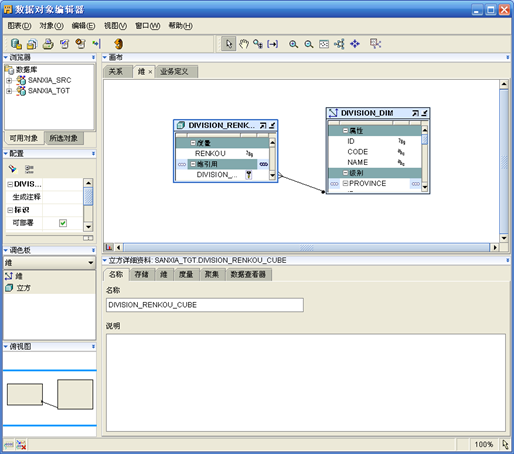
- 在"立方"对象上右键,选择"自动绑定"
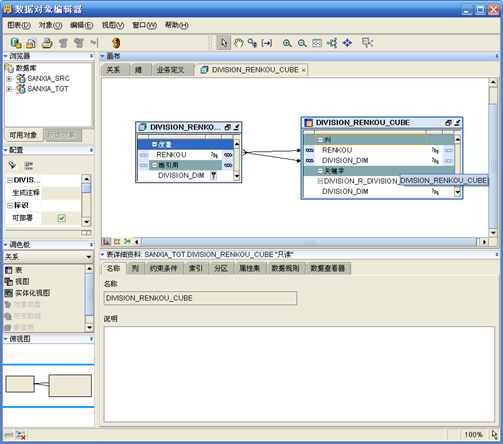
- 保存并关闭"数据对象编辑器"
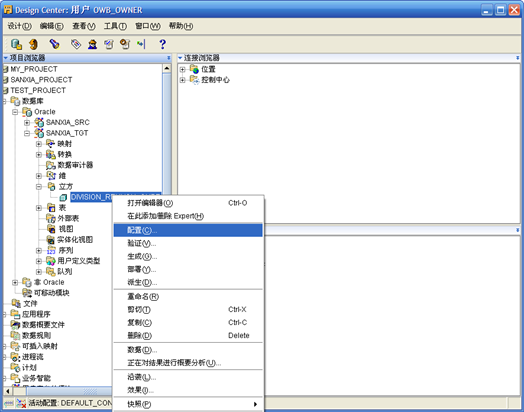
- 在"设计中心"找到刚刚创建的立方,右键"配置"
- 将"仅部署数据对象"改为"全部部署"
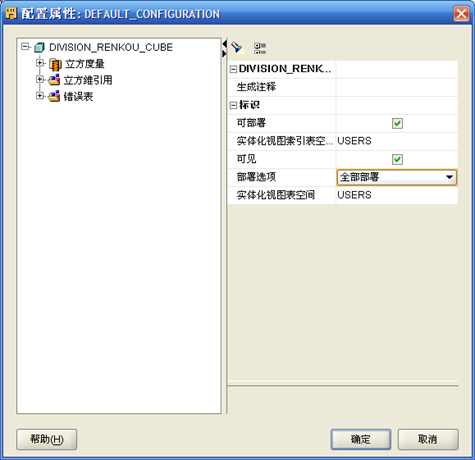
- "确定"完成"立方"的设计
- 设计"立方(Cube)"的"映射(Mapping)"
- 在目标模块下找到"映射",右键"新建"
- 输入"DIVISION_RENKOU_CUBE_MAP"
- 确定后自动打开映射编辑器
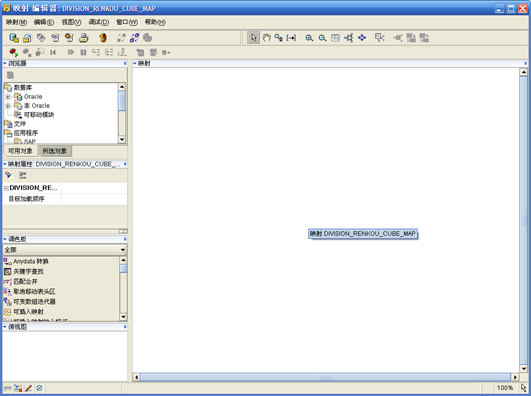
- 在目标模块下找到用于抽取数据的事实表,拖拽到编辑区。如果数据需要转换,则将"转换"节点下的对象拖拽到编辑区。将立方对象"DIVISION_RENKOU_CUBE"拖拽到编辑区。在"调色板"的"全部"下选择"聚集器",拖拽到编辑区。
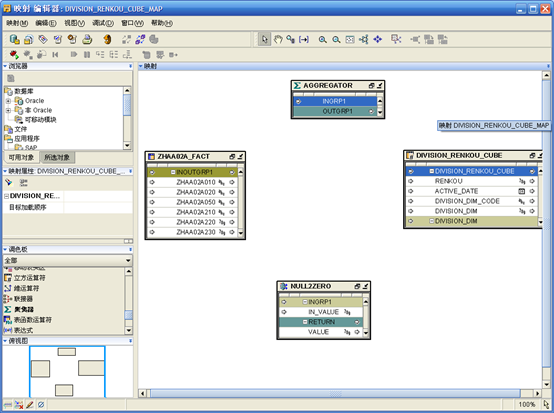
- 设计映射,初始进行如下连接:
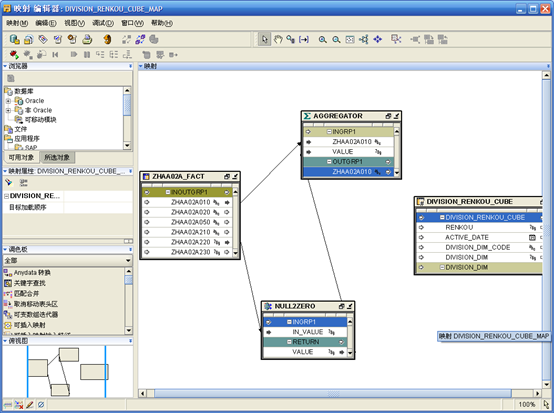
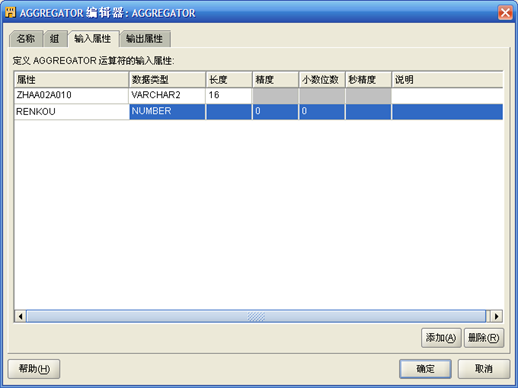
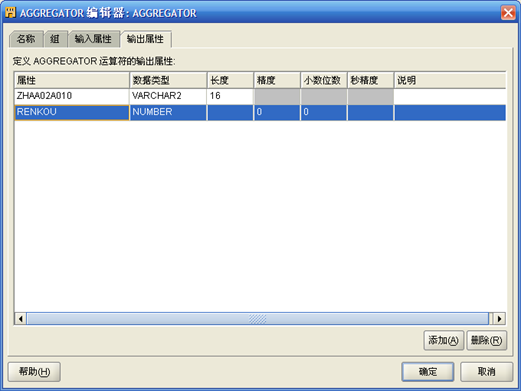
- 右键点击"AGGREGATOR",选择"打开详细资料"。将"输入属性"中的"VALUE"改为"RENKOU",增加输出属性"RENKOU"。
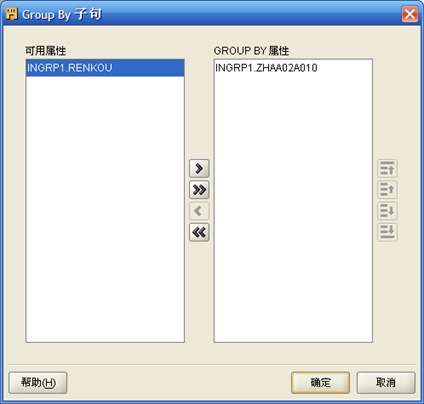
- 确定后,选择"AGGREGATOR",在左边的"聚集器"属性中点击"Group By子句"后的按钮,将左边列表的"INGPR1.ZHAA02A010"移动到右边。
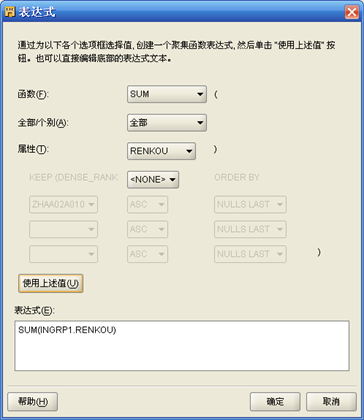
- 再次在编辑区选择"AGGREGATOR"中的"OUTGPR1"下的"RENKOU",在左边的"属性特性"中点击"表达式"后的按钮,弹出"表达式"对话框。函数选择"SUM",属性选择"RENKOU",然后点击"使用上述值"按钮。最后确定。
- 返回到编辑区,连接"AGGREGATOR"与立方,最后的结果如下图
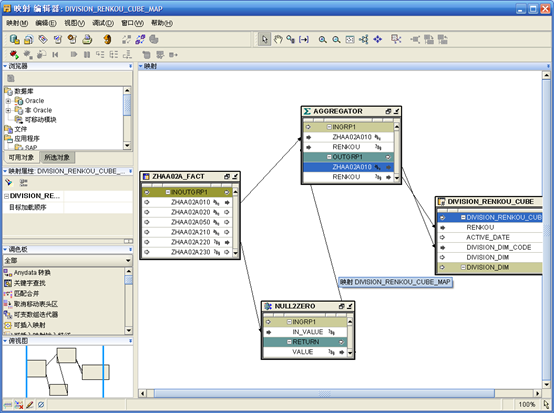
- 映射完成后,保存退出。
- 设计"映射(Mapping)"时用到的"转换"
在ORACLE数据库的目标模块下,找到"转换"-"函数",新建2个函数:
|
函数名 |
作用 |
|
ZHUANHUAN |
输入CODE和NAME,如果NAME为空,则将NAME设置为CODE的值 |
|
NULL2ZERO |
将空值转换为0 |
|
函数名 |
返回类型 |
参数名称 |
参数类型 |
I/O |
必需? |
|
ZHUANHUAN |
VARCHAR2 |
CODE |
VARCHAR2 |
输入 |
是 |
|
NAME |
VARCHAR2 |
输入 |
是 |
||
|
NULL2ZERO |
NUMBER |
IN_VALUE |
NUMBER |
输入 |
是 |
函数"ZHUANHUAN"的代码如下:
RET_NAME NVARCHAR2(256);
BEGIN
NULL; -- 允许编译
IF lengthB(NAME) = 0 OR NAME IS NULL THEN
RET_NAME := CODE;
ELSE
RET_NAME := NAME;
END IF;
RETURN RET_NAME;
EXCEPTION
WHEN OTHERS THEN
NULL; -- 在此处输入任意异常代码
RETURN NULL;
END;
函数"NULL2ZERO"的代码如下:
RET_VALUE NUMBER;
BEGIN
NULL; -- 允许编译
IF lengthB(IN_VALUE) = 0 OR IN_VALUE IS NULL THEN
RET_VALUE := 0;
ELSE
RET_VALUE := IN_VALUE;
END IF;
RETURN RET_VALUE;
EXCEPTION
WHEN OTHERS THEN
NULL; -- 在此处输入任意异常代码
RETURN NULL;
END;
- 设计"进程流(Process Flow)"确定映射运行的先后顺序
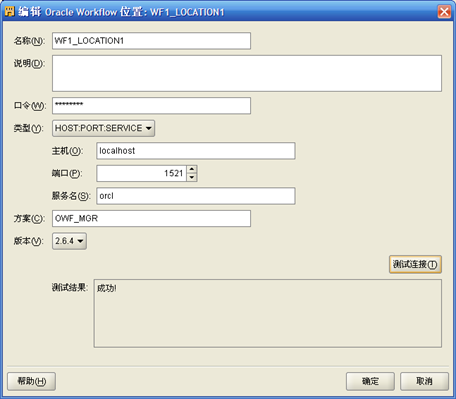
- "项目-进程流-进程流模块"右键"新建",输入"进程流模块"名称如WF1,"编辑""进程流模块"的"位置",输入Workflow管理员所在数据库服务器IP地址、端口号、用户名和口令;如果数据库是10GR2,Workflow的版本是2.6.4。进程流位置名称为WF1_LOCATION1
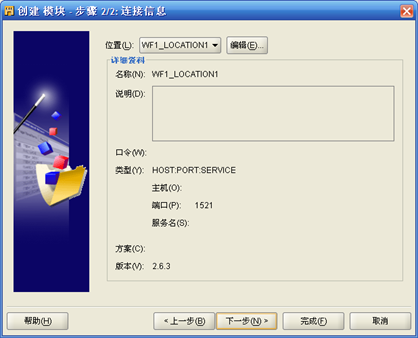
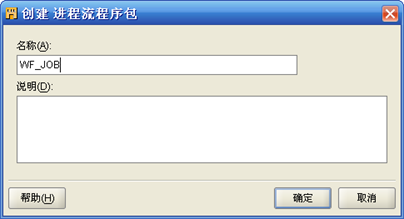
- 完成后,"创建 进程流程序包"弹出,输入"进程流包"名称如WF_JOB
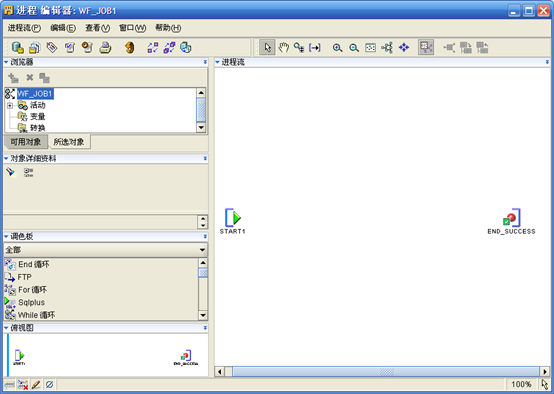
- 完成后,"创建 进程流"弹出,输入"进程流"名称如WF_JOB1,进入"进程编辑器"
- 进程流的作用是可以将映射串联起来,确定映射的运行顺序,映射之间的关系可以是串行,也可以是并行的,左上角的"浏览器",选中"可用对象",找到目标模块下的三个映射ZHAA02A_LOAD_MAP、DIVISION_DIM_MAP、DIVISION_RENKOU_CUBE_MAP,依次托拽到右边的"编辑区"。然后在左边"调色板"中选择一个"分支"对象、一个"与"对象、一个"结束,但出现警告"对象、一个"结束,但出现错误"对象,拖拽到"编辑区",最后是下面这个样子
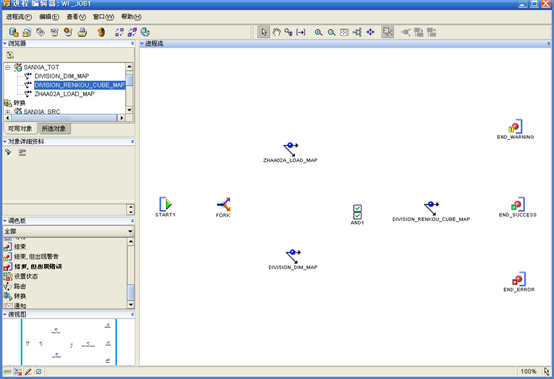
- 然后在"START1"图标和映射图标之间画连线,在映射图标和"END_SUCCESS"图标之间画连线,最后形成的Process编辑器的样子如下
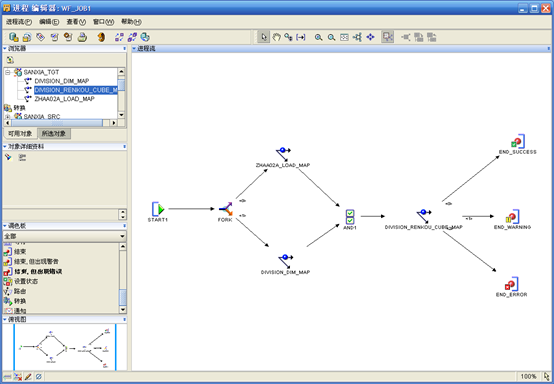
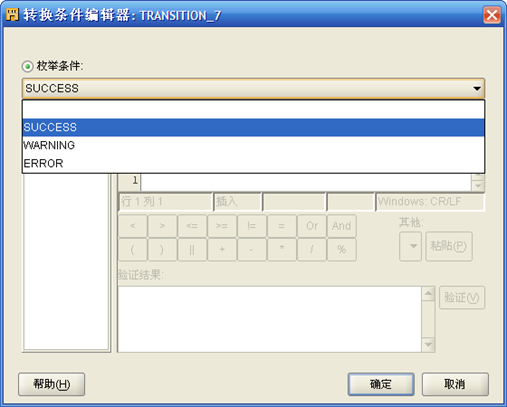
- 最后设置"DIVISION_RENKOU_CUBE_MAP"和"END_SUCCESS"、"END_WARNING"、"END_ERROR"的转换条件,依次选中三个转换间的直线,然后在左边的"对象详细资料"中设置"条件",三个条件依次是"SUCCESS"、"WARNING"、"ERROR"。
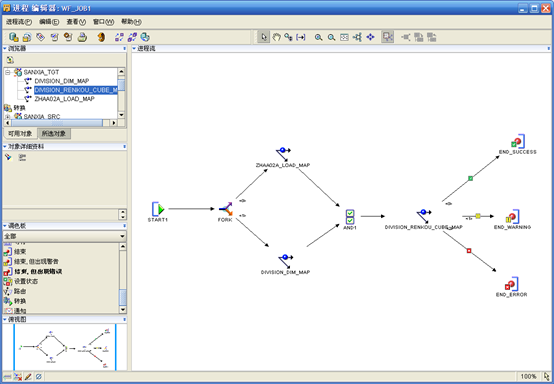
- 最后的结果如下
- 执行工具栏上的"验证"操作,可以看到验证成功的消息
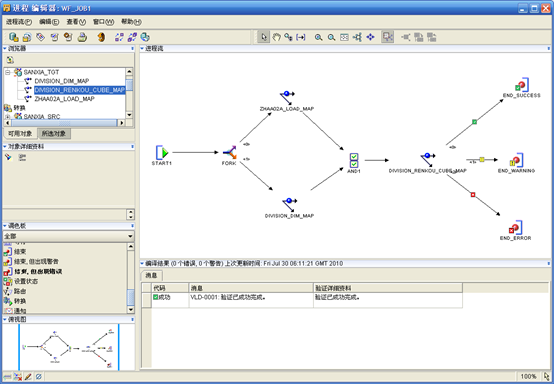
- 保存并退出。
- 设计"计划(Schedule)"
- 不同的"工作流模块"和"目标数据模块"需要设计不同的"计划",现在为"工作流模块"建立"计划"
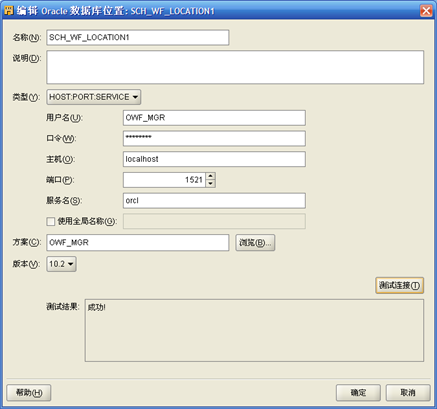
- "项目-计划"右键"新建",输入"计划模块"名称如SCH_WF,"编辑""计划模块名称"的"位置",输入Workflow管理员所在数据库服务器IP地址、端口号、用户名和口令;计划模块位置的名称为SCH_WF_LOCATION1
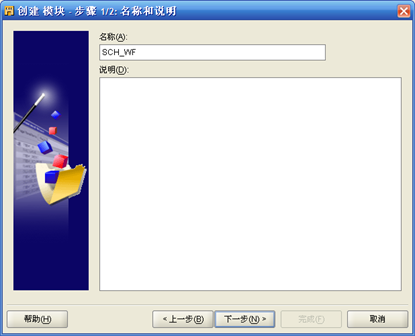
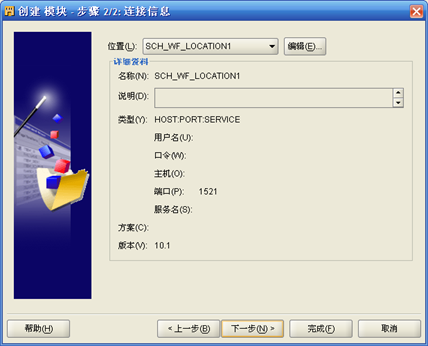
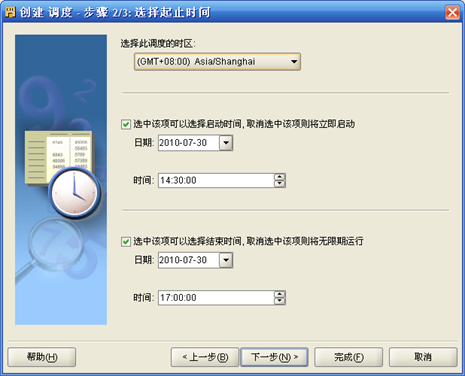
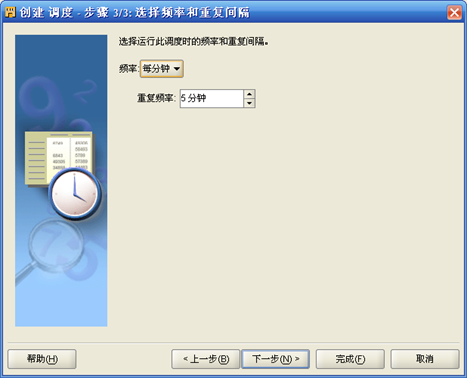
- "项目-计划-计划模块名称"右键"新建",按照向导,首先输入"计划"名称如SCH_WF_DAY;其次选择"时区"、"起始时间"、"结束时间";第三步"选择频率和重复间隔"
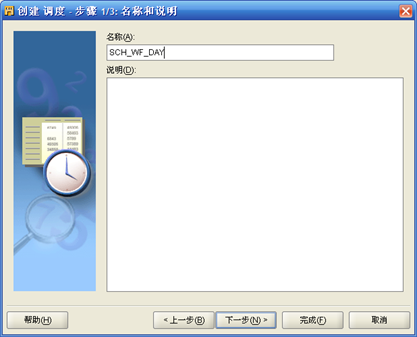
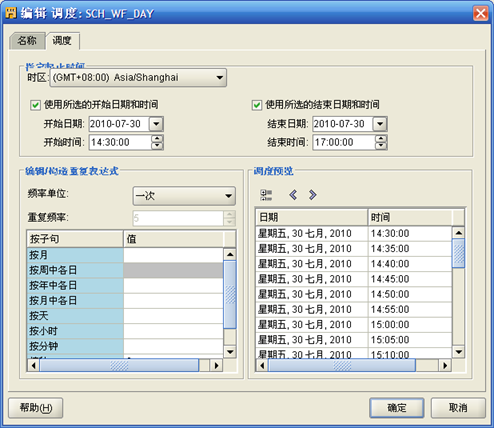
- 为了更改"计划"的执行时间,"项目-计划-计划模块名称-计划名称"右键"打开编辑器",出现"调度 编辑"。这里可以修改和预览调度设置
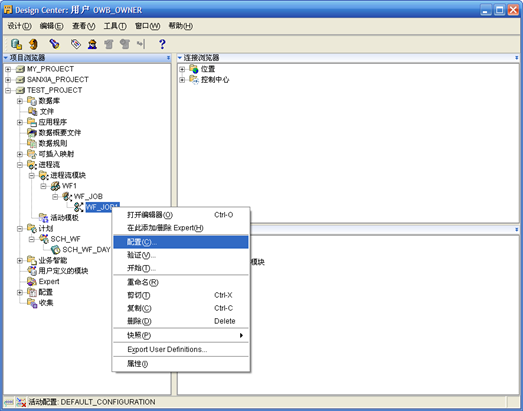
- 配置"工作流"的"计划"
- "项目-工作流-工作流模块名称-工作流包名称-工作流名称"右键"配置",如下图
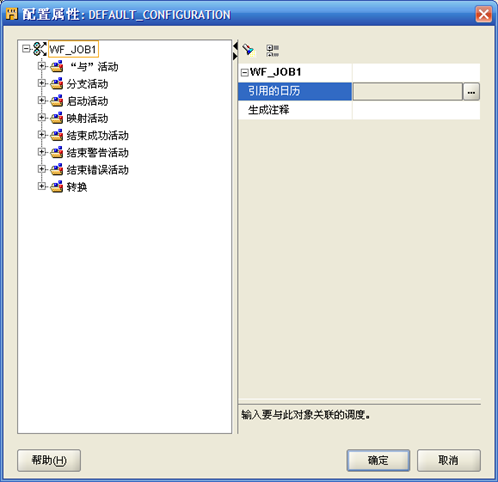
- 点击"引用的日历"右边的空格,从下拉框中选择刚才创建的"计划"SCH_WF_DAY

- 确定后退出。
- 至此,完成了在Designer Center中设计的工作。
- 在"控制中心管理器"(Control Center Manager)中部署和执行ETL
- 进入Control Center Manager
- 在Designer Center中,选择菜单"工具"-"控制中心管理器(Control Center Manager)",输入OWB资料库所有者口令,即可进入Control Center Manager界面
- 注册"位置(Location)"
- 在控制中心管理器界面的左边,可以看到创建的项目下的所有位置。
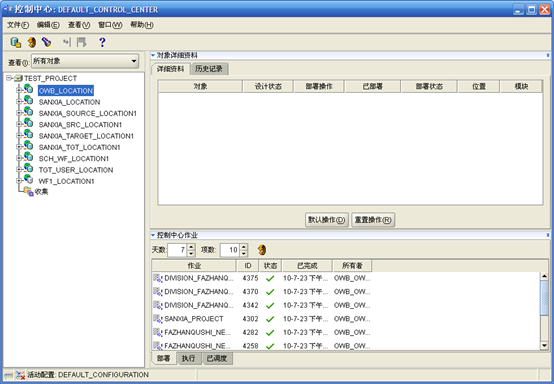
- 检查左边树上没有注册的位置,依次进行注册,方法是点击右键,选择"注册",然后点确定就可以了
- 部署对象
- 选中"项目名称",右边的"对象详细资料"会列出所有对象如表、映射、进程流、工作(配置了计划的进程流或者映射),如下图
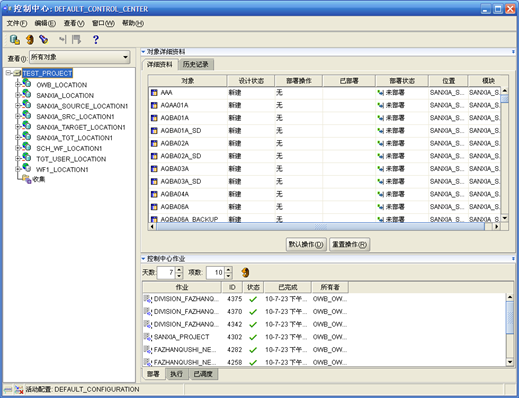
- 这些对象并非全部都要部署,这里只需要部署"SANXIA_TGT_LOCALTION1"、"SCH_WF_LOCALTION1"、"WF1_LOCATION1"、"TGT_USER_LOCALTION1"四个位置下的对象。由于"TGT_USER_LOCALTION1"下面没有对象可以部署,实际上只有三个位置。这里要注意的是,数据库源模块下的对象是不需要部署的。
- 选择"SANXIA_TGT_LOCALTION1"右边会列出"SANXIA_TGT_LOCALTION1"位置下的所有对象。然后点击"默认操作",此时"部署操作"列全部为"创建"状态。
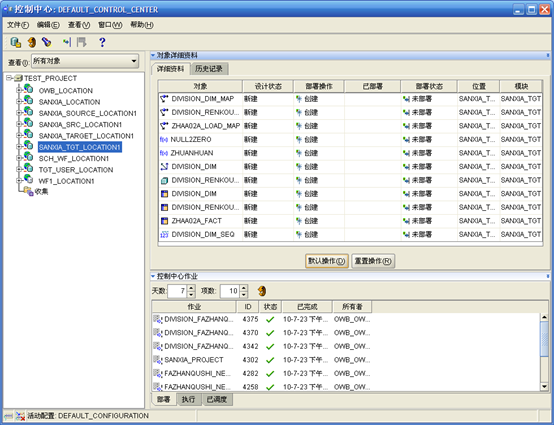
- 此时再点击工具栏上的"部署"按钮,开始部署操作。此时会对要部署的所有对象执行"验证"操作,如果出现错误或者警告导致无法部署,则需要查找原因。修改后再重新部署。
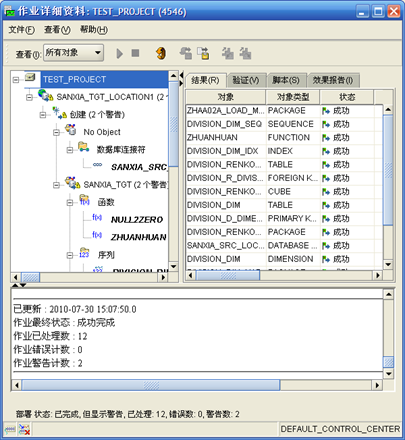
- 同样的方法,部署"SCH_WF_LOCALTION1"和"WF1_LOCATION1"位置下的对象
- 作业执行与调度
- 如果"部署"全部成功,可以选择右下方"已调度",选择WF_JOB1_JOB,右键"开始"
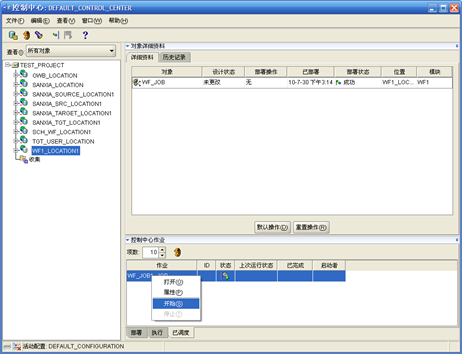
- 在"计划"的指定运行时间此"工作"就会开始运行
- 在右下角"执行"中可以看到每次作业调度的运行结果
- 如果不想执行调度了,点击"停止"就会停止运行
- 另外,还可以对单个映射执行ETL操作,方法是在映射对象上右键点击"开始",然后到"控制中心管理器"中查看执行结果。
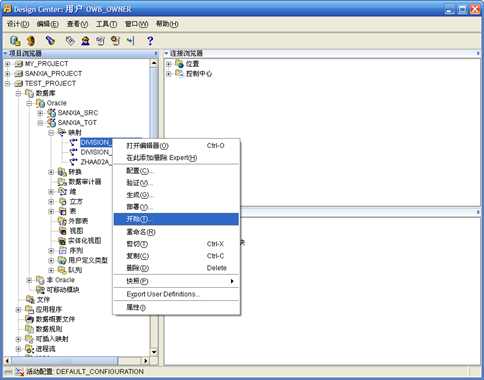
- 检查结果是否正确
- 查看"目标用户"(TGT_USER)下的目标表"ZHAA02A_FACT"、"DIVISION_DIM"、"DIVISION_RENKOU_CUBE"中是否数据正确
- 在维对象"DIVISION_DIM"点击右键"数据",可以查看维数据
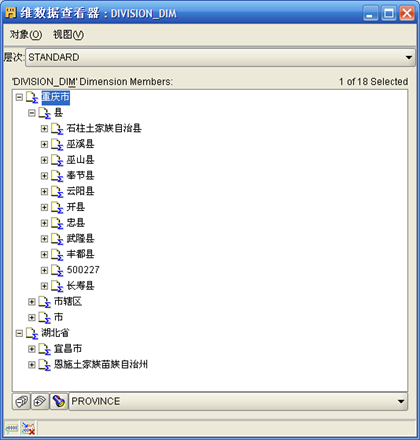
- 在立方对象"DIVISION_RENKOU_CUBE" 点击右键"数据",可以查看立方数据。【有时候在修改了其它对象并部署后,再查看立方对象数据时会出错,解决方法就是在"控制中心管理器"中将立方对象删除后再重新创建。】
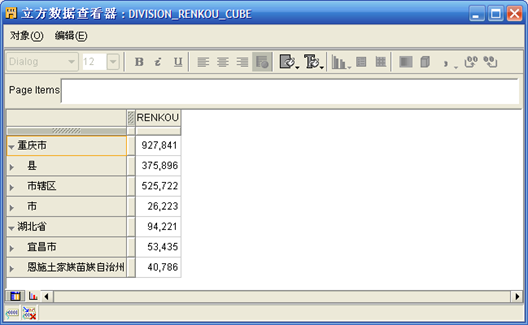
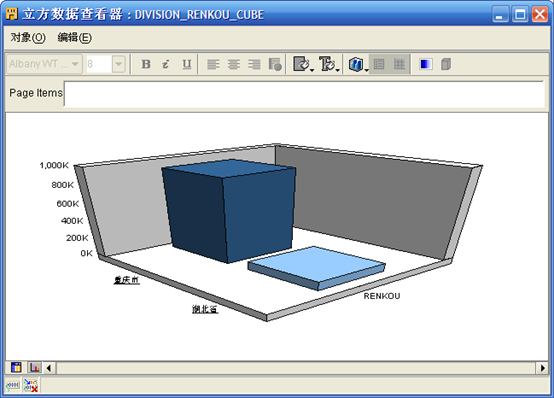
- 确认数据无误,一旦出现问题,就需要检查,重新修改对象,并在"控制中心管理器"中重新部署。
- 使用Analytic Workspace Manager(AWM)填充OLAP 分析工作区【可选】
- AWM概述
- Analytic Workspace Manager 10g 是一个工具,用于创建、开发和管理 Oracle OLAP 数据仓库中的多维分析工作区。通过这个简单易用的 GUI 工具,您可以使用逻辑维和多维数据集对象创建一个分析工作区。随后,您使用现有的星型、雪花和规范化关系数据源映射这些对象,然后加载数据。此外,在本教程中,您需要使用模板并做出数据存储决策。
- AWM与OWB的区别
- 对于建立分析工作区,AWM应该包含一个"EL"工具,它没有转换工具(在AWM 11g中可以作简单的转换)。AWM的目标用户是商业用户和已经在使用其它不支持OLAP数据建模的ETL工具的开发人员。
- 很显然,AWM还可以帮助你设计你的逻辑数据模型,但是AWM和OWB有一个很重要的不同之处。AWM最恰当的描述是"运行时设计时间",这意味着当你使用AWM来创建维度、立方体等的时候,这个对象会立即在分析工作区中被创建,例如,它没有部署阶段。商业用户透视图使得它成为了一个理想的产品,因为它简化了整个过程。
- AWM使用
- 参考以下文章链接:使用 Analytic Workspace Manager 填充您的 OLAP 分析工作区http://www.oracle.com/technology/global/cn/obe/10gr2_db_single/bidw/awm/awm_otn.htm
四、使用Oracle Discoverer进行BI展现
- 安装Oracle Business Intelligence 10g(10.1.2)
- 配置Oracle Business Intelligence 10g
- 启动Start Application Server Control
开始-"Oracle - BIHome1 Enterprise Manager"-"Start Application Server Control"
- 启动实例
开始-"Oracle Business Intelligence - BIHome1"-"Start 实例名.机器名"
- 打开Application Server Control Console
- 开始-"Oracle - BIHome1 Enterprise Manager"-"Application Server Control Console"
- 输入用户名和密码
- 查看"Discoverer"是否启动,没有则启动"Discoverer"服务
- 点击"系统组件"中的"Discoverer"
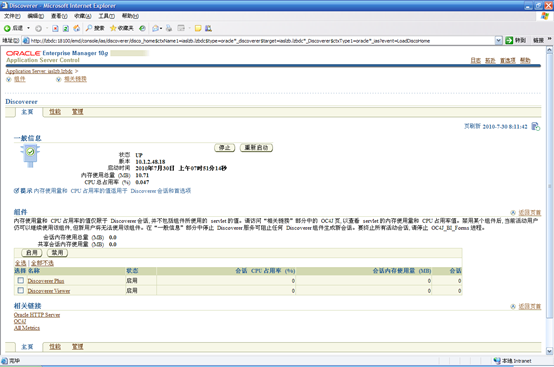
- 点击"管理"
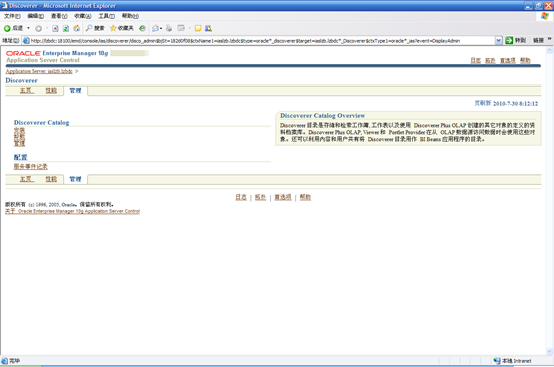
- 点击"安装",输入必要的信息后,直到安装完成。
- 点击"管理",输入密码后登录,然后点击"授权用户和角色",将"tgt_user"用户移动到右边后,点击"Apply"。
- 启动Oracle Discoverer
- 启动Oracle Discoverer
- IE地址栏输入http://lzbdc:7778/,会出来Business Intelligence 10g (10.1.2)的欢迎页面
- 点击Discoverer Plus超级链接,用来创建和编辑工作表并分析数据
- 点击Discoverer Viewer超级链接,用来查看、自定义工作表并分析数据
- 使用Discoverer Plus
- 进入Discoverer Plus,并输入如下信息
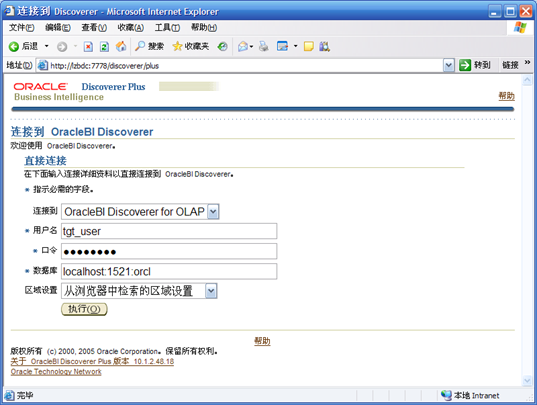
- 出现主界面,并弹出"工作薄向导",点击"创建新的工作薄"
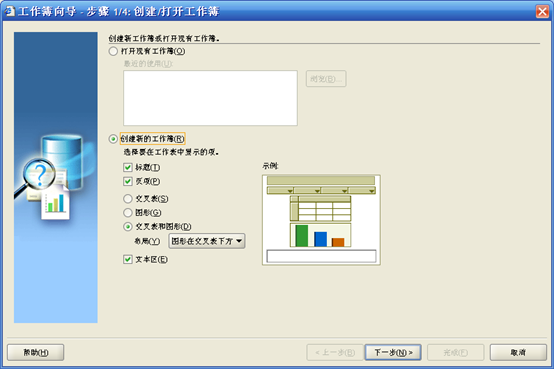
- 选择度量,会自动将维添加到右边
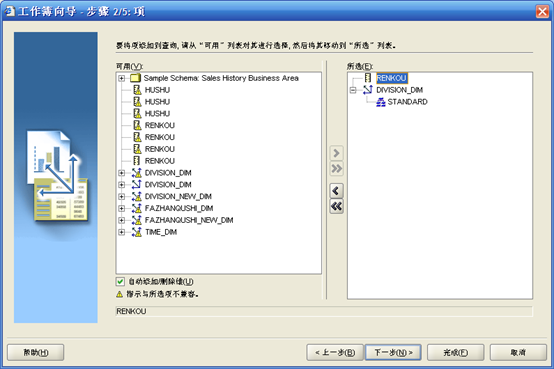
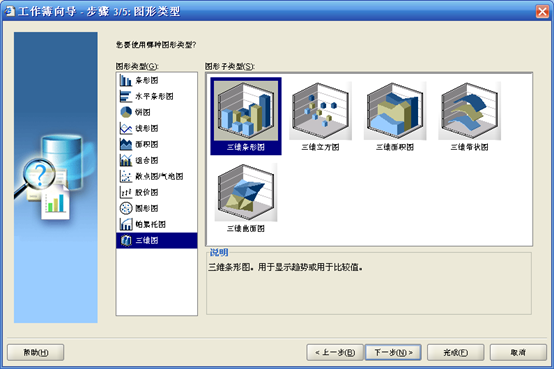
- 选择"三维图"
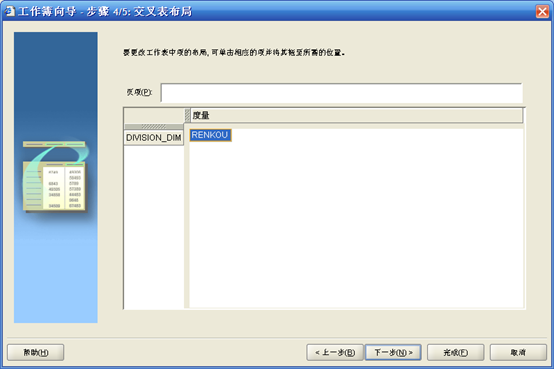
- 修改交叉表布局
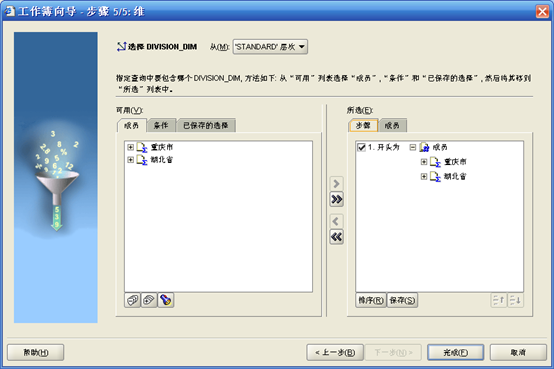
- 选择维级别
- 完成后在编辑区显示刚刚创建的交叉表和图形。
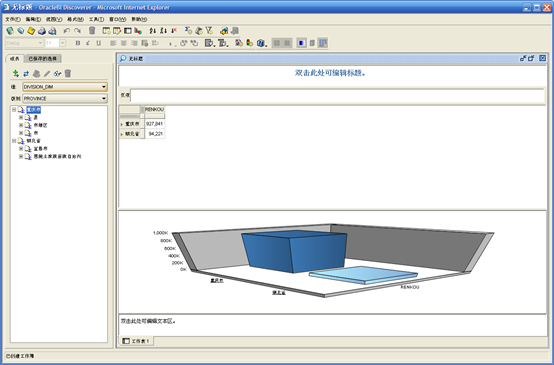
- 还可以进行其它的编辑。编辑完成后保存
- 退出
- 使用Discoverer Viewer
- 进入Discoverer Viewer,输入以下信息
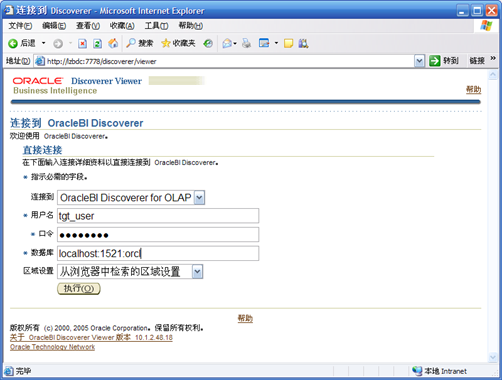
- 找到刚刚保存的工作表并点击打开
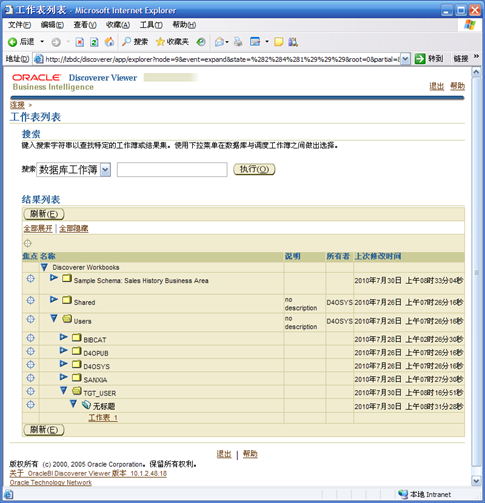
- 可以查看并自定义显示样式
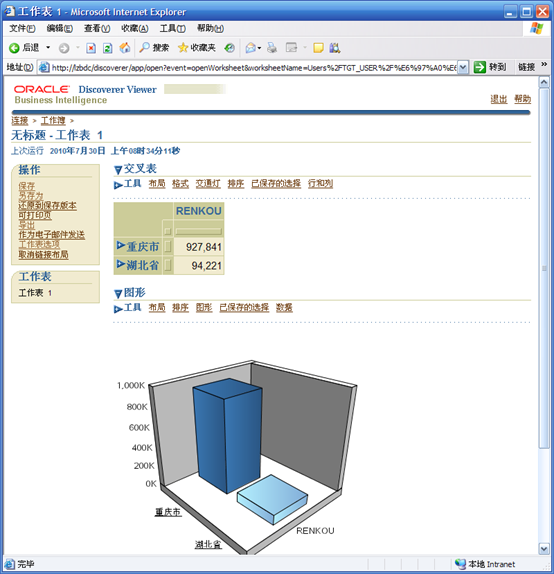
- 修改完成后,点击"保存"
五、使用BI Beans与JDeveloper开发自定义BI展现应用程序
- 安装JDeveloper和BI Beans
- 安装Oracle JDeveloper
- Oracle JDeveloper版本号10.1.2.2 (Build #10.1.2.1929)
- 解压到一个非Oracle的安装目录,如"D:\JDeveloper"
- 设置系统环境变量"JDEV_ORACLE_HOME"为"D:\JDeveloper"
- 安装OracleBI Beans
- OracleBI Beans 10g Release 2 (10.1.2.2) 必须与Oracle JDeveloper 10.1.2.2 (Build #10.1.2.1929)搭配使用,其它版本不行。
- 解压OracleBI Beans到Oracle JDeveloper的安装目录
- 找到目录"D:\JDeveloper\bibeans\bin"下的bi_installcatauto.bat并执行,建议单独新开一个cmd窗口执行,不要直接双击。按提示运行,直到成功。该操作是创建用户"BIBCAT"并分配权限,密码也是"BIBCAT",区分大小写。
- 使用JDeveloper和BI Beans开发自定义BI展现
- 启动JDeveloper
- 找到目录"D:\JDeveloper\jdev\bin",双击执行"jdevw.exe"(不带控制台)或者"jdev.exe"(带控制台)
- 最好将"D:\JDeveloper\jdev\bin\ jdevw.exe"发送到桌面快捷方式
- 新建项目
- 执行File-New
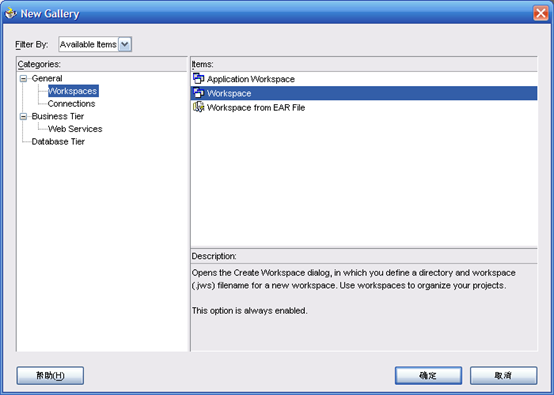
- 选择"Workspace"
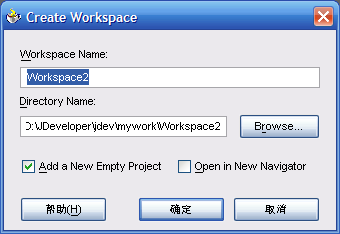
- 修改值后,直接确定
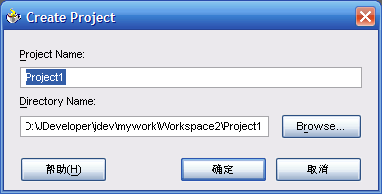
- 修改值后,直接确定
- 在刚刚创建的"Project1"上右键"New",然后做如下选择
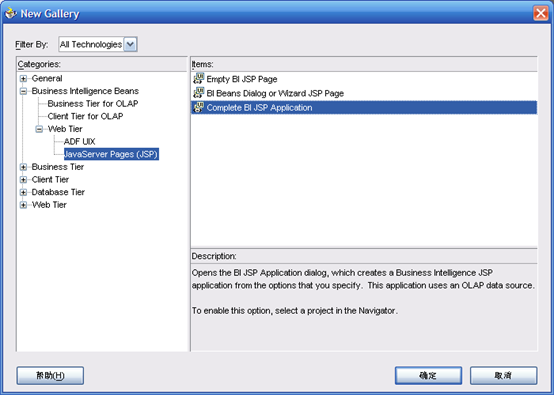
- 确定后弹出
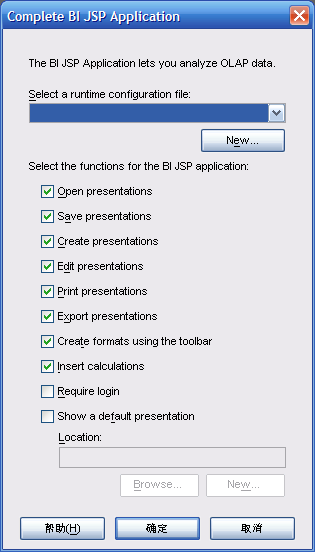
- 点击"New"做如下选择
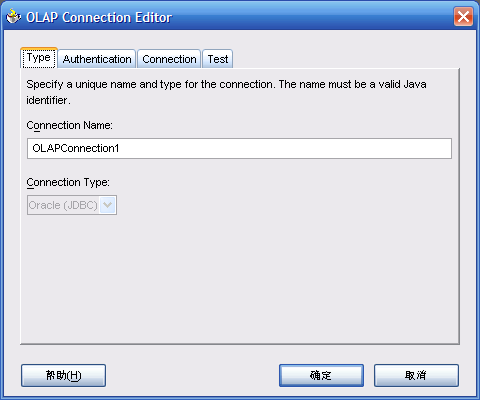
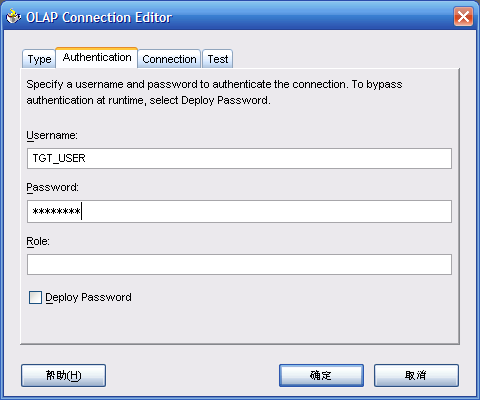
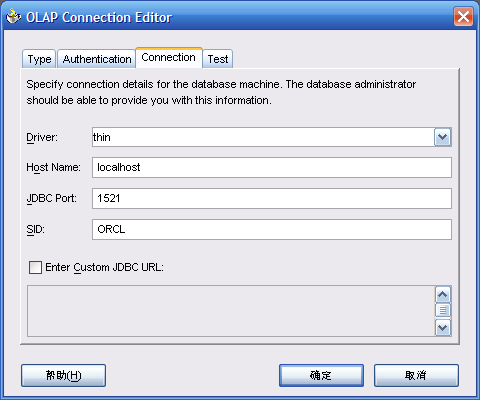
- 确定后,定义连接
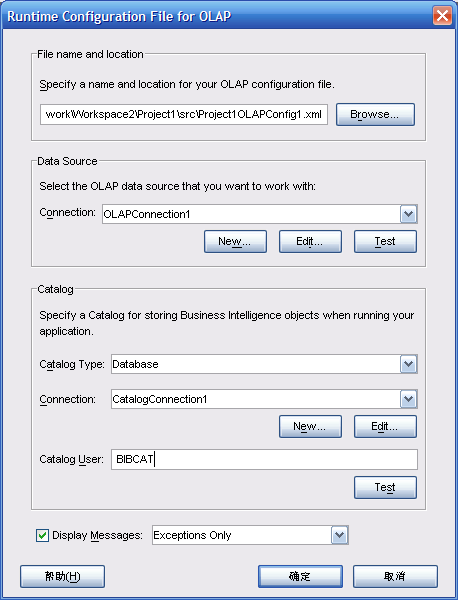
- 给"Data Source"的"Connection"为"OLAPConnection1"
- 给Catalog,选择"Catalog Type"为"Database",设置"Connection"为"CatalogConnection1","Catalog User"为"BIBCAT"。注意"BIBCAT"全部是大写
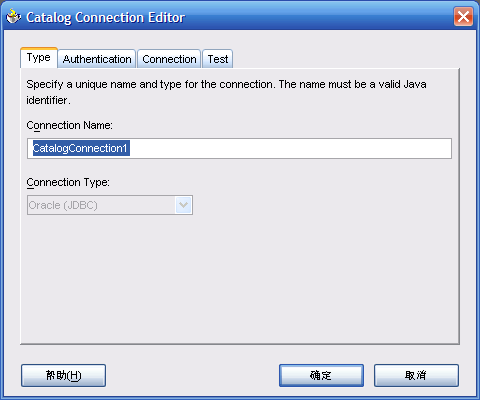
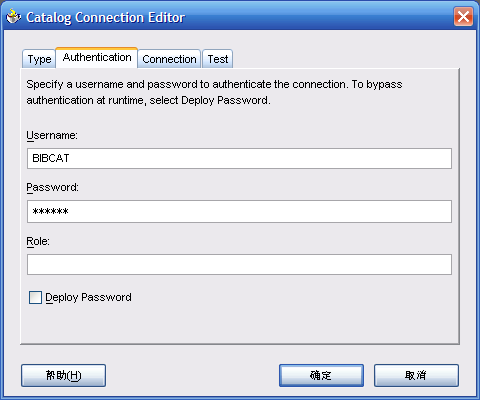
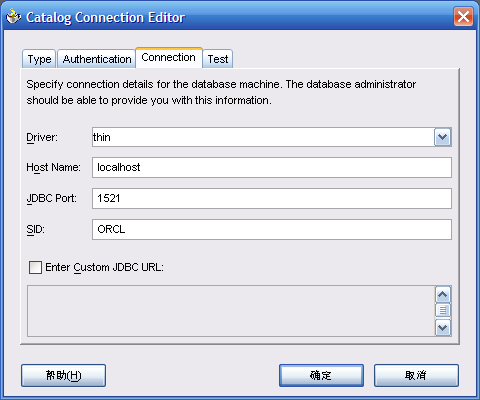
- 确定后返回如下界面
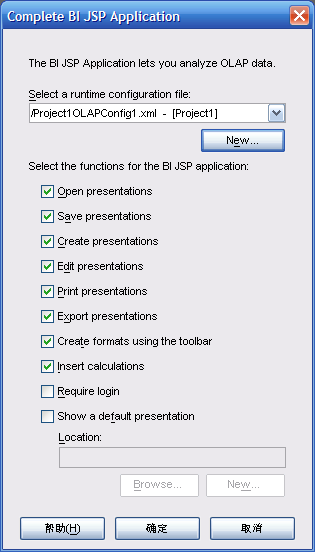
- 在此界面上定义JSP页面的内容
- 最后生成了Project1的内容
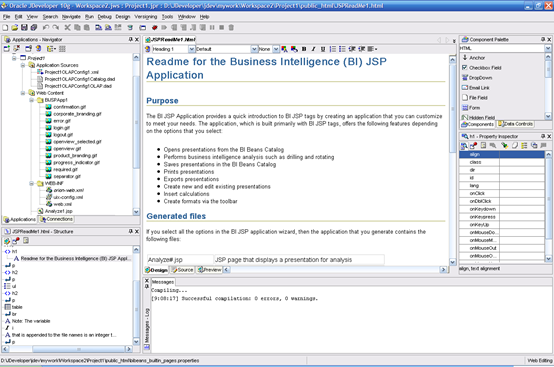
- 在Project1上右键点击"Run"可以运行项目。
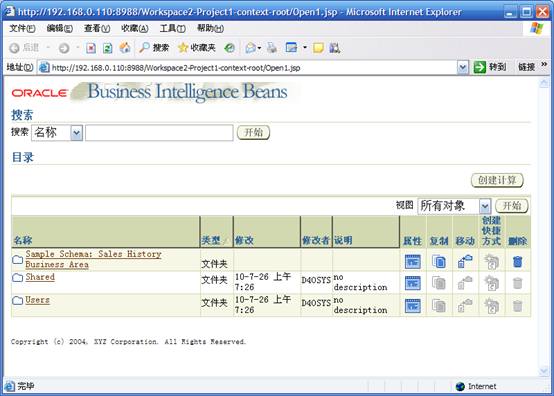
- 定位到用户BIBCAT的目录,可以创建图形和交叉表
- 将项目发布到TOMCAT
- 右键项目名称,点击"New",在左边选择"Deployment Profiles",在右边选择"WAR File",点击确定。
- 输入Profile Name
- 确定后弹出属性页
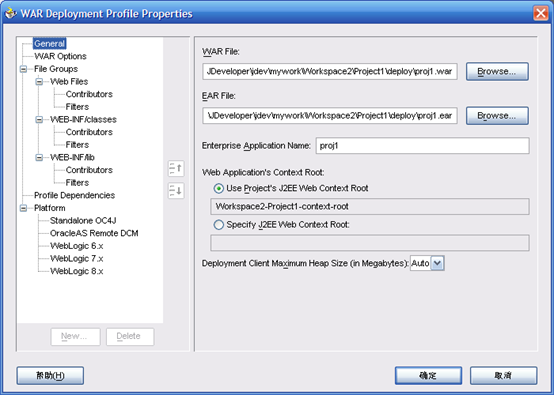
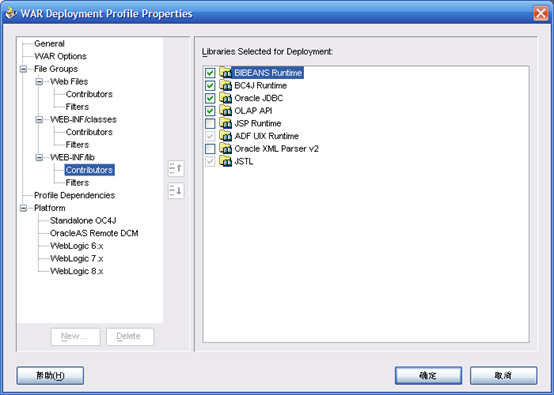
- 右键Project1,点工程属性
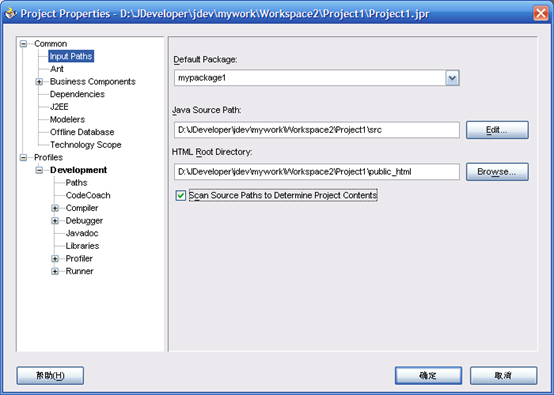
- 右键Project1,选择"Rebuild"
- 在proj1.deploy上点右键,选择"Deploy to",选择"New Connection"定义一个tomcat的连接,然后重新执行"Deploy to"-"tomcat的连接名"
- 启动tomcat,访问项目http://localhost:8080/proj1/Open1.jsp
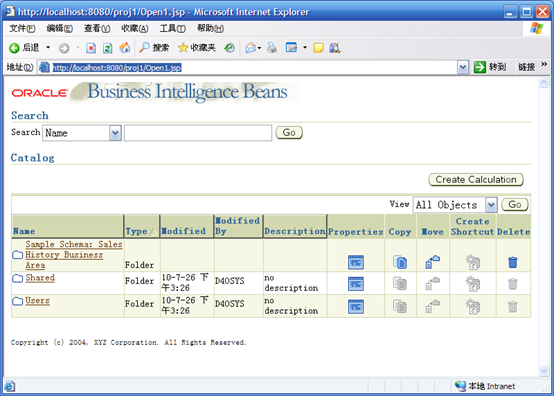
- 此时BI Beans的部分显示的是英文,需要停止Tomcat,到Tomcat的webapps\proj1\WEB-INF\lib目录下,将后缀为zip的改成jar,然后再启动Tomcat,显示的就是中文了
六、名词术语解释
数据仓库(Data warehouse)
本世纪80年代中期,"数据仓库之父"William H.Inmon先生在其《建立数据仓库》一书中定义了数据仓库的概念,随后又给出了更为精确的定义:数据仓库是在企业管理和决策中面向主题的、集成的、与时间相关的、不可修改的数据集合。与其他数据库应用不同的是,数据仓库更像一种过程,对分布在企业内部各处的业务数据的整合、加工和分析的过程。而不是一种可以购买的产品。
数据集市(Data mart)
即数据集市,或者叫做"小数据仓库"。如果说数据仓库是建立在企业级的数据模型之上的话。那么数据集市就是企业级数据仓库的一个子集,他主要面向部门级业务,并且只面向某个特定的主题。数据集市可以在一定程度上缓解访问数据仓库的瓶颈。
联机分析处理(OLAP)
联机分析处理(OLAP)的概念最早是由关系数据库之父E.F.Codd于1993年提出的。当时,Codd认为联机事务处理(OLTP)已不能满足终端用户对数据库查询分析的需要,SQL对大数据库进行的简单查询也不能满足用户分析的需求。用户的决策分析需要对关系数据库进行大量计算才能得到结果,而查询的结果并不能满足决策者提出的需求。因此Codd提出了多维数据库和多维分析的概念,即OLAP。Codd提出OLAP的12条准则来描述OLAP系统:
准则1 OLAP模型必须提供多维概念视图
准则2 透明性准则
准则3 存取能力推测
准则4 稳定的报表能力
准则5 客户/服务器体系结构
准则6 维的等同性准则
准则7 动态的稀疏矩阵处理准则
准则8 多用户支持能力准则
准则9 非受限的跨维操作
准则10 直观的数据操纵
准则11 灵活的报表生成
准则12 不受限的维与聚集层次
关系型联机分析处理(ROLAP)
基于Codd的12条准则,各个软件开发厂家见仁见智,其中一个流派,认为可以沿用关系型数据库来存储多维数据,于是,基于稀疏矩阵表示方法的星型结构(starschema)就出现了。后来又演化出雪花结构。为了与多维数据库相区别,则把基于关系型数据库的OLAP称为Relational OLAP,简称ROLAP。代表产品有Informix Metacube、Microsoft SQL Server、OLAP Services.
多维型联机分析处理(MOLAP)
严格遵照Codd的定义,自行建立了多维数据库,来存放联机分析系统数据的Arbor Software,开创了多维数据存储的先河,后来的很多家公司纷纷采用多维数据存储。被人们称为MuiltDimension OLAP,简称MOLAP,代表产品有Hyperion(原Arbor software) Essbase、Showcase STRATEGY等。
客户端联机分析处理(Client OLAP)
相对于Server OLAP而言。部分分析工具厂家建议把部分数据下载到本地,为用户提供本地的多维分析。代表产品有Brio Designer, Business Object.
决策支持系统(DSS)
决策支持系统(Decision Support system),相当于基于数据仓库的应用。决策支持就是在收集所有有关数据和信息,经过加工整理,来为企业决策管理层提供信息,为决策者的决策提供依据。
数据抽取、转换、加载(ETL)
数据抽取(Extract)、转换(Transform)、清洗(Cleansing)、装载(Load)的过程。构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。
即席查询(Ad hoc query)
即席查询,数据库应用最普遍的一种查询,利用数据仓库技术,可以让用户随时可以面对数据库,获取所希望的数据。
领导信息系统(EIS)
领导信息系统(Executive Information System),指为了满足无法专注于计算机技术的领导人员的信息查询需求,而特意制定的以简单的图形界面访问数据仓库的一种应用。
业务流程重整(BPR)
业务流程重整(Business Process Reengineering),指利用数据仓库技术,发现并纠正企业业务流程中的弊端的一项工作。数据仓库的重要作用之一。
商业智能(BI)
商业智能(Business Intelligence),指数据仓库相关技术与应用的通称。指利用各种智能技术,来提升企业的商业竞争力。
数据挖掘(Data mining)
数据挖掘,Data Mining是一种决策支持过程,它主要基于AI、机器学习、统计学等技术,高度自动化地分析企业原有的数据,作出归纳性的推理,从中挖掘出潜在的模式,预测客户的行为,帮助企业的决策者调整市场策略,减少风险,作出正确的决策。
客户关系管理(CRM)
客户关系管理(Customer Relationship management),数据仓库是以数据库技术为基础但又与传统的数据库应用有着本质区别的新技术,CRM就是基于数据仓库技术的一种新应用。但是,从商业运作的角度来讲,CRM其实应该算是一个古老的"应用"了。比如,酒店对客人信息的管理,如果某个客人是某酒店的老主顾,那么该酒店很自然地会知道这位客人的某些习惯和喜好,如是否喜欢靠路边,是否吸烟,是否喜欢大床,喜欢什么样的早餐,等等。当客人再次光临时,不用客人自己提出来,酒店就会提供客人所喜欢的房间和服务。这就是一种CRM.
元数据(Meta Data)
元数据,关于数据仓库的数据,指在数据仓库建设过程中所产生的有关数据源定义,目标定义,转换规则等相关的关键数据。同时元数据还包含关于数据含义的商业信息,所有这些信息都应当妥善保存,并很好地管理。为数据仓库的发展和使用提供方便。
维度(Dimension)
维度是用来反映业务的一类属性,这类属性的集合构成一个维度。如时间、地理位置或产品,
粒度(Granularity)
粒度将直接决定所构建仓库系统能够提供决策支持的细节级别。粒度越高表示仓库中的数据较粗,反之,较细。粒度是与具体指标相关的,具体表现在描述此指标的某些可分层次维的维值上。例如,时间维度,时间可以分成年、季、月、周、日等。
指标/度量(Measure)
指标也称关键性能指标、事实或关键事务指标,是沿维度衡量商务信息的工具。每一个指标代表了业务对象所固有的一个可供分析的属性。指标是典型的数量、容量或将通过同标准的比较查明的款项。这些数据点可用于商务性能的定量的比较。
指标/度量组(Relation Measures)
实际上每一组用于分析的业务对象会有若干相互关联的指标,如营业额、纳税额。这些指标之间存在计算关系,往往是作为一个整体用于分析的,这个整体称之为指标组。
元数据(Metadata)
关于数据的数据。元数据用于描述数据仓库中的数据的结构、内容和数据源。
元数据库(Metadata Repository)
一种提供数据详细情况的词典。这些详细的信息包括数据源的目录和它们相关的标准。该数据目录描述的是数据捕捉和数据访问两种环境中可用的数据。该目录还应说明数据最后一次更新的时间和计划将要更新的时间—最起码,要说明数据维护的调度。数据目录还应说明数据的物理属性;也就是说,数据是如何存储的。数据目录帮助数据用户弄清楚"从哪里"可获得"什么样"的数据。
中央数据库(Center Database)
数据仓库中用于存储原始数据的存储介质。此处的原始数据指从业务系统中采集后经过清洗、转换的数据。
指标数据库(Indicator Databases)
数据仓库中用于存放指标数据的存储介质。指标数据库根据数据仓库系统的使用对象划分,通常分成多个。
数据清洗(Data Cleaning)
对数据仓库系统无用的或者不符合数据格式规范的数据称之为脏数据。清洗的过程就是清除脏数据的过程。
数据采集(Data Collection)
数据仓库系统中后端处理的一部分。数据采集过程是指从业务系统中收集与数据仓库各指标有关的数据。
数据转换(Data Transformation)
解释业务数据并修改其内容,使之符合数据仓库数据格式规范,并放入数据仓库的数据存储介质中。数据转换包括数据存储格式的转换以及数据表示符的转换(如产品代码到产品名称的转换)。
联机分析处理(OLAP)
在线事务处理(on-line transaction processing,简称OLTP)能够提供一些记录级查询功能,现在分析人员要求从各个角度去观察一些统计指标,会对多张表千万条中的数据进行分析和信息综合。这是操作型应用力不从心的。1993年,关系数据库之父E.F.Codd将这类技术定义为在线分析处理(on-line analytical processing,简称OLAP)。
OLAP是一种多维分析技术,用来满足决策用户在大量的业务数据中,从多角度探索业务活动的规律性、市场的运作趋势的分析需求,并辅助他们进行战略发展决策的制定。按照数据的存储方式分OLAP又分为ROLAP、MOLAP和HOLAP。
在客户信息数据仓库CCDW的数据环境下,OLAP提供上钻、下钻、切片、旋转等在线分析机制。完成的功能包括多角度实时查询、简单的数据分析,并辅之于各种图形展示分析结果。
星形图(Star-Schema)
是数据仓库应用程序的最佳设计模式。它的命名是因其在物理上表现为中心实体,典型内容包括指标数据、辐射数据,通常是有助于浏览和聚集指标数据的维度。星形图模型得到的结果常常是查询式数据结构,能够为快速响应用户的查询要求提供最优的数据结构。星形图还常常产生一种包含维度数据和指标数据的两层模型。
雪花图(Snowflake-Schema)
指一种扩展的星形图。星形图通常生成一个两层结构,即只有维度和指标,雪花图生成了附加层。实际数据仓库系统建设过程中,通常只扩展三层:维度(维度实体)、指标(指标实体)和相关的描述数据(类目细节实体)超过三层的雪花图模型在数据仓库系统中应该避免。因为它们开始像更倾向于支持OLTP 应用程序的规格化结构,而不是为数据仓库和OLAP应用程序而优化的非格式化结构。
最新文章
- 《Javascript高级程序设计》读书笔记(1-3章)
- [DUBBO]Dubbo控制台查看方法
- 转载:WinForm中播放声音的三种方法
- [BI项目记]-搭建代码管理环境之签入代码
- jqGird 学习记录
- OAF_文件系列12_实现OAF导出PDF方式TemplateHelper
- Qt控制台中文乱码问题
- Java代码块
- Remastersys打包你自己的ubuntu成iso文件,保存原来的所有配置
- 每个项目单独配置 git 用户
- 编译安装zabbix
- MySQL server has gone away 解决方法
- jvm005 从jvm的角度谈谈线程的实现
- 统一网络控制器Func
- Odoo薪酬管理 公式配置
- Spring cloud定义学习
- net core体系-web应用程序-4asp.net core2.0 项目实战(1)-2项目说明和源码下载
- typescript 01 认识ts和ts的类型
- 【Linux】【Selenium】安装Chrome和ChromeDriver的配置
- hdu 1025