python实战之原生爬虫(爬取熊猫主播排行榜)
2024-10-20 08:45:10
"""
this is a module,多行注释
"""
import re
from urllib import request
# BeautifulSoup:解析数据结构 推荐库 Scrapy:爬虫框架
#爬虫,反爬虫,反反爬虫
#ip 封
#代理ip库
class Spider():
url='https://www.panda.tv/cate/lol'
root_pattern='<div class="video-info">([\s\S]*?)</div>'
name_pattern='</i>([\s\S]*?)</span>'
number_pattern='<span class="video-number">([\s\S]*?)</span>'
def __fetch_content(self):
r=request.urlopen(Spider.url)
htmls=r.read()
htmls=str(htmls,encoding='utf-8')
return htmls
a=1
def __analysis(self,htmls):
root_html=re.findall(Spider.root_pattern,htmls)
anchors=[]
for html in root_html:
name=re.findall(Spider.name_pattern,html)
number=re.findall(Spider.number_pattern,html)
anchor={'name':name,'number':number}
anchors.append(anchor)
return anchors
def __refine(self,achors):
l=lambda anchor:{'name':anchor['name'][0].strip(),'number':anchor['number'][0]}
return map(l,achors)
def __sort(self,anchors):
anchors=sorted(anchors,key=self.__sord_seed,reverse=True)
return anchors
def __show(self,anchors):
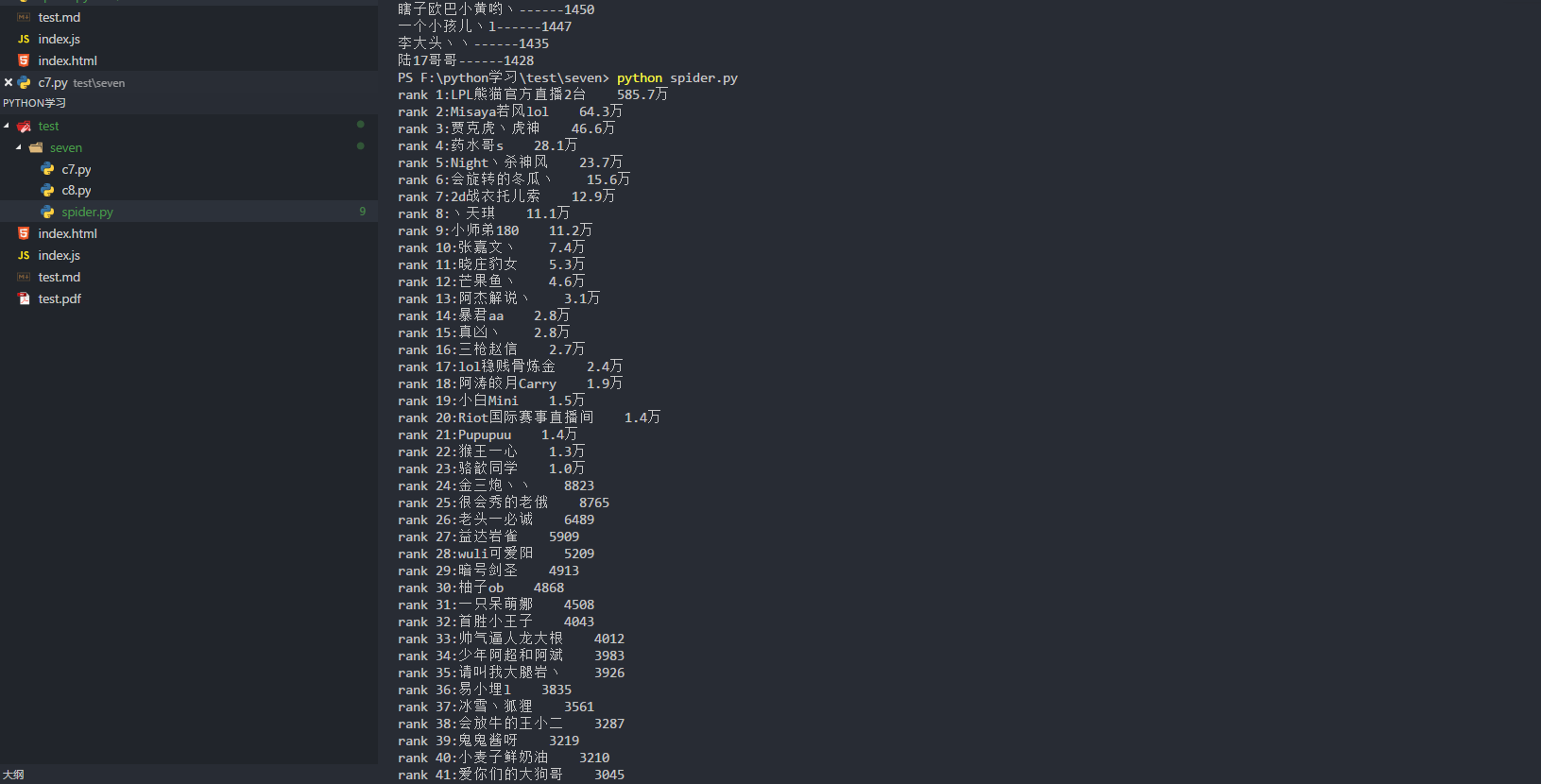
for rank in range(0,len(anchors)):
print('rank '+str(rank+1)+':'+anchors[rank]['name']
+' '+anchors[rank]['number']
)
def __sord_seed(self,anchor):
r=re.findall('\d*',anchor['number'])
number= float(r[0])
if '万' in anchor['number']:
number*=10000
return number
def go(self):
htmls=self.__fetch_content()
anchors=self.__analysis(htmls)
anchors=list(self.__refine(anchors))
anchors=self.__sort(anchors)
self.__show(anchors)
splider=Spider()
splider.go()
最新文章
- Java 程序的内存泄露问题分析
- 解决httpServletRequest.getParameter获取不到参数
- bower 问题
- CSS裁剪clip
- Sublime Text 2 中文 GBK 规范的配置 暨 解决中文乱码问题 简述
- 怎样使用AutoLayOut为UIScrollView添加约束
- Windows 8.1 归档 —— Step 2 对新系统的少量优化
- 解析xlsx文件---Java读取Excel2007
- HDU 5166(缺失数查找输出)
- java中的IO二
- 如何在程序中动态设置墙纸(使用IActiveDesktop接口)
- OSI模型第四层传输层--UDP协议
- 转发:招聘一个靠谱的 iOS
- python编程快速上手之第4章实践项目参考答案
- StringBuffer类的构造方法
- Timestamp “时间戳” - 术语
- Python高性能编程
- Codeforces 1027D Mouse Hunt (强连通缩点 || DFS+并查集)
- 【JMeter】教程及技巧汇总(转载)
- 如何让ajax执行完后再继续往下执行