WebsiteCrawler
看到网上不少py的爬虫功能极强大,可惜对py了解的不多,以前尝试过使用c# WebHttpRequert类来读取网站的html页面源码,然后通过正则表达式筛选出想要的结果,但现在的网站中,多数使用js动态加载,对于获取内容一直没有头绪,之前的一些代码也比较老,一些网站的改版和反爬的使用造成很多以前的规则都无法使用了,看了基于C#.NET的高端智能化网络爬虫(二)(攻破携程网)的源码决定自己用c#做一个小爬虫项目试一试,也来学习一下思路。
思路
1.爬虫其实只是替代用户去浏览、记录想要访问网站的一些信息,理论上和我们自己手动打开浏览器所能看见的东西是一样的。
2.网站中有ajax提交请求的部分,爬虫须模拟用户触发提交并等待页面的再次加载完成。
3.页面加载完成后,得到页面的文件内容,通过分析其规律性,筛选出想要的内容并记录。
4.继续触发页面事件,直到完全获得我们想要的数据。
轮子
1.C#多线程使用webbrowser实现采集动态网页的爬虫机器人
4.基于C#.NET的高端智能化网络爬虫(二)(攻破携程网)(主要参考)[GITHUB]
待解决的问题
1.爬虫替代用户浏览,如何能完整的获取出页面源码内容。
2.如何模拟用户触发页面事件。
3.如何等待页面动态内容执行完成。
4.翻页应该如何处理。
5.将爬取出来的数据保存。
6.提取配置,让一套代码可以通过设置爬取不同的网站。
开始
1.使用vs新建项目WebSiteCrawler:本地环境win7,vs2012,.NET Framework4.5
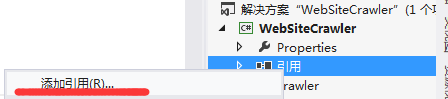
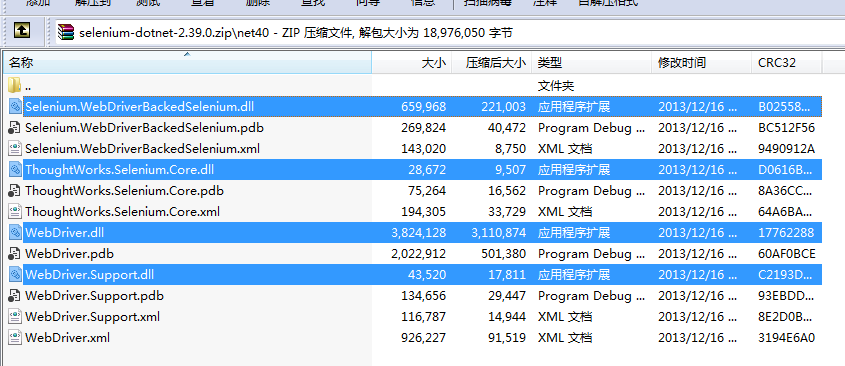
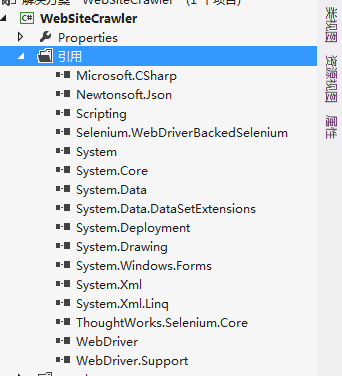
1.下载Selenium [selenium版本大全]:将项目下4个dll文件加入项目
1.1
1.2
1.3
2.下载phantomjs:将exe文件复制出来,放入项目/bin/debug/plugin文件夹下

3.创建爬虫接口crawler/ICrawler及涉及到的类,来创建爬虫的基础功能。
public interface ICrawler
{
/// <summary>
/// 爬虫启动
/// </summary>
event EventHandler<OnStartEventArgs> OnStart;
/// <summary>
/// 爬虫完成
//</summary>
event EventHandler<OnComplateEventArgs> OnComplate;
/// <summary>
/// 出现错误
/// </summary>
event EventHandler<OnErrorEventArg> OnError;
/// <summary>
/// 当前页爬取完成
/// </summary>
event EventHandler<OnComplateALLEventArgs> OnOnComplateAll; /// <summary>
/// 启动爬虫进程
/// </summary>
/// <param name="uri"></param>
/// <param name="script"></param>
/// <param name="operation"></param>
/// <returns></returns>
Task Start(Uri uri, Script script, Operation operation);
}
ICrawler
public class OnStartEventArgs
{
private Uri uri; public Uri Uri
{
get { return uri; }
set { uri = value; }
} public OnStartEventArgs(Uri uri)
{
this.uri = uri;
}
}
OnStartEventArgs
public class OnComplateEventArgs
{
/// <summary>
/// 地址
/// </summary>
private Uri uri; public Uri Uri
{
get { return uri; }
set { uri = value; }
}
/// <summary>
/// 线程Id
/// </summary>
private int threadId; public int ThreadId
{
get { return threadId; }
set { threadId = value; }
}
/// <summary>
/// 页面源码
/// </summary>
private string pageSource; public string PageSource
{
get { return pageSource; }
set { pageSource = value; }
}
/// <summary>
/// 爬虫请求执行事件
/// </summary>
private long milliseconds; public long Milliseconds
{
get { return milliseconds; }
set { milliseconds = value; }
} private IWebDriver webDriver; public IWebDriver WebDriver
{
get { return webDriver; }
set { webDriver = value; }
} public OnComplateEventArgs(Uri uri, int threadId, string pageSource, long milliseconds, IWebDriver webDriver)
{
this.uri = uri;
this.threadId = threadId;
this.pageSource = pageSource;
this.milliseconds = milliseconds;
this.webDriver = webDriver;
}
OnComplateEventArgs
public class OnErrorEventArg
{
private Uri uri; public Uri Uri
{
get { return uri; }
set { uri = value; }
}
private Exception exception; public Exception Exception
{
get { return exception; }
set { exception = value; }
} public OnErrorEventArg(Uri uri, Exception exception)
{
this.uri = uri;
this.exception = exception;
}
}
OnErrorEventArg
public class OnComplateALLEventArgs
{
public OnComplateALLEventArgs()
{
}
}
OnComplateALLEventArgs
public class Script
{
private string code; public string Code
{
get { return code; }
set { code = value; }
} private object[] args; public object[] Args
{
get { return args; }
set { args = value; }
}
}
Script
public class Operation
{
public Action<PhantomJSDriver> Action; public Func<IWebDriver, bool> Condition; private int timeout = ; public int Timeout
{
get { return timeout; }
set { timeout = value; }
}
}
Operation
这里添加了爬虫爬取数据的一些阶段事件(OnStart/OnComplate/OnError/OnComplateAll)和异步Start开始爬取方法。Start方法的参数中,Script类用于处理执行js相关的操作(没有特殊操作值为null),Operation类用于设置访问的一些参数(事件/条件/超时时间等),我们会在接下来的实现类中发现其使用方法。
4.创建 爬虫实现类 WebsiteCrawler,实现接口ICrawler
public class WebsiteCrawler : ICrawler
{
public event EventHandler<OnStartEventArgs> OnStart; public event EventHandler<OnComplateEventArgs> OnComplate; public event EventHandler<OnErrorEventArg> OnError; public event EventHandler<OnComplateALLEventArgs> OnOnComplateAll;
/// <summary>
/// PhantomJS内核参数
/// </summary>
private PhantomJSOptions _options;
/// <summary>
/// Selenium驱动设置
/// </summary>
private PhantomJSDriverService _service; public WebsiteCrawler(string proxy = null)
{
this._options = new PhantomJSOptions();//定义PhantomJS的参数配置对象
this._service = PhantomJSDriverService.CreateDefaultService(Environment.CurrentDirectory + "//plugin");//初始化Selenium配置,传入存放phantomjs.exe文件的目录
_service.IgnoreSslErrors = true;//忽略证书错误
_service.WebSecurity = false;//禁用网页安全
// _service.HideCommandPromptWindow = true;//隐藏弹出窗口
_service.LoadImages = false;//禁止加载图片
_service.LocalToRemoteUrlAccess = true;//允许使用本地资源响应远程 URL
_options.AddAdditionalCapability(@"phantomjs.page.settings.userAgent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36");
if (proxy != null)
{
_service.ProxyType = "HTTP";//使用HTTP代理
_service.Proxy = proxy;//代理IP及端口
}
else
{
_service.ProxyType = "none";//不使用代理
} } public async Task Start(Uri uri, Script script, Operation operation)
{
await Task.Run(() =>
{
//执行OnStart
if (this.OnStart != null) this.OnStart(this, new OnStartEventArgs(uri));
var driver = new PhantomJSDriver(_service, _options); try
{
var watch = DateTime.Now;
//请求地址
driver.Navigate().GoToUrl(uri.ToString());
//执行js
if (script != null) driver.ExecuteScript(script.Code, script.Args); #region 等待操作完成 //执行动作
if (operation.Action != null) operation.Action.Invoke(driver);
//开始执行,设置超时时间
var driverWait = new WebDriverWait(driver, TimeSpan.FromMilliseconds(operation.Timeout));
//执行常用判断
if (operation.Condition != null) driverWait.Until(operation.Condition); #endregion //获取数据
var threadId = System.Threading.Thread.CurrentThread.ManagedThreadId;
var milliseconds = DateTime.Now.Subtract(watch).Milliseconds;
var pageSource = driver.PageSource; if (this.OnComplate != null) this.OnComplate(this, new OnComplateEventArgs(uri, threadId, pageSource, milliseconds, driver));
}
catch (Exception ex)
{
this.OnError(this, new OnErrorEventArg(uri, ex));
}
finally
{
driver.Close();
driver.Quit();
//此处当前页全部爬去完成
if (this.OnOnComplateAll != null) this.OnOnComplateAll(this, new OnComplateALLEventArgs());
} });
} }
WebsiteCrawler
至此,我们将url中的页面元素,通过使用Selenium+PhanotmJS方式获取到了,页面元素的代码存放在driver.PageSource中,这种方式获取到的源码,和用户使用浏览器访问,等待ajax执行完成后右键查看源代码所看见的是一样的,这里就解决了ajax请求获取不到源码的问题,只要是浏览器上正常显示的,都可以获取到。下面我们只需要解析筛选driver.PageSource中的元素,就可以提取出我们想要取得的内容了。通过调用Start方法,读取完的页面数据 最终以参数形式被传递到了OnComplate事件中,调用时只需要实现OnComplate事件,就可以获取到页面元素了。
5.driver.PageSource解析
Selenium+PhanotmJS方式提供了一套良好的页面元素解析的方法,主要使用FindElements方法,获取列表元素,然后对单个元素使用FindElement方法来获取单个元素(不存在会触发异常),这两个方法需要使用一个By.XPath类型。举例:获取糗百页面的列表
var list = (IWebDriver)webDriver.FindElements(By.XPath("//div[@id='content-left']/div"));
最新文章
- C# 学习电子书资料分享mobi epub等格式
- (转)android Fragments详解二:创建Fragment
- Delphi的Socket编程步骤
- 51nod1201 整数划分
- NOI2005维修数列
- .Net 把网页Html转PDF文件
- java log日志的输出。
- EventBus3 简单使用及注意点
- java里面List和Array的区别是什么?
- JAVA二维数组小记
- MySQL分类表设计--根据ID删除全部子类
- 针对Chrome谷歌等浏览器不再支持showModalDialog的解决方案
- Extensions in UWP Community Toolkit - Mouse Cursor
- linux 下启动java jar包 shell
- linux | 网卡驱动
- Nginx软件优化【转】
- 集合03_Map
- 【转载】 强化学习(五)用时序差分法(TD)求解
- 图片切换(手动切换,imagelist的单独使用)
- vue 面试时需要准备的知识点