Hadoop实战:reduce端实现Join
2024-09-05 07:50:53
项目描述
现在假设有两个数据集:气象站数据库和天气记录数据库,并考虑如何合二为一。一个典型的查询是:输出气象站的历史信息,同时各行记录也包含气象站的元数据信息。
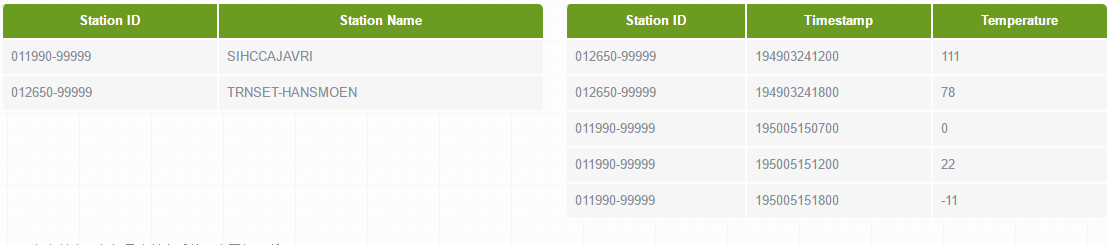
气象站和天气记录合并之后的示意图如下所示。

测试数据
启动Hadoop集群,然后在hdfs中创建join文件夹用于存放测试数据station.txt和records.txt,他们分别代表气象站数据库和天气记录数据库。
项目代码
JoinStationMapper.java
package com.hadoop.Join; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /**
* @author Zimo
*
*/
public class JoinStationMapper extends Mapper<LongWritable,Text,TextPair,Text>
{
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException
{
String line = value.toString();
String[] arr = line.split("\\s+");//解析气象站数据
int length = arr.length;
if(length==)
{//满足这种数据格式
//key=气象站id value=气象站名称
System.out.println("station="+arr[]+"");
context.write(new TextPair(arr[],""),new Text(arr[]));
}
}
}
JoinRecordMapper.java
package com.hadoop.Join; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /**
* @author Zimo
*
*/
public class JoinRecordMapper extends Mapper<LongWritable,Text,TextPair,Text>
{
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException
{
String line = value.toString();
String[] arr = line.split("\\s+",);//解析天气记录数据
int length = arr.length;
if(length==){
//key=气象站id value=天气记录数据
context.write(new TextPair(arr[],""),new Text(arr[]));
}
}
}
TextPair.java
package com.hadoop.Join; import java.io.*;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable; /**
* @author Zimo
*
*/
public class TextPair implements WritableComparable<TextPair>
{
private Text first; //Text 类型的实例变量first
private Text second;//Text 类型的实例变量second public TextPair() //无参构造方法
{
set(new Text(),new Text());
}
public TextPair(String first,String second) // Sting类型参数的构造方法
{
set(new Text(first),new Text(second));
}
public TextPair(Text first,Text second) // Text类型参数的构造方法
{
set(first,second);
}
public void set(Text first,Text second) //set方法
{
this.first=first;
this.second=second;
}
public Text getFirst() //getFirst方法
{
return first;
}
public Text getSecond() //getSecond方法
{
return second;
} //将对象转换为字节流并写入到输出流out中
@Override //------------ 序列化
public void write(DataOutput out) throws IOException //write方法
{
first.write(out);
second.write(out);
} //从输入流in中读取字节流反序列化为对象
@Override //------------反 序列化
public void readFields(DataInput in) throws IOException //readFields方法
{
first.readFields(in);
second.readFields(in);
} @Override
public int hashCode() //在mapreduce中,通过hashCode来选择reduce分区
{
return first.hashCode() *163+second.hashCode();
} @Override
public boolean equals(Object o) //equals方法,这里是两个对象的内容之间比较
{
if (o instanceof TextPair)
{
TextPair tp=(TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
} @Override
public String toString() //toString方法
{
return first +"\t"+ second;
}
@Override
public int compareTo(TextPair o)
{
// TODO Auto-generated method stub
if(!first.equals(o.first))
{
return first.compareTo(o.first);
}
else if(!second.equals(o.second))
{
return second.compareTo(o.second);
}
return 0;
} }
JoinReducer.java
package com.hadoop.Join; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /**
* @author Zimo
*
*/
public class JoinReducer extends Reducer< TextPair,Text,Text,Text>
{
protected void reduce(TextPair key, Iterable< Text> values,Context context) throws IOException,InterruptedException
{
Iterator< Text> iter = values.iterator();
Text stationName = new Text(iter.next());//气象站名称
while(iter.hasNext()){
Text record = iter.next();//天气记录的每条数据
Text outValue = new Text(stationName.toString()+"\t"+record.toString());
context.write(key.getFirst(),outValue);
}
}
}
JoinRecordWithStationName.java
package com.hadoop.Join; import java.io.InputStream;
import org.apache.hadoop.util.Tool;
import java.io.OutputStream;
import java.util.Set; import javax.lang.model.SourceVersion; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.ToolRunner; /**
* @author Zimo
*
*/
public class JoinRecordWithStationName extends Configured implements Tool
{
public static class KeyPartitioner extends Partitioner< TextPair,Text>
{ public int getPartition(TextPair key,Text value,int numPartitions)
{
return (key.getFirst().hashCode()&Integer.MAX_VALUE) % numPartitions;
}
} public static class GroupingComparator extends WritableComparator
{
protected GroupingComparator()
{
super(TextPair.class,true);
}
@Override
public int compare(WritableComparable w1,WritableComparable w2)
{
TextPair ip1=(TextPair) w1;
TextPair ip2=(TextPair) w2;
Text l=ip1.getFirst();
Text r=ip2.getFirst();
return l.compareTo(r); }
}
public int run(String[] args) throws Exception
{
Configuration conf = new Configuration();// 读取配置文件 Path mypath=new Path(args[]);
FileSystem hdfs=mypath.getFileSystem(conf);
if (hdfs.isDirectory(mypath))
{
hdfs.delete(mypath,true);
} Job job = Job.getInstance(conf,"join");// 新建一个任务
job.setJarByClass(JoinRecordWithStationName.class);// 主类 Path recordInputPath = new Path(args[]);//天气记录数据源,这里是牵扯到多路径输入和多路径输出的问题。默认是从args[0]开始
Path stationInputPath = new Path(args[]);//气象站数据源
Path outputPath = new Path(args[]);//输出路径 //若只有一个输入和一个输出,则输入是args[0],输出是args[1]。
//若有两个输入和一个输出,则输入是args[0]和args[1],输出是args[2] MultipleInputs.addInputPath(job,recordInputPath,TextInputFormat.class,JoinRecordMapper.class);//读取天气记录Mapper
MultipleInputs.addInputPath(job,stationInputPath,TextInputFormat.class,JoinStationMapper.class);//读取气象站Mapper
FileOutputFormat.setOutputPath(job,outputPath);
job.setReducerClass(JoinReducer.class);// Reducer
job.setNumReduceTasks(); job.setPartitionerClass(KeyPartitioner.class);//自定义分区
job.setGroupingComparatorClass(GroupingComparator.class);//自定义分组 job.setMapOutputKeyClass(TextPair.class);
job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); return job.waitForCompletion(true)?:;
} public static void main(String[] args) throws Exception
{
String[] args0={"hdfs://centpy:9000/join/records.txt"
,"hdfs://centpy:9000/join/station.txt"
,"hdfs://centpy:9000/join/out"
};
int exitCode=ToolRunner.run( new JoinRecordWithStationName(), args0);
System.exit(exitCode);
}
}
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
最新文章
- Centos 7 Docker、docker-compose、Registrator、Consul、Consul Template和Nginx实现高可扩展的Web框架
- 我的第一个GitHub仓库
- 第七次课:ssh的集成(SpringMV+Spring+Hibernate)
- html5 canvas 粒子特效
- HDU(4528),BFS,2013腾讯编程马拉松初赛第五场(3月25日)
- Struts2框架学习(一)
- PHP curl请求https遇到的坑
- DBdbvis数据库驱动连接问题
- spark shuffle
- Angular4.x跨域请求
- PeopleSoft进程卡在“已排队”状态诊断和解决
- org.apache.catalina.LifecycleException: Failed to stop component(生命周期异常)
- 中间人攻击之ettercap嗅探
- ubuntu系统初始化网络及mysql配置
- 使用dtc把dtb的反编译为dts
- json字符串和Json对象,以及json的基本了解
- expect 交互
- Discuz常见小问题-如何禁止调整宽屏模式
- windows下apache利用SSL来配置https
- js实现loading简单的遮套层
热门文章
- 【转】 Pro Android学习笔记(二二):用户界面和控制(10):自定义Adapter
- [快手(AAuto)学习笔记]如何让程序在运行时请求管理员权限(UAC)
- lua 函数调用 -- 闭包详解和C调用
- JConsole远程监控配置
- how to download a file with Nodejs(without using third-party libraries)用node下载文件
- 阶段3-团队合作\项目-网络安全传输系统\sprint3-账号管理子系统设计\第2课-账号管理子系统设计
- struts2知识点汇总
- SqlServer2012-创建表、删除表 增加字段 删除字段操作
- C#将PDF转换为图片的方法
- .Net Core WebApi返回日期格式的问题