HashMap底层实现原理及扩容机制
HashMap的数据结构:数组+链表+红黑树;Java7中的HashMap只由数组+链表构成;Java8引入了红黑树,提高了HashMap的性能;借鉴一张图来说明,原文:https://www.jianshu.com/p/8324a34577a0
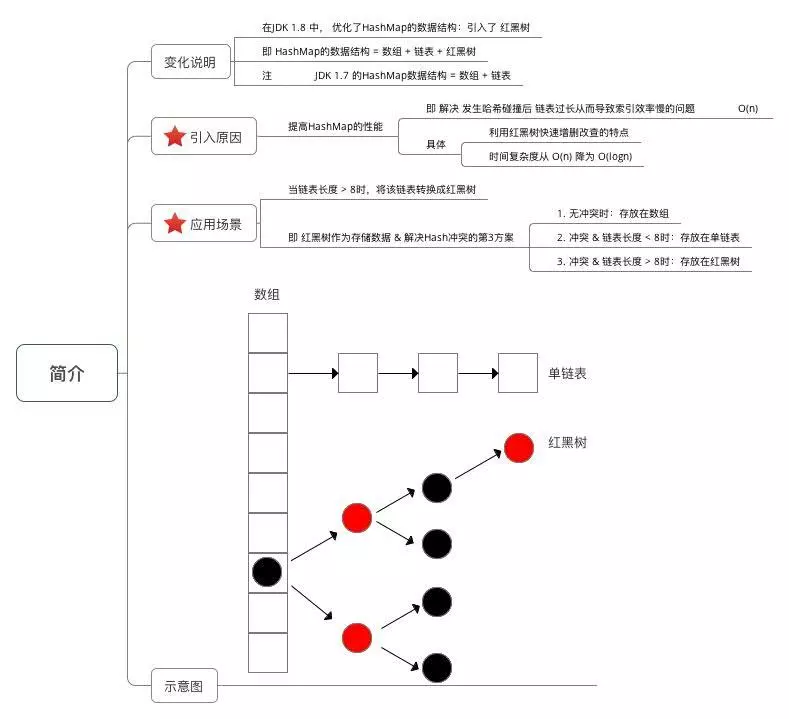
下面简单说一下存储过程:
1.接受传入的参数,通过key计算hash值,得到数组下标位置;未发生hash碰撞,直接插入结束;发生hash碰撞,走第2步;
2.判断当前数据节点是红黑树还是链表,如果是链表,将数据放入链表头节点,原数据往后移;如果是红黑树,走第3步;
3.直接在红黑树插入数据结束;
HashMap数组元素和链表使用Node类实现,同Java7中使用Entry类实现是一样的,只是换了名字而已;Node是HashMap静态内部类,实现了Map.Entry接口;同样有以下4个重要属性:
final int hash; // 哈希值,HashMap根据该值确定记录的位置
final K key; // key
V value; // value
Node<K,V> next;// 链表下一个节点
红黑树采用的是TreeNode类实现,它继承了LinkedHashMap.Entry类
下面是HasMap的一些重要参数:
/**
* 主要参数 同 JDK 1.7
* 即:容量、加载因子、扩容阈值(要求、范围均相同)
*/ // 1. 容量(capacity): 必须是2的幂 & <最大容量(2的30次方)
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认容量 = 16 = 1<<4 = 00001中的1向左移4位 = 10000 = 十进制的2^4=16
static final int MAXIMUM_CAPACITY = 1 << 30; // 最大容量 = 2的30次方(若传入的容量过大,将被最大值替换) // 2. 加载因子(Load factor):HashMap在其容量自动增加前可达到多满的一种尺度
final float loadFactor; // 实际加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认加载因子 = 0.75 // 3. 扩容阈值(threshold):当哈希表的大小 ≥ 扩容阈值时,就会扩容哈希表(即扩充HashMap的容量)
// a. 扩容 = 对哈希表进行resize操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数
// b. 扩容阈值 = 容量 x 加载因子
int threshold; // 4. 其他
transient Node<K,V>[] table; // 存储数据的Node类型 数组,长度 = 2的幂;数组的每个元素 = 1个单链表
transient int size;// HashMap的大小,即 HashMap中存储的键值对的数量 /**
* 与红黑树相关的参数
*/
// 1. 桶的树化阈值:即 链表转成红黑树的阈值,在存储数据时,当链表长度 > 该值时,则将链表转换成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 2. 桶的链表还原阈值:即 红黑树转为链表的阈值,当在扩容(resize())时(此时HashMap的数据存储位置会重新计算),在重新计算存储位置后,当原有的红黑树内数量 <时,则将 红黑树转换成链表
static final int UNTREEIFY_THRESHOLD = 6;
// 3. 最小树形化容量阈值:即 当哈希表中的容量 > 该值时,才允许树形化链表 (即 将链表 转换成红黑树)
// 否则,若桶内元素太多时,则直接扩容,而不是树形化
// 为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD
static final int MIN_TREEIFY_CAPACITY = 64; 作者:Carson_Ho
链接:https://www.jianshu.com/p/8324a34577a0
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
HashMap的加载因子:
加载因子越大:空间利用越高,扩容前填充的元素越多,put操作较快;但是链表容易过长,hash碰撞几率较大,get操作较慢;
加载因子越小:get操作较快,链表短,hash碰撞几率低;但是空间利用率低,put元素过多会导致频繁扩容,影响性能;
个人觉得我们在使用HashMap的时候,如果预先知道大概要操作的元素数量,最好给一个初始化值,首先尽量避免扩容,其次根据业务场景结合重要参数来设定一些值来提高使用效率;
HashMap的扩容原理:我们都知道Java中数组是无法自动扩容的,HashMap的方法是使用一个新的数组代替原有的数组,对原数组的所有数据进行重新计算插入新数组,之后指向新数组;如果扩容前数组已经达到最大了,那么将直接将阈值设置成最大整形return;
HashMap每次扩容增长一倍,例如HashMap初始容量为16,加载因子0.75,当容量达到12的时候进行扩容,扩容到2的5次幂;
最新文章
- 基于python的文件处理
- etl学习系列1——etl工具安装
- AppScan8.0简单扫描
- Mysql存储引擎
- 鸟哥的linux私房菜勘误表
- 如何查看hadoop与hbase的版本匹配关系
- excel 经验总结
- String Split 和 Join
- php中setcookie函数用法详解(转)
- 打破C++ Const 的规则
- memcached在项目中的应用
- isFile() exists() isDirectory()的区别
- 原创:实现ehcache动态创建cache,以及超期判断的具体逻辑
- css常见属性
- [SHOI2017]相逢是问候
- ubuntu导入公钥的方法
- 【java】-- java反射机制
- linux io的cfq代码理解
- [math][mathematica] archlinux 下 mathematica 的安装 (科学计算软件 mathematica/matlab/sagemath)
- 自动换行后缩进怎么做(CSS)?(可用于 Li y 元素的排版)