java对象详解
java对象及线程详解
HotSpot虚拟机中,对象在内存中存储的布局可以分为
对象头,实例数据,对齐填充三个区域。本文所说环境均为HotSpot虚拟机。即输入java -version返回的虚拟机版本:
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
内存布局
普通对象布局
在jvm中,任何对象都是8个字节为粒度进行对齐的,这是对象内存布局的第一个规则。
如果调用new Object(),由于Object类并没有其他没有其他可存储的成员,那么仅仅使用堆中的8个字节来保存两个字的头部即可。
除了上面所说的8个字节的头部(关于对象头,在下面会有详细解释),类属性紧随其后。属性通常根据其大小来排列。例如,整型(int)以4个字节为单位对齐,长整型(long)以8个字节为单位对齐。这里是出于性能考虑而这么设计的:通常情况下,如果数据以4字节为单位对齐,那么从内存中读4字节的数据并写入到处理器的4字节寄存器是性价比更高的。
为了节省内存,Sun VM并没有按照属性声明时的顺序来进行内存布局。实际上,属性在内存中按照下面的顺序来组织:
双精度型(doubles)和长整型(longs)
整型(ints)和浮点型(floats)
短整型(shorts)和字符型(chars)
布尔型(booleans)和字节型(bytes)
引用类型(references)
内存使用率会通过这个机制得到优化。例如,如下声明一个类:
class MyClass {
byte a;
int c;
boolean d;
long e;
Object f;
}
如果JVM并没有打乱属性的声明顺序,其对象内存布局将会是下面这个样子:
[HEADER: 8 bytes] 8
[a: 1 byte ] 9
[padding: 3 bytes] 12
[c: 4 bytes] 16
[d: 1 byte ] 17
[padding: 7 bytes] 24
[e: 8 bytes] 32
[f: 4 bytes] 36
[padding: 4 bytes] 40
此时,用于占位的14个字节是浪费的,这个对象一共使用了40个字节的内存空间。但是,如果用上面的规则对这些对象重新排序,其内存结果会变成下面这个样子:
[HEADER: 8 bytes] 8
[e: 8 bytes] 16
[c: 4 bytes] 20
[a: 1 byte ] 21
[d: 1 byte ] 22
[padding: 2 bytes] 24
[f: 4 bytes] 28
[padding: 4 bytes] 32
这次,用于占位的只有6个字节,这个对象使用了32个字节的内存空间。
规则2:类属性按照如下优先级进行排列:长整型和双精度类型;整型和浮点型;字符和短整型;字节类型和布尔类型,最后是引用类型。这些属性都按照各自的单位对齐。
现在我们知道如何计算一个继承了Object的类的实例的内存大小了。下面这个例子用来做下练习: java.lang.Boolean。这是其内存布局:
[HEADER: 8 bytes] 8
[value: 1 byte ] 9
[padding: 7 bytes] 16
Boolean类的实例占用16个字节的内存!惊讶吧?(别忘了最后用来占位的7个字节)。
规则3:不同类继承关系中的成员不能混合排列。首先按照规则2处理父类中的成员,接着才是子类的成员。
举例如下:
class A {
long a;
int b;
int c;
}
class B extends A {
long d;
}
类B的实例在内存中的存储如下:
[HEADER: 8 bytes] 8
[a: 8 bytes] 16
[b: 4 bytes] 20
[c: 4 bytes] 24
[d: 8 bytes] 32
如果父类中的成员的大小无法满足4个字节这个基本单位,那么下一条规则就会起作用:
规则4:当父类中最后一个成员和子类第一个成员的间隔如果不够4个字节的话,就必须扩展到4个字节的基本单位。
class A {
byte a;
}
class B {
byte b;
}
[HEADER: 8 bytes] 8
[a: 1 byte ] 9
[padding: 3 bytes] 12
[b: 1 byte ] 13
[padding: 3 bytes] 16
注意到成员a被扩充了3个字节以保证和成员b之间的间隔是4个字节。这个空间不能被类B使用,因此被浪费了。
规则5:如果子类第一个成员是一个双精度或者长整型,并且父类并没有用完8个字节,JVM会破坏规则2,按照整形(int),短整型(short),字节型(byte),引用类型(reference)的顺序,向未填满的空间填充。
class A {
byte a;
}
class B {
long b;
short c;
byte d;
}
[HEADER: 8 bytes] 8
[a: 1 byte ] 9
[padding: 3 bytes] 12
[c: 2 bytes] 14
[d: 1 byte ] 15
[padding: 1 byte ] 16
[b: 8 bytes] 24
在第12字节处,类A“结束”的地方,JVM没有遵守规则2,而是在长整型之前插入一个短整型和一个字节型成员,这样可以避免浪费3个字节。
数组的内存布局
数组有一个额外的头部成员,用来存放“长度”变量。数组元素以及数组本身,跟其他常规对象同样,都需要遵守8个字节的边界规则。
下面是一个有3个元素的字节数组的内存布局:
[HEADER: 12 bytes] 12
[[0]: 1 byte ] 13
[[1]: 1 byte ] 14
[[2]: 1 byte ] 15
[padding: 1 byte ] 16
下面是一个有3个元素的长整型数字的内存布局:
[HEADER: 12 bytes] 12
[padding: 4 bytes] 16
[[0]: 8 bytes] 24
[[1]: 8 bytes] 32
[[2]: 8 bytes] 40
内部类的内存布局
非静态内部类(Non-static inner classes)有一个额外的“隐藏”成员,这个成员是一个指向外部类的引用变量。这个成员是一个普通引用,因此遵守引用内存布局的规则。内部类因此有4个字节的额外开销。
对象分解
对象头-mark word(8字节)
对象头主要包含两部分信息,第一部分用于存储对象自身运行时数据,如哈希码,GC分代年龄(可以查看上一篇关于java内存回收分析的文章),锁状态标志,线程持有锁,偏向线程ID,偏向时间戳等。
如果对象是数组类型,则虚拟机用3个字宽存储对象头,如果是非数组类型,则用2个字宽存储对象头。下图是一个32位虚拟机mark部分占用内存分布情况
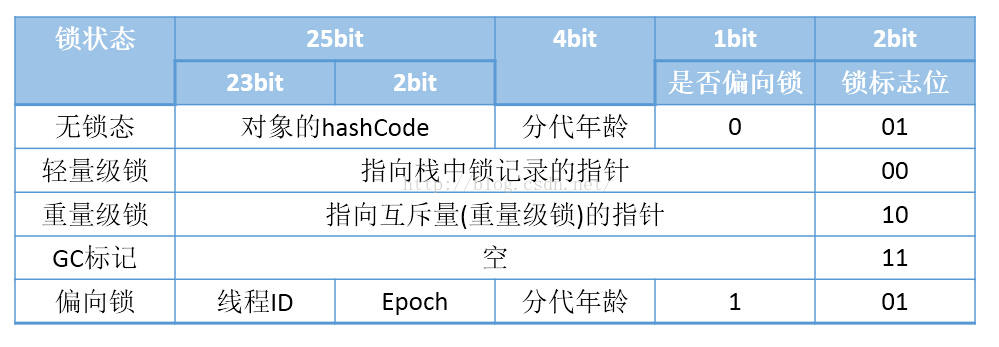
此图来源:http://blog.csdn.net/zhoufanyang_china/article/details/54601311
另一部分是klass类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例,具体结构参考下图。
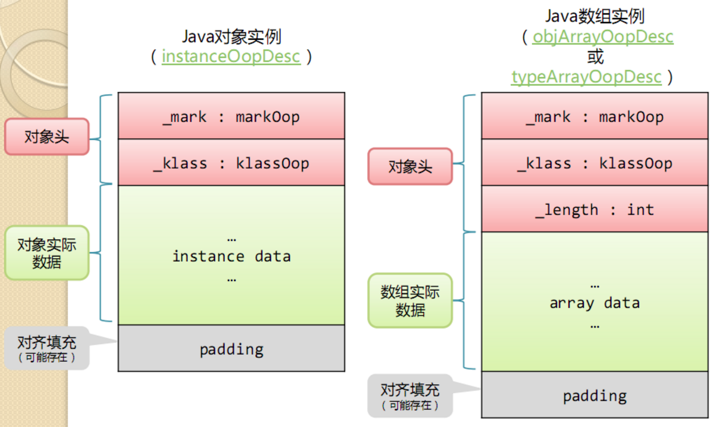
在32位系统下,存放Class指针的空间大小是4字节,MarkWord是4字节,对象头为8字节。
在64位系统下,存放Class指针的空间大小是8字节,MarkWord是8字节,对象头为16字节。
64位开启指针压缩的情况下,存放Class指针的空间大小是4字节,MarkWord是8字节,对象头为12字节。
数组长度4字节+数组对象头8字节(对象引用4字节(未开启指针压缩的64位为8字节)+数组markword为4字节(64位未开启指针压缩的为8字节))+对齐4=16字节。
静态属性不算在对象大小内。
实例数据
对象实际数据,大下为实际数据的大小
对齐填充(可选)
按8字节对齐,参照上面内存布局部分
java锁分析
synchronized到底锁的是对象还是代码片段?
例:
package com.startclan.thread;
/**
* Created by wongloong on 17-5-20.
*/
public class TestSync {
public synchronized void test() {
System.out.println("test1 start");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("test1 end");
}
public synchronized void test2() {
System.out.println("test2 start");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("test2 end");
}
}
package com.startclan.thread;
/**
* Created by wongloong on 17-5-20.
*/
public class TestSyncStatic {
public static synchronized void test() {
System.out.println("test1 start");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("test1 end");
}
public static synchronized void test2() {
System.out.println("test2 start");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("test2 end");
}
}
package com.startclan;
import com.startclan.thread.TestSync;
import com.startclan.thread.TestSyncStatic;
import org.junit.Test;
/**
* Created by wongloong on 17-5-18.
*/
public class TestWithThread {
@Test
public void testThread1() throws Exception {
final TestSync t1 = new TestSync();
/**
* 测试synchronized同步非static代码块
* 此处会先执行test方法然后执行test2方法,说明synchronized在同步非static方法时,
* 只能同步同一对象的同一实例进行同步
*/
new Thread(new Runnable() {
@Override
public void run() {
t1.test();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
t1.test2();
}
}).start();
Thread.sleep(4000);
}
@Test
public void testThread2() throws Exception {
final TestSync t1 = new TestSync();
final TestSync t2 = new TestSync();
/**
* 测试synchronized同步非static代码块
* t1 t2不同对象,
* 不能同步方法
*/
new Thread(new Runnable() {
@Override
public void run() {
t1.test();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
t2.test2();
}
}).start();
Thread.sleep(4000);
}
@Test
public void testThread3() throws Exception {
final TestSyncStatic tss1 = new TestSyncStatic();
final TestSyncStatic tss2 = new TestSyncStatic();
/**
* 测试synchronized 同步 static代码块
* 由于method1和method2都属于静态同步方法,
* 所以调用的时候需要获取同一个类上monitor(每个类只对应一个class对象),
* 所以也只能顺序的执行。
*/
new Thread(new Runnable() {
@Override
public void run() {
tss1.test();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
tss2.test2();
}
}).start();
Thread.sleep(4000);
}
}
此时输出结果为:
------------------------1-------------------------
test1 start
test1 end
test2 start
test2 end
-----------------------2-------------------------
test1 start
test2 start
test2 end
test1 end
-----------------------3-------------------------
test1 start
test1 end
test2 start
test2 end
结论:
synchronized(this)以及非static的synchronized方法,只能防止多个线程同时执行同一个实例的同步代码段(在第一段测试代码中,分别new了三个Mythread类,所以并不会执行同步)
synchronized(xx.class)及static的synchronized方法,可以防止多个线程同时执行同一个对象的多个实例同步的代码段
synchronize原理
每一个对象头信息都包含一个锁定状态,可以看上面的mark word的图解。当线程进入对象中,尝试获取锁的所有权,如果为锁的值为0,则该线程进入,并设置为1,该线程为锁的拥有者。如果线程已经占用该锁,只是重新进入,并且锁值+1.当线程退出时则-1.如果其他线程访问这个对象实例,则改线程堵塞。直到锁值为0的时候,在重新尝试取得锁的所有权。
volatile关键字
用volatile修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最新的值而不是线程内的变量副本。volatile很容易被误用,用来进行原子性操作。
volatile保证此变量对所有的线程的可见性,当一个线程修改了这个变量的值,volatile 保证了新值能立即同步到主内存,以及每次使用前立即从主内存刷新。但普通变量做不到这点,普通变量的值在线程间传递均需要通过主内存来完成。
volatile禁止指令重排序优化。
volatile原理
在jvm内存分析中,可以知道2栈(虚拟机栈,本地方法栈)及程序计数器是线程私有的。也就是每一个线程运行时都有一个“2栈”,这2栈中保存了线程运行时的变量信息。先线程访问某一个对象值的时候,首先通过对象引用找到对应在堆(公有)内存变量的值,然后把堆内存变量的具体值加载到线程本地中,建立一个变量副本,之后线程就不再和堆内存中的变量值有关系,而是直接修改线程本地的变量副本的值,在修改完成后的某一时刻(线程退出前),再把线程中变量副本的值回写到对象在堆内存中的变量。这样堆中对象的值就会发生变化。对于volatile修饰的变量,jvm只保证从主内存加载到线程工作内存的值是最新的。并不能保证同步。
例如假如线程1,线程2 在进行read,load 操作中,发现主内存中count的值都是5,那么都会加载这个最新的值
在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6
线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6
导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。
扩展阅读:http://www.infoq.com/cn/articles/ftf-java-volatile
多线程sleep/wait/yield/notify/notifyAll区别
1、sleep()
使当前线程(即调用该方法的线程)暂停执行一段时间,让其他线程有机会继续执行,但它并不释放对象锁。也就是说如果有synchronized同步快,其他线程仍然不能访问共享数据。注意该方法要捕捉异常。
例如有两个线程同时执行(没有synchronized)一个线程优先级为MAX_PRIORITY,另一个为MIN_PRIORITY,如果没有Sleep()方法,只有高优先级的线程执行完毕后,低优先级的线程才能够执行;但是高优先级的线程sleep(500)后,低优先级就有机会执行了。
总之,sleep()可以使低优先级的线程得到执行的机会,当然也可以让同优先级、高优先级的线程有执行的机会。2、join()
join()方法使调用该方法的线程在此之前执行完毕,也就是等待该方法的线程执行完毕后再往下继续执行。注意该方法也需要捕捉异常。3、yield()
该方法与sleep()类似,只是不能由用户指定暂停多长时间,并且yield()方法只能让同优先级的线程有执行的机会。yield也不会放弃锁。4、wait()和notify()、notifyAll()
这三个方法用于协调多个线程对共享数据的存取,所以必须在synchronized语句块内使用。synchronized关键字用于保护共享数据,阻止其他线程对共享数据的存取,但是这样程序的流程就很不灵活了,如何才能在当前线程还没退出synchronized数据块时让其他线程也有机会访问共享数据呢?此时就用这三个方法来灵活控制。
wait()可以设置wait时间,如果设置了时间就不用notify。到时间后会自动唤醒继续执行。
wait()方法使当前线程暂停执行并释放对象锁标示,让其他线程可以进入synchronized数据块,当前线程被放入对象等待池中。当调用notify()方法后,将从对象的等待池中移走一个任意的线程并放到锁标志等待池中,只有锁标志等待池中线程能够获取锁标志;如果锁标志等待池中没有线程,则notify()不起作用。
notifyAll()则从对象等待池中移走所有等待那个对象的线程并放到锁标志等待池中。
@Test
public void testThreadAndYield() throws Exception {
Thread producer = new Thread(new Runnable() {
@Override
public void run() {
testMethod("producer", 1000);
}
});
Thread consumer = new Thread(new Runnable() {
@Override
public void run() {
testMethod("consumer", 10);
}
});
producer.start();
consumer.start();
producer.join();
}
public synchronized void testMethod(String name, int waitTime) {
System.out.println(Thread.currentThread().getId());
try {
wait(waitTime);
//wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("test method name is " + name);
}
竟态条件
定义:线程A 需要判断一个变量的状态,然后根据这个变量的状态来执行某个操作。在执行这个操作之前,这个变量的状态可能会被其他线程修改
eg:简单的单例模式
public class LazyInitRace {
private ExpensiveObject instance=null;
public ExpensiveObject getInstance(){
if(instance==null){
instance=new ExpensiveObject();
}
return instance;
}
}
在LazyInitRace 中包含了一个竞态条件,它可能会破坏这个类的正确性。假定线程A和线程B 同时执行getInstance 方法。A 看到instance 为空,因此A创建一个新的ExpensiveObject实例。B 同样需要判断instance 是否为空。此时的instance是否为空,要取决于不可预测的时序,包括线程的调度方式,以及A 需要花多长时间来初始化ExpensiveObject并设置instance。如果当B检查时,instance为空,那么在两次调用getInstance 时可能会得到不同的对象。
线程间共享数据
通过wait()释放锁,及notify()来唤醒组合进行共享数据
package com.startclan.thread;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.LinkedList;
import java.util.Queue;
/**
* Created by wongloong on 17-5-22.
*/
public class TestShare {
public static void main(String args[]) throws InterruptedException {
final Queue sharedQ = new LinkedList();
Thread producer = new Producer(sharedQ);
Thread consumer = new Consumer(sharedQ);
producer.start();
consumer.start();
Thread.sleep(10000);
}
}
class Producer extends Thread {
private static final Logger logger = LoggerFactory.getLogger(Producer.class);
private final Queue sharedQ;
public Producer(Queue sharedQ) {
super("Producer");
this.sharedQ = sharedQ;
}
@Override
public void run() {
for (int i = 0; i < 4; i++) {
synchronized (sharedQ) {
//waiting condition - wait until Queue is not empty
while (sharedQ.size() >= 1) {
try {
logger.info("Queue is full, waiting");
sharedQ.wait();
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
logger.info("producing : " + i);
sharedQ.add(i);
sharedQ.notify();
}
}
}
}
class Consumer extends Thread {
private static final Logger logger = LoggerFactory.getLogger(Consumer.class);
private final Queue sharedQ;
public Consumer(Queue sharedQ) {
super("Consumer");
this.sharedQ = sharedQ;
}
@Override
public void run() {
while (true) {
synchronized (sharedQ) {
//waiting condition - wait until Queue is not empty
while (sharedQ.size() == 0) {
try {
logger.info("Queue is empty, waiting");
sharedQ.wait();
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
int number = (int) sharedQ.poll();
logger.info("consuming : " + number);
sharedQ.notify();
//termination condition
if (number == 3) {
break;
}
}
}
}
}
为什么wait,notify,notifyAll这些方法不在Thread类里面?
这是个设计相关的问题,一个很明显的原因是JAVA提供的锁是对象级的而不是线程级的,每个对象都有锁,通过线程获得。如果线程需要等待某些锁那么调用对象中的wait()方法就有意义了。如果wait()方法定义在Thread类中,线程正在等待的是哪个锁就不明显了。简单的说,由于wait,notify和notifyAll都是锁级别的操作,所以把他们定义在Object类中因为锁属于对象。
什么是ThreadLocal变量?
ThreadLocal是Java里一种特殊的变量。每个线程都有一个ThreadLocal就是每个线程都拥有了自己独立的一个变量,竞争条件被彻底消除了。它是为创建代价高昂的对象获取线程安全的好方法,比如你可以用ThreadLocal让SimpleDateFormat变成线程安全的,因为那个类创建代价高昂且每次调用都需要创建不同的实例所以不值得在局部范围使用它,如果为每个线程提供一个自己独有的变量拷贝,将大大提高效率。首先,通过复用减少了代价高昂的对象的创建个数。其次,你在没有使用高代价的同步或者不变性的情况下获得了线程安全。线程局部变量的另一个不错的例子是ThreadLocalRandom类,它在多线程环境中减少了创建代价高昂的Random对象的个数
ThreadLocal详解
翻译成中文名为线程局部变量。功能简单,就是为每一个使用该变量的线程都提供一个变量值的副本。
每个线程的变量副本是存储在哪里的?
看一下ThreadLocal的set源码
//ThreadLocal源文件
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);//第一次设置值的时候,如果没有map则创建一个map
}
//创建一个Map,并且设置Thread的threadLocals指向新创建的ThreadLocalMap,并且以当前的ThreadLocal作为key初始。看一下Thread.threadlocals是什么?
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
//Thread源文件
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
通过源码的分析,可以知道,变量最终是存储在Thread中的。而不是ThreadLocal中。一个线程中可以存在多个ThreadLocal,他们以ThreadLocal为key形成的map存储在线程中。
ThreadLocal初始化
知道了ThreadLocal的原理,现在来看一下ThreadLocal的初始化,设置默认值
public static final ThreadLocal<Integer> local = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
return 0;
}
};
内存泄漏问题
在上面提到过,每个thread中都存在一个map, map的类型是ThreadLocal.ThreadLocalMap. Map中的key为一个threadlocal实例. 这个Map的确使用了弱引用,不过弱引用只是针对key. 每个key都弱引用指向threadlocal. 当把threadlocal实例置为null以后,没有任何强引用指向threadlocal实例,所以threadlocal将会被gc回收. 但是,我们的value却不能回收,因为存在一条从current thread连接过来的强引用. 只有当前thread结束以后, current thread就不会存在栈中,强引用断开, Current Thread, Map, value将全部被GC回收.
所以得出一个结论就是只要这个线程对象被gc回收,就不会出现内存泄露,但在threadLocal设为null和线程结束这段时间不会被回收的,就发生了我们认为的内存泄露。其实这是一个对概念理解的不一致,也没什么好争论的。最要命的是线程对象不被回收的情况,这就发生了真正意义上的内存泄露。比如使用线程池的时候,线程结束是不会销毁的,会再次使用的。就可能出现内存泄露。
Java中Semaphore是什么?
java中的Semaphore是一种新的同步类,它是一个计数信号。从概念上讲,从概念上讲,信号量维护了一个许可集合。如有必要,在许可可用前会阻塞每一个 acquire(),然后再获取该许可。每个 release()添加一个许可,从而可能释放一个正在阻塞的获取者。但是,不使用实际的许可对象,Semaphore只对可用许可的号码进行计数,并采取相应的行动。信号量常常用于多线程的代码中,比如数据库连接池。
import java.util.concurrent.Semaphore;
public class SemaphoreTest {
Semaphore binary = new Semaphore(1);
public static void main(String args[]) {
final SemaphoreTest test = new SemaphoreTest();
new Thread(){
@Override
public void run(){
test.mutualExclusion();
}
}.start();
new Thread(){
@Override
public void run(){
test.mutualExclusion();
}
}.start();
}
private void mutualExclusion() {
try {
binary.acquire();
//mutual exclusive region
System.out.println(Thread.currentThread().getName() + " inside mutual exclusive region");
Thread.sleep(1000);
} catch (InterruptedException i.e.) {
ie.printStackTrace();
} finally {
binary.release();
System.out.println(Thread.currentThread().getName() + " outside of mutual exclusive region");
}
}
}
Output:
Thread-0 inside mutual exclusive region
Thread-0 outside of mutual exclusive region
Thread-1 inside mutual exclusive region
Thread-1 outside of mutual exclusive region
Read more: http://javarevisited.blogspot.com/2012/05/counting-semaphore-example-in-java-5.html#ixzz4htCgzO4Z
Java线程池中submit() 和 execute()方法有什么区别?
两个方法都可以向线程池提交任务,execute()方法的返回类型是void,它定义在Executor接口中, 而submit()方法可以返回持有计算结果的Future对象,它定义在ExecutorService接口中,它扩展了Executor接口,其它线程池类像ThreadPoolExecutor和ScheduledThreadPoolExecutor都有这些方法。
参考资料
http://hw1287789687.iteye.com/blog/2007134
http://javarevisited.blogspot.tw/2013/12/inter-thread-communication-in-java-wait-notify-example.html#axzz4hnY25Gh7
http://blog.csdn.net/lhqj1992/article/details/52451136
http://javarevisited.blogspot.tw/2012/05/counting-semaphore-example-in-java-5.html#axzz4hnY25Gh7
http://www.importnew.com/12773.html
最新文章
- 6、Concurrent-Mark-Sweep
- Genymotion加速下载虚拟镜像速度慢失败Connection timeout
- YTU 2295: KMP模式匹配 一(串)
- DOS下无法调出中文输入法-Solved
- Linux磁盘与文件系统管理
- Logstash安装搭建(一)
- spring 入门级程序示例
- API 友好
- iOS 按钮连续提交执行一次(如留言提交,多次拍照问题)
- 基于tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
- PTA L2-011 玩转二叉树 二叉树+bfs
- PHP 设计模式系列 —— 工厂方法模式(Factory Method)(转)
- 杀掉gpu上的程序
- Android 性能优化的一些方法
- 使用typed.js实现页面上的写字功能
- 如何把dos命令窗口里的字符复制下来?
- SQL中字符串截取、连接、替换等函数的用法
- ftp 命令行操作 经常使用命令
- CentOS安装nmon
- IPython&Jupyter私房手册