Java课程设计之——爬虫篇
主要使用的技术
- Httplcient
- Jsoup
- 多线程
- dao模式
网络爬虫简介
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。——摘自百度百科
网络爬虫分类
1. 通用网络爬虫
通用网络爬虫又称全网爬虫(Scalable Web Crawler),爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据。 由于商业原因,它们的技术细节很少公布出来。 这类网络爬虫的爬行范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于待刷新的页面太多,通常采用并行工作方式,但需要较长时间才能刷新一次页面。 虽然存在一定缺陷,通用网络爬虫适用于为搜索引擎搜索广泛的主题,有较强的应用价值。
通用网络爬虫的结构大致可以分为页面爬行模块 、页面分析模块、链接过滤模块、页面数据库、URL 队列、初始 URL 集合几个部分。为提高工作效率,通用网络爬虫会采取一定的爬行策略。 常用的爬行策略有:深度优先策略、广度优先策略。
2. 聚焦网络爬虫
聚焦网络爬虫(Focused Crawler),又称主题网络爬虫(Topical Crawler),是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。 和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网络爬虫相比,增加了链接评价模块以及内容评价模块。聚焦爬虫爬行策略实现的关键是评价页面内容和链接的重要性,不同的方法计算出的重要性不同,由此导致链接的访问顺序也不同。
3. 增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler)是 指 对 已 下 载 网 页 采 取 增 量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。 和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。增量式网络爬虫的体系结构[包含爬行模块、排序模块、更新模块、本地页面集、待爬行 URL 集以及本地页面URL集。增量式爬虫有两个目标:保持本地页面集中存储的页面为最新页面和提高本地页面集中页面的质量。
4. Deep Web 爬虫
Web 页面按存在方式可以分为表层网页(Surface Web)和深层网页(Deep Web,也称 Invisible Web Pages 或 Hidden Web)。 表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 页面。Deep Web 是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。例如那些用户注册后内容才可见的网页就属于 Deep Web。 2000 年 Bright Planet 指出:Deep Web 中可访问信息容量是 Surface Web 的几百倍,是互联网上最大、发展最快的新型信息资源。Deep Web 爬虫体系结构包含六个基本功能模块 (爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS 控制器)和两个爬虫内部数据结构(URL 列表、LVS 表)。 其中 LVS(Label Value Set)表示标签/数值集合,用来表示填充表单的数据源。
爬虫设计思路
这次是要设计基于学院的搜索引擎,所以一开始的话应该采用1或2。
通用网络爬虫设计思路

如图,通用爬虫就是使用深度或者广度搜索进行爬取,但是这种爬虫有一种缺点,就是深度不是很好控制,深度小了怕有遗漏,深度大了又怕过度浪费资源。而且还要对爬取到的链接进行解析,判断一下是不是自己想要的内容,判断是否是重复的URL,这一系列的操作导致的不仅仅是空间资源的浪费,在时间上也会耗费严重。一开始我是采用这种方法对学院官网进行爬虫的,每次爬取都需要几分钟的时间,大约三分钟吧。这还是没有去重的时间,所以后来我放弃了这种思路,决定采用先前学长的思路。
聚焦网络爬虫设计思路
实际上这也不完全是聚焦网络爬虫,因为我没有对爬取到的结果进行分析,这部分工作交给Elasticsearch去做了。
首先打开学院网站可以发现,每篇文章的url都有共通的特点:
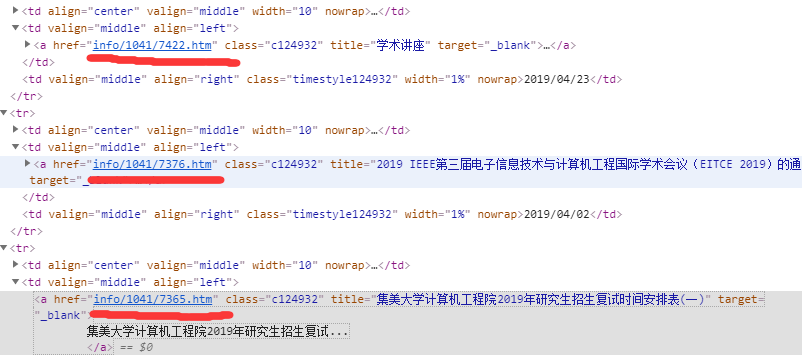
这部分我们可以使用一个正则表达式来匹配这个链接,但是这仅仅只是展示在首页的最新消息。观察可以发现每篇文章都有分类,而标题的菜单栏又有class样式


后来发现主页还有些这种url采用的不是这种class样式,我就直接用正则匹配了,多出来600多条数据
这种菜单url点进去后可以发现文章用的也是相同的class样式
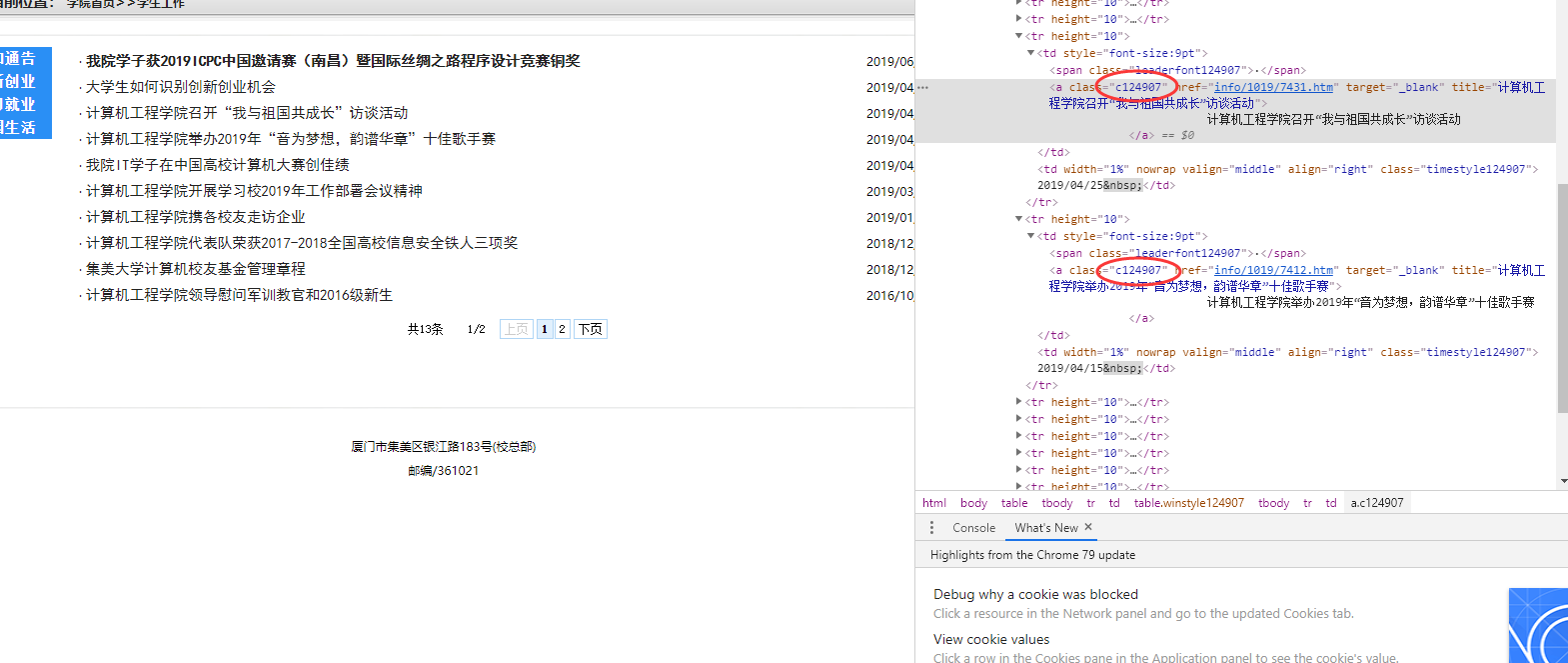
但是还有分页的文章是没办法直接在这个页面中直接获取的,学长是通过对url解析,得到总页数,然后放一个for进行迭代爬取。不过我发现了一个更好的方法,因为url中有个参数a2c是设置返回条数,也就是显示在页面上的条数的,只要给他一个很大的值就能全部显示了

代码实现(只展示关键代码)
因为考虑到爬虫可能不仅仅用于爬取URL,所以我用DAO模式设计了一个ResultWriterDao接口用于保存所需要的数据,然后实现爬虫功能的主要就两个类:
SingleCrawler.java: 对单个网页进行css解析,把页面的doc文档传入ResultWriterDao实现的类进行所需数据的保存,由于爬虫有多个线程,而ResultWriterDao只有一个,所以要对ResultWriterDao的写入方法加上synchronized。
UrlCollector.java: 利用SingleCrawler不断地迭代爬取。先获取菜单url,然后继续新建SingleCrawler线程进行文章url爬取,最后对文章的内容进行获取,存入ResultWriterDao。
ResultWriterDao.java
public interface ResultWriterDao{
/**
*
* 用于数据保存的dao接口,在类的内部定义存储方式,使用write方法写入
* @param url 传入的网页的url
* @param doc 传入的网页的document对象,可用于保存title,正文,等等
*/
public void write(String url, Document doc);
/**
* 得到保存的数据
* @return getLinks方法返回数据List
*/
@SuppressWarnings("rawtypes")
public List getLinks();
}
SingleCrawler.java
for (Element link : links) {
String newHref = link.attr("href");
String httpPattern = "^http";
Pattern p = Pattern.compile(httpPattern);
Matcher m = p.matcher(newHref);
if(m.find()){
continue;
}
String newUrl = null;
/**
* 判断href是相对路径还是决定路径,以及是否是传参
*/
if(newHref.length()>=1 && newHref.charAt(0)=='?') {
newUrl = this.url.substring(0, this.url.indexOf('?')) + newHref;
}
else if(newHref.length()>=1 && newHref.charAt(0)=='/') {
Matcher matcher = httpRegexPattern.matcher(this.url);
if(matcher.find()) {
String rootUrl = matcher.group(0);
newUrl = rootUrl + newHref.substring(1);
}
else {
continue;
}
}
else if(newHref.length()>=1 && newHref.charAt(0)!='/'){
Matcher matcher = httpRegexPattern.matcher(this.url);
if(matcher.find()) {
String rootUrl = matcher.group(0);
newUrl = rootUrl + newHref;
}
else {
continue;
}
}
else {
continue;
}
this.linksWriter.write(newUrl, doc);
}
UrlCollector.java
爬取菜单URL
String url = "http://cec.jmu.edu.cn/";
String cssSelector = "a[href~=\\.jsp\\?urltype=tree\\.TreeTempUrl&wbtreeid=[0-9]+]";
List<String> menu = null;
List<String> list = null;
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(cm).build();
LinksListWriter tempListWriter = new LinksListWriter();
/**
* 1. 第一层是Menu,先把Menu的href爬取下来
*/
SingleCrawler menuCrawler = new SingleCrawler(url, cssSelector, httpClient, tempListWriter);
menuCrawler.start();
try {
menuCrawler.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
menu = new ArrayList<String>(tempListWriter.getLinks());
爬取文章URL
这里开始使用到了多线程技术,爬取更快
SingleCrawler[] listCrawler = new SingleCrawler[menu.size()];
for (int i = 0; i < listCrawler.length; i++) {
String menuUrl = menu.get(i);
if(menuUrl.contains("?")) {
istCrawler[i] = new SingleCrawler(menu.get(i)+"&a3c=1000000&a2c=10000000", "a[href~=^info/[0-9]+/[0-9]+\\.htm]", httpClient, tempListWriter);
listCrawler[i].start();
}
else {
listCrawler[i] = null;
}
}
爬取文章内容
SingleCrawler[] documentCrawler = new SingleCrawler[list.size()];
for (int i = 0; i < documentCrawler.length; i++) {
documentCrawler[i] = new SingleCrawler(list.get(i), "", httpClient, resultWriter);
documentCrawler[i].start();
}
新旧对比
我将后端存储方式全部换成了ArrayList,在相同网络情况下进行JUnit测试,对比我的爬虫和学长相比看有没有提升:

可以看到运行时间相近,但是爬取得到的数据多了一倍,至此,爬虫设计完毕
最新文章
- Android初涉及之Android Studio&JAVA入门--二月不能不写东西
- Leetcode 221. Maximal Square
- 5月4日课堂内容:for循环的穷举、迭代
- (转)Log4net 配置类库
- Java线程同步_1
- Docker 监控实战
- php学习之基础语法
- (iOS)开发中收集的小方法
- MSSQl 事务的使用
- Quick Sort(三向切分的快速排序)(Java)
- windows的WSl安装mysql数据库以及操作数据库
- TypeError: Fetch argument 0.484375 has invalid type <class 'numpy.float32'>, must be a string or Tensor. (Can not convert a float32 into a Tensor or Operation.)
- JS案例六_2:省市级联动
- (转载)彻底的理解:WebService到底是什么?
- springboot项目logback配置文件示例
- jquery中选择checkbox拼接成字符串,然后到后台拆分取值
- 【Java】 剑指offer(50-2) 字符流中第一个只出现一次的字符
- Xshell远程连接 与 Xftp文件传输
- LeetCode--155--最小栈(java版)
- ksort排序的依据是什么
热门文章
- 金三银四,还在为spring源码发愁吗?bean生命周期,看了这篇就够了
- Comparing Data-Independent Acquisition and Parallel Reaction Monitoring in Their Abilities To Differentiate High-Density Lipoprotein Subclasses 比较DIA和PRM区分高密度脂蛋白亚类的能力 (解读人:陈凌云)
- android studio 添加 apache.http
- ysoserial-C3P0 分析
- pyplot 作图总结
- 粒子群优化算法(PSO)之基于离散化的特征选择(FS)(二)
- TensorFlow系列专题(五):BP算法原理
- K8S 资源收集和展示 top & DashBoard-UI
- 【NLP面试QA】激活函数与损失函数
- python pdb 转载:https://www.linuxidc.com/Linux/2017-11/148329.htm