Python-selenium-自动化测试模型
1、线性测试
优势:每一个脚本都是完整独立的,每一个脚本对应一个测试用例
缺点:开发成本高,会有重复操作重复脚本;维护成本也高,修改重复操作的脚本时,要逐一进行修改。
2、模块化驱动测试
把重复的操作独立成公共模块,当用例执行中需要这一模块操作时调用,这样最大限度的消除重复,提高测试用例的可维护性。
解决了线性测试的两个问题:
(1)提高了开发效率
(2)简化了维护复杂性
缺点:在数据会改变的情况下,会加大编写重复的脚本(比如现在我要测试不同用户登录的场景,先是张三登录,登录完后换李四登录,然后继续换用户登录,这样会有重复的登录脚本,虽然登录的步骤一样,但是登录的数据不一样)
写一个类,将登录的函数包装起来
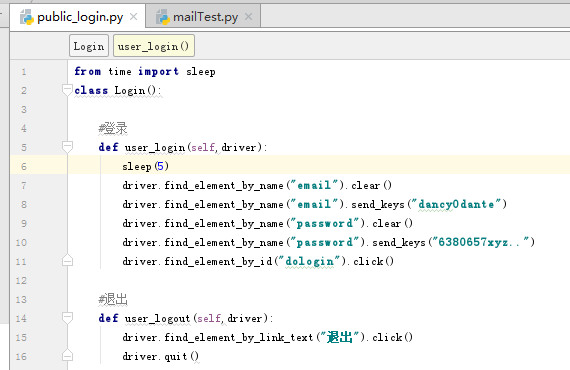
然后写个主程序调用登录的函数

3、数据驱动测试
数据驱动是数据的参数化,因为输入数据的不痛而引起输出结果的不同;比如定义的数组、字典、或者是外部文件(Excel、csv、txt、xml等)都可以看做是数据驱动,目的就是实现数据与脚本的分离。
优点:进一步增强了脚本的复用性。
(1)通过参数化来实现数据驱动
将要输入的值当做一个参数来进行传入,实现根据数据输入的不同而有不同的执行结果
登录的函数以传参的方式封装
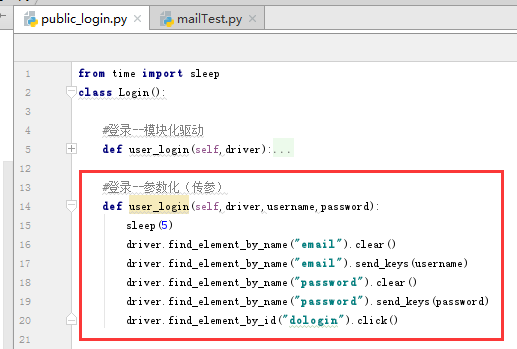
然后主方法中调用该方法,传入不同的参数

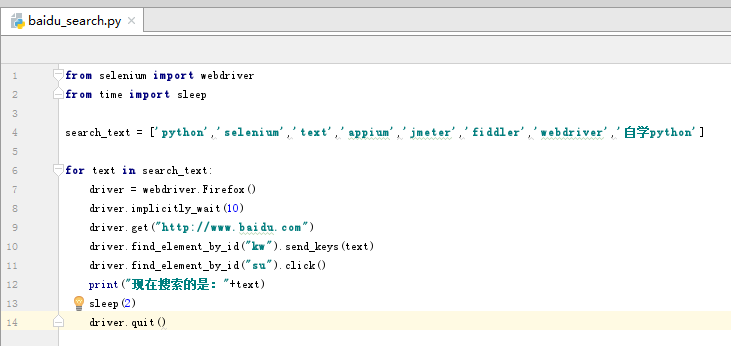
(2)参数化搜索关键字
将要搜索的关键字定义为一组数组,然后通过循环的方式进行搜索,搜索的关键字不一样测试结果也不一样。
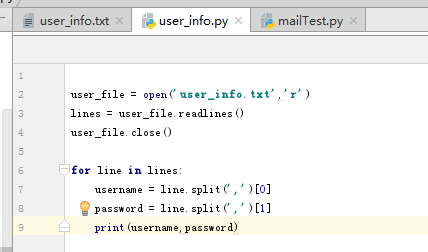
(3)读取txt文件
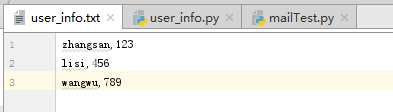
Python中提供了几种读取txt文件的方式:
read():读取整个文件
readline():读取一行数据
readlines():读取所有行的数据
(4)读取csv文件
(5)读取xml文件
parse():打开xml文件
documentElement:用于得到xml文件唯一的根元素
nodeName:节点名称
nodeValue:节点值
nodeType:节点类型
ELEMENT_NODE:元素节点类型
getElementsByTagName:可以通过标签名获取标签,获取的对象以数组的形式存储
getAttribute():用于获取元素的属性值,与webdriver中的get_attribute()类似
firstChild:属性返回被选节点的第一个子节点
data:表示获取该节点的数据,与webdriver中的text方法类似
4、关键字驱动测试
最新文章
- python基础之文件处理
- HttpWatch的时间分析
- Skype无法收发组消息
- Cornerstone详细操作
- kafka基本原理学习
- 制作大漠字库并用python调用大漠工具方法来识别文字
- Jmeter组件3. HTTP Cookie Manager
- java Joda-Time 对日期、时间操作
- php socket函数详解
- NSException
- SharePoint入门识记
- 兼容firefox的iframe高度自适应代码
- 加密算法 - RSA算法一
- Windows Server 2008 R2 域控制器部署指南
- runnable与handler结合使用,其实跟在Thread中的run()中sleep的效果是一样的
- 怎么用jq封装插件
- Android类似Periscope点赞效果
- 2017-11-8—自动控制原理在软硬件方面上的应用和体现
- canvas-8clip.html
- 修改docker的地址为阿里云源
热门文章
- [Docker02]Docker_registry
- Servlet(五)----ServletContext对象
- Building Applications with Force.com and VisualForce(Dev401)( 八):Designing Applications for Multiple Users: Controling Access to Records.
- Android对话框(Dialog)
- TensorFlow 神经机器教程-TensorFlow Neural Machine Translation Tutorial
- Web Scraper 性能测试 (-_-)
- 零基础从实践出发学java编程【总结篇】
- coding++:java-全局异常处理
- 《java编程思想》 初始化与清理
- [bzoj]1053反质数<暴搜>