FTCL:Fine-grained Temporal Contrastive Learning for Weakly-supervised Temporal Action Localization概述
1.针对的问题
现有的方法主要遵循于通过优化视频级分类目标来实现定位的方式,这些方法大多忽略了视频之间丰富的时序对比关系,因此在分类学习和分类-定位自适应的过程中面临着极大的模糊性。(1)在弱监督设置中没有足够的标注,学习的分类器本身没有足够的区别和鲁棒性,导致了动作-背景分离的困难。(2)由于分类和定位之间存在较大的任务差距,学习到的分类器通常专注于易于区分的片段,而忽略那些在定位中不突出的片段。因此,局部的时间序列往往是不完整和不精确的。
2.主要贡献
•引入了第一个用于鲁棒WSAL的区分顺序到顺序的比较框架,以解决缺乏能够利用细粒度时间差别的帧级标注的问题。
•设计了一个统一的可导动态规划公式,包括细粒度序列远程学习和最长公共子序列挖掘,该公式具有(1)区分动作背景分离和(2)缓解分类与定位之间的任务差距的优点。
•在两个常用基准上的广泛实验结果表明,提出的FTCL算法具有良好的性能。所提出的策略是与模型无关的,并且不具有干扰性,因此可以在现有方法之上发挥补充作用,从而始终如一地提高动作定位性能。
3.方法
本文认为通过考虑上下文的序列到序列对比可以为弱监督时序行为定位提供本质的归纳偏置并帮助识别连续的行为片段。在一个可导的动态规划框架下,设计了两个互补的对比目标,其中包括细粒度序列距离(FSD)对比和最长公共子序列(LCS)对比,其中,第一个通过使用匹配、插入和删除操作符来考虑各种动作/背景建议之间的关系,第二个挖掘两个视频之间最长的公共子序列。两种对比模块可以相互增强,共同享受区分动作-背景分离的优点,减轻分类和定位之间的任务差距。
细粒度序列距离(FSD)对比:考虑动作背景的分离,提高学习动作分类器的识别能力,其中将可导的匹配,插入和删除操作符用于序列之间的相似性计算,具体来说,使用学习到的CAS,可以生成各种行动/背景建议,其中行动建议U包含具有高行动激活的片段,而背景建议V恰恰相反。对于长度为M和N的两个建议序列,U=[u1,...,ui,...,uM]∈RD×M和V=[v1,...,vi,...,vM]∈RD×N,通过以下递归对它们的相似性进行评估:
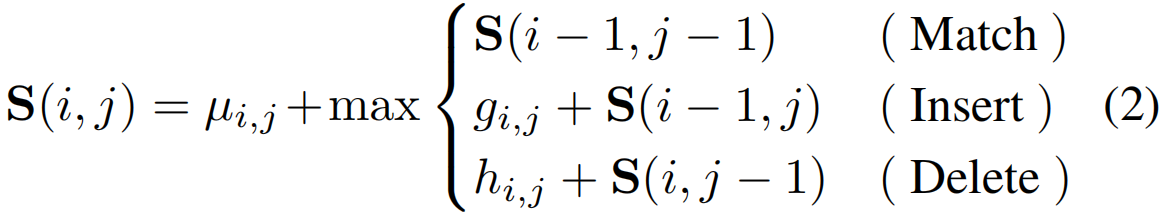
其中,子序列相似度得分S(i,j)在第一个序列U的位置i和第二个序列V的位置j上被计算。S(0,:)和S(:,0)被初始化为零。直观地说,在位置(i,j)中,如果ui和vj相匹配,则序列相似性得分应该增加。如果执行插入或删除操作,应该对相似度评分进行惩罚。为此,学习了三种类型的残差值(标量),即µi,j,gi,j和hi,j。以µi,j,gi,j为例,计算方法如下:
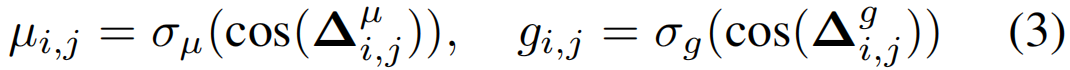
其中,∆µi,j=[fµ(ui),fµ(vj)]和∆gi,j的定义类似。fµ(·),fg(·)和fh(·)是三个全连接的层。利用这些函数来模拟不同的操作,包括匹配,插入和删除。σµ和σg是获取残差值的激活函数。由此,保证了S(i,j)是两个序列之间的最优相似度得分,显然,来自同一类别的两个行动建议之间的相似性应该大于行动建议和背景建议之间的相似性。通过利用这种关系,设计了FSD对比损失如下:
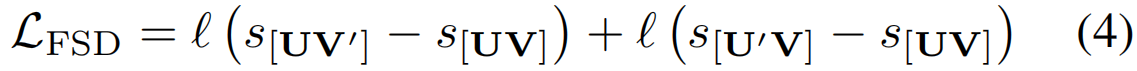
其中,ℓ(x)表示ranking loss。下标[UV]表示来自同一类别的两个计算序列到序列相似度的动作建议s=S(M,N)。U'和V'代表背景建议。由于等式(2)中的max操作是不可导的,所以作者进行了平滑,将其换为
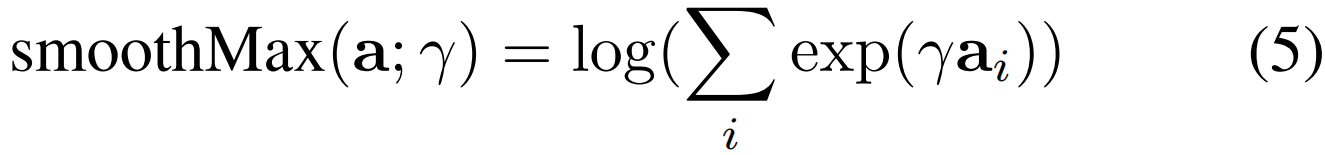
最长公共子序列(LCS)对比:在两个未裁剪的视频X和Z之间挖掘最长公共子序列(LCS),从而提高学习到的动作建议的一致性。这个想法背后的直觉是双重的:(1)如果两个视频没有共享相同的动作,那么X和Z之间的LCS长度应该很小。显然,由于两种类型的动作背景不同,差异较大,两个单独视频的片段很可能高度不一致,导致LCS较短。(2)同样的,如果两个视频共享同一个动作,那么它们的LCS很容易长,因为同一类别的动作实例是由相似的时间动作片段组成的。理想情况下,这种情况下的LCS与较短的动作实例一样长。计算公式如下:
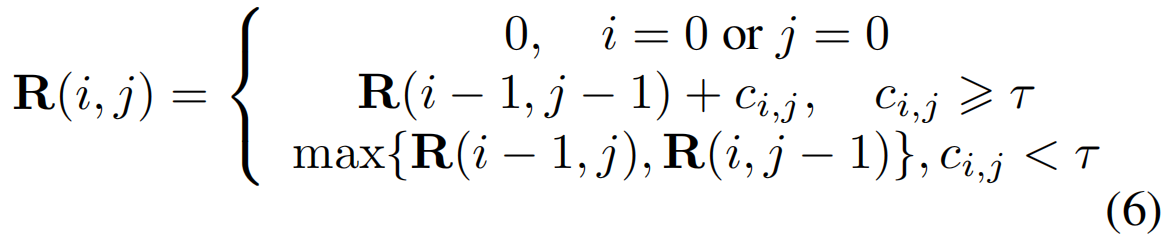
其中,τ是一个阈值,它决定了视频X的第i个片段和视频Z的第j个片段是否匹配。ci,j=cos(xi,zj)是片段xi和zj的余弦相似性。得到的结果值r = R(T, T)表示两个视频之间的最长公共子序列的soft长度。使用交叉熵损失作为约束。
讨论:其实FSD和LCS都是对序列进行对比,都有计算相似性的过程,那么是否可以只用其中一个呢?论文中特意进行了说明和实验。(1)考虑到不同类型的序列,它们的目标是不同的。我们利用FSD学习强大的行动背景分离,同时采用不同的动作和背景建议。而LCS对比性是为了在两个未裁剪的视频中找到一致的动作实例,从而实现分类到定位的适应。(2)二者具有不同的对比水平。在FSD对比中,不同的动作/背景对之间的关系被考虑,而在LCS中,对比是在一对未经裁剪的视频中进行的,而且实验也证明单独使用一种方法的性能较差。
FTCL架构和简单示例如下:
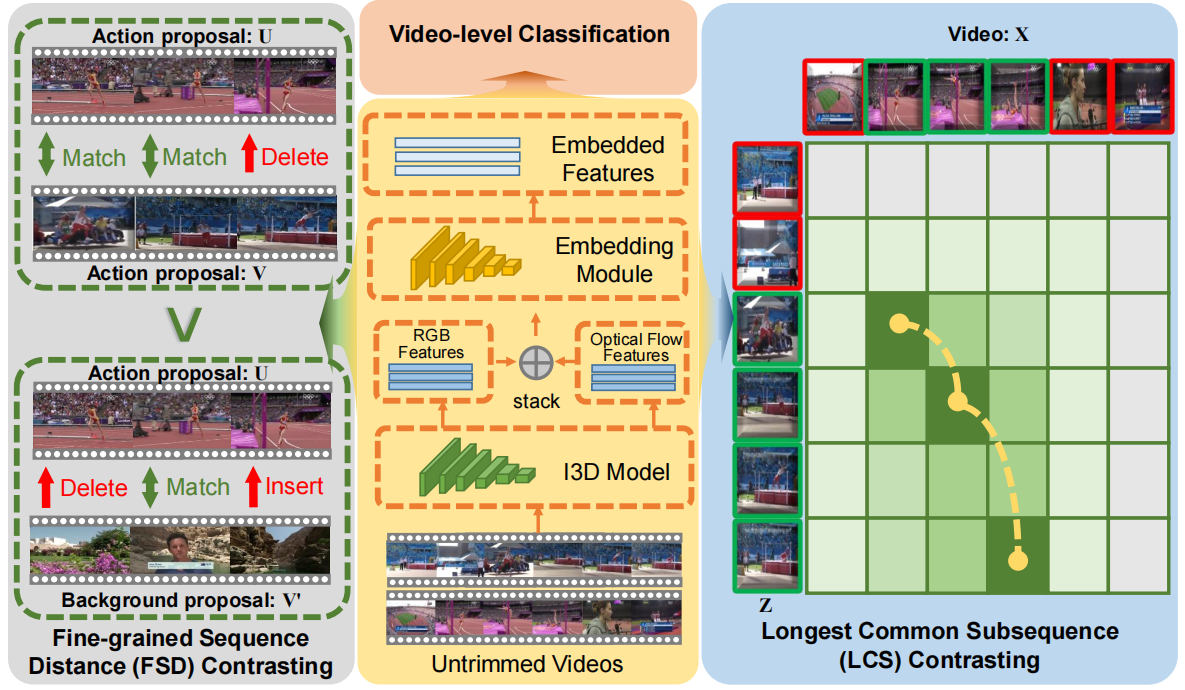
首先对输入视频采用预先训练好的I3D模型,得到RGB和光流特征。然后利用嵌入模块在视频级监督下提取片段级特征。再经过两个左右两种方法进行优化。
搜索
复制
最新文章
- DTO – 服务实现中的核心数据
- SSH ProxyCommand
- php入门一ubuntu16.04中php环境配置及一个网页
- 让JavaScript回归函数式编程的本质
- socket 连接,使得地址马上可以重用
- Altium快捷键
- webApp禁止用户保存图像
- BNU Questions and answers
- Maven插件之portable-config-maven-plugin(不同环境打包)
- EasyUI初体验--右键弹框
- JSON数据解析及gson.jar包
- 【Sqlserver系列】初级思维导图
- Dynamics CRM2013 Form利用window.location.reload()进行全局刷新带来的问题及解决办法
- python获取文件所在目录
- react native进一步学习(NavigatorIOS 学习)
- MySQL 多表结构的创建与分析
- python--私有属性--私有方法
- PHP5.4.0新特性研究
- XML外部实体注入漏洞(XXE)
- Qt__绘制系统